增强学习与马尔科夫决策过程
2015年11月17日写在前面
现有的机器学习算法根据模型的学习过程大致可以分为四类:监督式学习,无监督式学习,半监督式学习和增强学习。监督式学习是从标记好的训练数据中进行模型的训练,常用来做分类和回归,例如逻辑回归、反向神经网络;无监督式学习是根据数据的特征直接对数据的结构和数值进行归纳,常用来做聚类,例如周知的K-均值,谱聚类;半监督式学习是根据部分标记的和部分没有标记的训练数据进行模型的学习,常用来做回归和分类;增强学习,作为今天要讨论的主角,是机器学习中最酷的分支之一,其通过不断的试错、反馈进行学习,常用来做序列决策或者控制问题,例如Q-Learning、TD-Learning。
增强学习和人类学习的机制非常相近,在实际应用中也有这很Cool的表现,如直升机自动飞行、各种通过增强学习实现的打败人类最强选手的棋牌博弈机器,包括最近非常火的DeepMind将深度学习和增强学习融合实现的玩Atari游戏的超强程序。下面将结合一个实例,从增强学习的数学本质——马尔科夫决策过程进行阐述。
一个栗子
下面是摘自《人工智能:一种现代方法》中的一个例子:
假设一个智能体处于下图(a)中所示的4x3的环境中。从初始状态开始,它需要每个时间选择一个行动(上、下、左、右)。在智能体到达标有+1或-1的目标状态时与环境的交互终止。如果环境是确定的,很容易得到一个解:[上,上,右,右,右]。可惜智能体的行动不是可靠的(类似现实中对机器人的控制不可能完全精确),环境不一定沿这个解发展。下图(b)是一个环境转移模型的示意,每一步行动以0.8的概率达到预期,0.2的概率会垂直于运动方向移动,撞到(a)图中黑色模块后会无法移动。两个终止状态分别有+1和-1的回报,其他状态有-0.4的回报。现在智能体要解决的是通过增强学习(不断的试错、反馈、学习)找到最优的策略(得到最大的回报)。
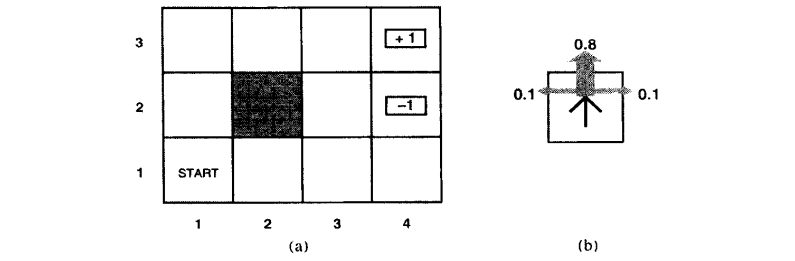
上述问题可以看作为一个马尔科夫决策过程,最终的目标是通过一步步决策使整体的回报函数期望最优。下面介绍马尔科夫决策过程。
马尔科夫决策过程
一个马尔科夫决策过程(Markov Decision Processes, MDP)有一个五个关键元素组成{S,A,{Psa},γ,R}{S,A,{Psa},γ,R},其中:
SS:表示状态集合,例如上例中4x3的每个环境{(i,j)|i=1,2,3,4,j=1,2,3}{(i,j)|i=1,2,3,4,j=1,2,3}。自动直升机系统中的所有可能的位置、方向等。
AA:表示一组动作集合,例如上例中的(上、下、左、右),自动直升机系统中的让飞机向前,向后等。
PsaPsa:状态转移概率,表示在当前s∈Ss∈S状态下,通过执行动作a∈Aa∈A后转移到其他状态的概率分布。例如上例中,P(1,1)上P(1,1)上表示智能体在状态(1,1)执行向上的动作后转移到状态(1,2),(2,1)的概率分布。
γ∈[0,1)γ∈[0,1):阻尼系数,表示的是随着时间的推移回报率的折扣。
R:S×A↦RR:S×A↦R:回报函数,有时回报函数是只与SS有关的函数,RR重写为R:S↦RR:S↦R。相当于上例中对每个状态上赋予的回报值。
MDP的动态过程如下:智能体在状态s0s0选择某个动作a0∈Aa0∈A,智能体根据概率Ps0a0Ps0a0转移到状态s1s1,然后执行动作a1a1,...如此下去我们可以得到这样的过程:
s0a0⟶s1a1⟶s2a2⟶s3a3⟶⋅⋅⋅s0⟶a0s1⟶a1s2⟶a2s3⟶a3···
经过上面的转移路径,我们可以得到相应的回报函数和如下:
R(s0,a0)+γR(s1,a1)+γ2R(s2,a2)+⋅⋅⋅R(s0,a0)+γR(s1,a1)+γ2R(s2,a2)+···
如果回报函数RR只与SS有关,我们上式可重新写作
R(s0)+γR(s1)+γ2R(s2)+⋅⋅⋅R(s0)+γR(s1)+γ2R(s2)+···
我们的目标是选择一组最佳的动作,使得全部的回报加权和期望最大:
Reward=E[R(s0)+γR(s1)+γ2R(s2)+⋅⋅⋅]Reward=E[R(s0)+γR(s1)+γ2R(s2)+···]
