原文链接:https://www.cnblogs.com/pingguo-softwaretesting/p/14953993.html
一、什么是 MQ
百度百科:MQ(Message Queue)消息队列,是基础数据结构中“先进先出”的一种数据结构。
指把要传输的数据(消息)放在队列中,用队列机制来实现消息传递。生产者产生消息并把消息放入队列,然后由消费者去处理。消费者可以到指定队列拉取消息,或者订阅相应的队列,由MQ服务端给其推送消息。
工作中常被用于上下游传递消息,实现一种跨进程的通信。这样一来,要发送消息的上游服务只依赖 MQ 即可,与下游服务解耦,我觉得可以理解成中介。
二、MQ 的作用
消息队列中间件是分布式系统中重要的组件,主要解决应用解耦,异步消息,流量削锋等问题,实现高性能,高可用,可伸缩和最终一致性架构。
- 流量削峰
削峰:高并发情况下,业务异步处理,提供高峰期业务处理能力,避免系统瘫痪。
举个栗子,这里有一个订单系统处理用户下单的业务逻辑。这个系统的服务能力假设为 1S 处理1万次订单,那么正常来说,不超过1万次对它来说都没问题。但是,如果到了用户下单的高峰期,这时候的单量可能就要超过系统服务能力。
这时候可以加入 MQ,把1s内下的订单进行排队,分散在一段时间内处理,虽然说会导致有些用户会在几秒之后才能收到下单成功,但是比起不能下单还是要好很多了。
- 应用解耦
解耦:一个业务需要多个模块共同实现,或者一条消息有多个系统需要对应处理,只需要主业务完成以后,发送一条MQ,其余模块消费MQ消息,即可实现业务,降低模块之间的耦合。
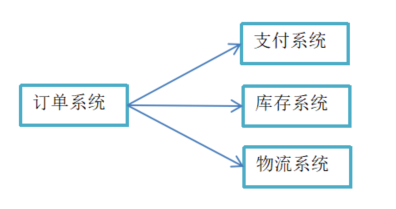
现在有个电商应用,里面包含了好多个子系统:订单系统、库存系统、物流系统、支付系统等。
先看下耦合在一起的情况,当用户创建订单后,如果后面任何一个子系统出现了故障,都会造成用户的下单操作异常。
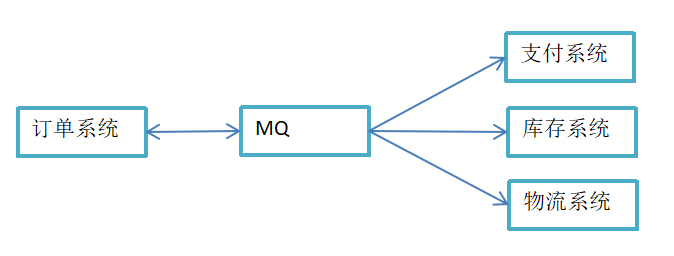
现在加上 MQ 后,订单系统的工作完成后,接下来的事情就转交给MQ了。MQ 会分配消息给其他的3个系统,直到3个系统执行完成。如果存在其中有不能完成的系统,队列会监督它继续完成。比如物流系统坏了,但是订单系统不受影响,用户感觉不出来有异常,依旧可以看到成功下单的提示。当物流系统恢复正常以后,继续处理订单信息即可,从而提升了整个系统的可用性。
- 异步处理
异步:主业务执行结束后从属业务通过MQ,异步执行,减低业务的响应时间,提高用户体验。
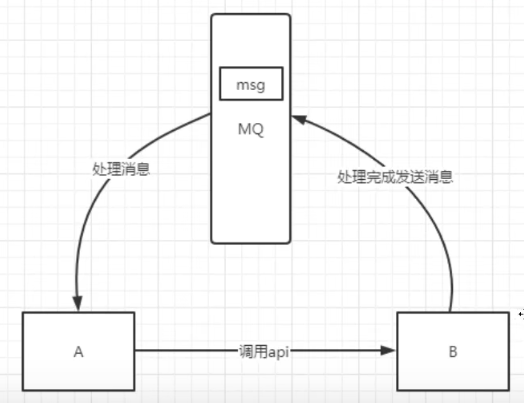
在生产中,有些服务间的调用是异步的。A 调用 B,但是 B 需要花费一段时间来处理。没有 MQ 的时候通常这样处理:
- A 轮询的调用 B的查询,看看结果是不是处理好了。A 提供一个callback 回调接口,B 执行好了调用这个api接口通知 A。
加入 MQ 后,这时 A 再调用 B 后,只需要监听 B 处理完成的消息即可。当 B 处理完成后,会发送一条消息给 MQ,然后 MQ 会把消息转发给 A。所以,现在 A 既不用轮询 B,也不用提供回调api
三、MQ 的缺点
MQ 这么好用,难道就没有缺点吗? 有。
- 在系统里加入一个中间件服务,会增加系统复杂度。需要考虑消息丢失、消息重复消费、消息传递的顺序性。
- 如果 MQ 宕机了,不能用了,那么后面的流程也没法处理了。