从上式可以发现,在t时刻的回报值是被打了γtγt倍折扣的,注意到γ<1γ<1,则越靠后的状态对回报和影响越小,为了得到最大期望回报,智能体将会尽量最先拿最大回报。
下图是上述内容的一个直观示意
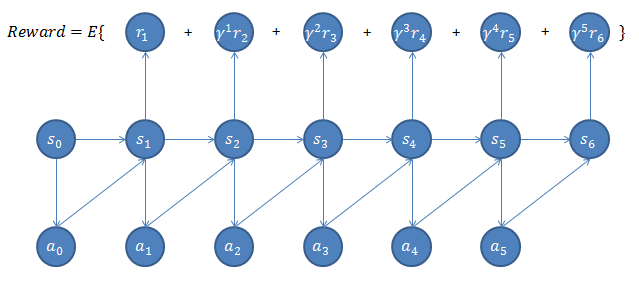
下一部分将对上述过程进行进一步数学表示,以方便求解。
进一步数学表示
首先我们来定义策略,一个策略ππ就是一个从状态到动作的映射函数π:S↦Aπ:S↦A。也就是,给定了当前状态ss,根据策略ππ,也就确定了下一步应该执行的动作a=π(s)a=π(s)。
为每一个策略ππ我们顶一个相应的值函数(Value Function)
Vπ(s)=E[R(s0)+γR(s1)+γ2R(s2)+⋅⋅⋅|s0=s,π]Vπ(s)=E[R(s0)+γR(s1)+γ2R(s2)+···|s0=s,π]
即给定初始状态s0s0和策略ππ后的累积折扣回报期望(Expected Sum Of Discounted Rewards)。
对于一个固定的策略,它的值函数VπVπ满足贝尔曼等式(Bellman Equations):
Vπ(s)=R(s)+γ∑s′∈SPsπ(s)(s′)Vπ(s′)Vπ(s)=R(s)+γ∑s′∈SPsπ(s)(s′)Vπ(s′)
其中s′s′表示状态ss执行动作π(s)π(s)后的下一个可能状态,其服从Psπ(s)Psπ(s)分布。上式由两部分构成:即时回报R(s)R(s)及未来累积折扣回报期望Es′∼Psπ(s)[Vπ(s′)]Es′∼Psπ(s)[Vπ(s′)]。
利用贝尔曼等式能够有效的解出VπVπ(给定的策略ππ的回报值)。尤其,对于一个有限状态的MDP(|S|<∞|S|<∞),对每一个状态ss我们都能写出这样的等式Vπ(s)Vπ(s),求解变为了解一个|S||S|个方程,|S||S|个未知数的线性方程组。
当然,我们求解VπVπ的目的是为找到一个当前状态ss下最优的行动策略ππ服务的(最优的策略下得到最优的值函数)。定义最优的值函数为:
V∗(s)=maxπVπ(s)V∗(s)=maxπVπ(s)
其贝尔曼等式的形式为:
V∗(s)=R(s)+maxa∈Aγ∑s′∈SPsa(s′)V∗(s′)V∗(s)=R(s)+maxa∈Aγ∑s′∈SPsa(s′)V∗(s′)
也可表示为增强学习中的Q函数形式:
V∗(s)=maxaQ(s,a)V∗(s)=maxaQ(s,a)
其中Q(s,a)≡R(S)+γPsa(s′)V∗(s′)Q(s,a)≡R(S)+γPsa(s′)V∗(s′),表示在ss状态下执行动作aa作为第一个动作时的最大累计折扣回报。
对应最优值函数的最优的策略为:
π∗(s)=argmaxa∈A∑s′∈SPsa(s′)V∗(s′)π∗(s)=argmaxa∈A∑s′∈SPsa(s′)V∗(s′)
需要注意的是,π∗π∗有一个有趣的特性,即π∗π∗是针对的是所有的状态ss的,确定了每一个状态ss的下一个动作aa,不管初始状态是哪一个状态,通过策略π∗π∗都会取得最大回报。
现在我们有了优化目标的数学表达(最优值函数,最优策略),下一部分讨论两种求解方法(针对有限状态、有限动作的MDP)。
值迭代方法和策略迭代方法
值迭代方法
算法步骤:
1 将每一个状态ss的值函数V(s)V(s)初始化为0
2 循环直至收敛{
对于每一个状态ss,对V(s)V(s)做更新
V(s):=R(s)+maxa∈Aγ∑s′V(s′)V(s):=R(s)+maxa∈Aγ∑s′V(s′)
}
值迭代方法里面的内循环又有两种策略:同步迭代,异步迭代。同步迭代就是得到V(s)V(s)后不立即更新,等所有的状态ss的V(s)V(s)都完成计算后统一更新。异步迭代就是对每个状态ss得到新的V(s)V(s)后立即更新。两种都会使得V(s)V(s)收敛于V∗(s)V∗(s)。求得最优的V∗(s)V∗(s)后,可使用公式π∗(s)=argmaxa∈A∑s′∈SPsa(s′)V∗(s′)π∗(s)=argmaxa∈A∑s′∈SPsa(s′)V∗(s′)来求出相应的最优策略π∗π∗。
策略迭代方法
于值迭代方法不同,策略迭代法之间关注ππ,使ππ收敛到π∗π∗。