- 存在业务一致性问题。比如订单系统创建好了订单,发给下游的消息没发出去,那么就产生了脏数据。再比如,先发送了订单的消息,再去创建订单,如果创建失败了,消息却发送成功了,此时下游以为已经创建好了订单。
- 其他问题,比如消息丢失,重复发送相同消息,消息被其他系统消费,消息大量积压等等,都需要我们有对应方案解决。
对于一致性问题,在 testerhome 有看到过一位大佬分享的经验:
首先,消费者在消费成功后通过同步请求或者另一条 mq 队列,反馈给生产者,生产者更新自己内部这条消息的状态为已处理。
同时生产者内置一个定时任务,查看内部所有待处理消息是否超时,如果超时,进行自动补偿。补偿大概步骤是:
- 发起 http 同步查询给消费者,确认消费者是否有消费
- 若消费者反馈已消费,直接更新生产者自身内部消息状态
- 若消费者反馈未收到,则进行预警,人工介入处理(一般不会直接重发,因为重发有可能引发更严重的问题,如加剧 mq 消息堆积的情况)
四、MQ 的组成
1、角色
- Broker:消息服务器,提供消息核心服务
- Producer:消息生产者,业务的发起方,负责生产消息传输给broker。
- Consumer:消息消费者,业务的处理方,负责从broker获取消息并进行业务逻辑处理。
- Topic:主题,发布订阅模式下的消息统一汇集地,不同生产者向topic发送消息,由MQ服务器分发到不同的订阅者,实现消息的广播。
- Queue:队列,点对点模式下,特定生产者向特定queue发送消息,消费者订阅特定的queue完成指定消息的接收。
- Message:消息体,根据不同通信协议定义的固定格式进行编码的数据包,来封装业务数据,实现消息的传输。
2、MQ 消息模式
1)点对点模式
使用 queue 作为通信载体,消息生产者生产消息发送到 queue 中,然后消息消费者从 queue 中取出并且消费消息。
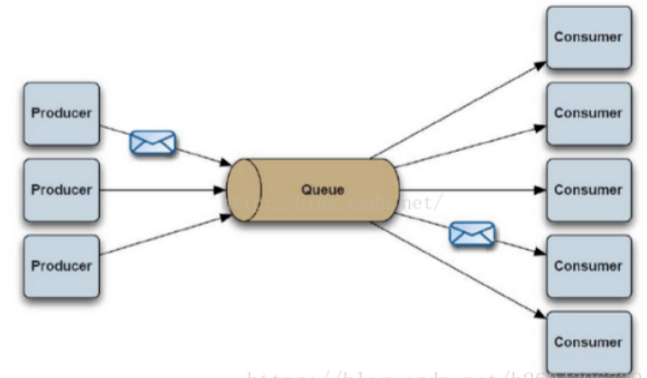
消息被消费以后,queue中不再存储,所以消息消费者不可能消费到已经被消费的消息。Queue支持存在多个消费者,但是对一个消息而言,只会有一个消费者可以消费。
2)发布订阅模式
使用topic作为通信载体,1个生产者可以对应多个消费者。消息生产者(发布)将消息发布到topic中,同时有多个消息消费者(订阅)消费该消息。和点对点方式不同,发布到topic的消息会被所有订阅者消费。
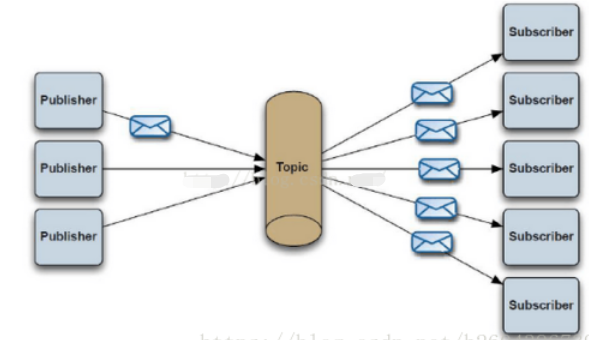
就像你发了个朋友圈,你的朋友们都可以看到。
五、常见 MQ 分类
主要的MQ产品包括:RabbitMQ、ActiveMQ、RocketMQ、Kafka、ZeroMQ、IBM WebSphere等。
1、ActiveMQ
Apache下的一个子项目。使用Java完全支持JMS1.1和J2EE 1.4规范的 JMS Provider实现,少量代码就可以高效地实现高级应用场景。
优点:
- 单机吞吐量: 万级。
- 时效性: ms级。
- 可用性:高。
- 消息可靠性:较低概率出现丢失数据。
缺点:官方社区现在对于 ActiveMQ 5.x的版本维护越来越少,高吞吐量场景较少使用。
2、Kafka
Apache下的一个子项目,使用scala实现的一个高性能分布式Publish/Subscribe消息队列系统。尤其在大数据上是个杀手锏,吞吐量在百万级,在数据采集、传输、存储的过程中发挥举足轻重的作用。
优点:
- 单机吞吐量: 百万级。
- 时效性: ms级。
- 可用性:非常高。
- 消息可靠性:可配置 0 丢失。
- 分布式:一个数据有多个副本,少数机器宕机也不会丢失数据。
缺点:单机超过64个队列/分区,CPU会明显变高,队列越多越高,发送消息响应时间变长。消费失败不支持重试。
Kafka主要特点是基于PULL的模式来处理消息消费,追求高吞吐量,一开始的目的就是用于日志收集和传输,适合产生大量数据的互联网服务的数据收集业务。
3、RocketMQ
阿里系下开源的一款分布式、队列模型的消息中间件,是阿里参照kafka设计思想使用java实现的一套MQ,并做了自己的改进。被阿里广泛的应用在订单、交易、充值、流计算、消息推送、日志流处理等场景。
优点:
- 单机吞吐量: 十万级。
- 时效性: ms级。
- 可用性:非常高。
- 消息可靠性:可配置 0 丢失。
- 分布式:支持。
- 扩展性好,支持10亿级别的消息堆积。
- 源码是java,有利于定制。
缺点:支持的语言不多,主要是java,C++还不成熟。社区活跃也一般,没有在 MQ 核心中实现 JMS 等接口,有些系统需要迁移则要修改大量代码。
RocketMQ 天生为了金融互联网而生,对于可靠性要求很高的场景,比如电商里的扣款,它更值得信赖。
4、RabbitMQ
使用Erlang编写的一个开源的消息队列,本身支持很多的协议:AMQP,XMPP, SMTP,STOMP,也正是如此,使的它变的非常重量级,更适合于企业级的开发。
优点:
- 单机吞吐量:万级。
- 时效性:μs级。
- 可用性:高。
- 消息可靠性:基本不丢失。
- 支持多语言。
- 社区活跃度高,更新频率高
缺点:商业版需要付费,学习成本较高。
RabbitMQ 性能好,时效性强,管理界面也很友好。如果数据量没那么大,中心型业务可以优先选择功能完备的 RabbitMQ。
六、MQ 测试需要的关注点
- 对于生产者
- 生成的数据格式是否跟定义的一致
- 数据是否有成功推送到队列里
- 数据是否有成功推动到对应的 topic
- 推送失败时如何处理
- 重复推送同一条数据,如何处理
- 不同顺序推送消息,注意队列优先级
- 推消息耗时,队列容量达到上限,无法推送后如何处理
- 对于消费者
- 消费的消息是否来自订阅的 topic
- 消息被消费了,是否有清除
- 生产者推送过快,消费速度过慢(堵塞),会如何
- 无法消费没订阅的 topic 消息
- 生产者推送消息后,消费者接受到的消息内容跟生产者推的一致
- 如何处理重复消息,比如幂等
- 处理超时
- 消息处理失败
- 消费消息的优先级是否跟推的一致
- 消费消息耗时
- 消费者宕机,消息堆积,无人处理,会如何处理
- 是否能正常消费消息
- 对于队列
- 宕机恢复后,消息是否丢失
- 宕机预案,多久能恢复,如果无法恢复的预案
- 不同的消息格式,是否能正常识别及转发
具体关注点,其实还要看具体业务来,这些都可以做些了解,如果有涉及到与MQ交互的,可以从多方面去考虑,增加测试覆盖。
最后本文参考文章:
https://testerhome.com/articles/30382
https://blog.csdn.net/wender/article/details/86317970
https://www.baidu.com/