算法步骤:
1 随机初始化话一个SS到AA的映射ππ
2 循环直至收敛{
2.1 令V:=VπV:=Vπ
2.2 对每一个状态s,对π(s)π(s)做更新
π(s):=argmaxa∈A∑s′Psa(s′)V(s′)π(s):=argmaxa∈A∑s′Psa(s′)V(s′)
}
其中2.1步即为上述对于一个给定策略ππ利用贝尔曼等式求解VπVπ的过程(求解|S||S|个方程,|S||S|个未知数的线性方程组)。
2.2是根据2.1步的结果,挑选出当前状态ss下最优的动作aa来更新π(s)π(s)。
两者比较
对于规模较小的MDP,策略迭代一般能够更快的收敛;但对于规模较大的MDP(状态多),值迭代更容易些(没有线性方程组的计算)。
MDP中的参数估计
到目前为止,我们讨论的MDP和MDP求解算法都是在已知状态转移概率PsaPsa和回报函数R(s)R(s)的。在许多实际问题中,状态转移概率和回报函数不能显式的得到,本部分讲如何从数据中估计这些参数(通常S,A,γS,A,γ是已知的)。
假设我们已知很多条状态转移路径如下:
s(1)0a(1)0⟶s(1)1a(1)1⟶s(1)2a(1)2⟶s(1)3a(1)3⟶⋅⋅⋅s0(1)⟶a0(1)s1(1)⟶a1(1)s2(1)⟶a2(1)s3(1)⟶a3(1)···
s(2)0a(2)0⟶s(2)1a(2)1⟶s(2)2a(2)2⟶s(2)3a(2)3⟶⋅⋅⋅s0(2)⟶a0(2)s1(2)⟶a1(2)s2(2)⟶a2(2)s3(2)⟶a3(2)···
⋅⋅⋅···
其中s(j)isi(j)是ii时刻第jj条转移路径对应的状态,ajiaij是sjisij状态要执行的动作。每条转移路径中的状态数都是有限的,在实际操作中每个转移路径要么进入终结状态,要不达到规定的步数后终结。
当我们获得了很多类似上面的转移路径后(样本),我们可以用最大似然估计来估计状态转移概率。
Psa(s′)=#times took we action a in state s and got to s′#times we took action a in state sPsa(s′)=#times took we action a in state s and got to s′#times we took action a in state s
上式分子表示在状态ss通过执行动作aa后到达状态s′s′的次数,分母表示在状态ss我们执行动作的次数。为避免分母为0的情况,当分母为0使,令Psa(s′)=1|S|Psa(s′)=1|S|。
对于未知的回报函数,我们令R(s)R(s)为在状态ss下观察到的回报均值。
得到状态转移概率和回报函数的估值后,就简化为了前面部分讲述的问题,用第三部分将的值迭代或者策略迭代方法即可解决。例如我们将值迭代和参数估计结合到一块:
算法流程如下:
1 随机初始化话一个SS到AA的映射ππ
2 循环直至收敛{
2.1 在MDP中执行策略ππ一定次数
2.2 通过2.1得到的样本估计PsaPsa(和RR,需要的话)
2.3 使用上一节提到的值迭代方法和估计得到的参数来更新VV
2.4 对于得到的VV更新得到更优的策略ππ
}
其中2.3步,是一个循环迭代的过程。上一节中我们通过将VV初始化为0然后进行迭代,当嵌套上述过程中后,如果每次都将VV初始化为0然后迭代更新,速度回很慢。一个加速的方法是将VV初始化我上次大循环中得到的VV。
小结
至此我们讨论完了增强学习的数学本质—马尔科夫决策过程(MDP)的数学表示及求解过程(这里的MDP是非确定的MDP,即状态转移函数和回报函数是有概率的,,对于确定性的,求解会更简单些,感兴趣可参考[3]最后一章:增强学习)。全文很大部分是对Andrew Ng讲义[1]的翻译,加上了部分自己的理解。推荐大家根据参考文献进行进一步理解和学习。
参考文献
[1] 机器学习公开课-讲义-马尔科夫决策过程.Andrew Ng
[2] 机器学习公开课-视频-马尔科夫决策过程.Andrew Ng
[3] 人工智能:一种现代方法
[4] 机器学习.Tom M.Mitchell
版权声明:本文为博主原创文章,转载请注明出处。