几个重要的网站
MongoDB官方网站:https://www.mongodb.com
MongoDB国内官方网站:http://www.mongodb.org.cn/
教程:http://www.runoob.com/mongodb/mongodb-tutorial.html
视频教程:http://www.icoolxue.com/album/show/98
http://www.imooc.com/video/5942
| SQL术语/概念 | MongoDB术语/概念 | 解释/说明 |
|---|---|---|
| database | database | 数据库 |
| table | collection | 数据库表/集合 |
| row | document | 数据记录行/文档 |
| column | field | 数据字段/域 |
| index | index | 索引 |
| table joins | 表连接,MongoDB不支持 | |
| primary key | primary key | 主键,MongoDB自动将_id字段设置为主键 |
数据库名
数据库也通过名字来标识。数据库名可以是满足以下条件的任意UTF-8字符串。
- 不能是空字符串("")。
- 不得含有' '(空格)、.、$、/、和� (空字符)。
- 应全部小写。
- 最多64字节。
- 数据库名不能与现有系统保留库同名,如admin,local,及config
这样的集合名字也是合法的
db-text但是不能通过db.documentName得到了
要改为db.getCollection(documentName)
因为db-text会被当是减法操作
1、创建数据库
1)use DATABASE_NAME :如果数据库不存在,则创建数据库,否则切换到指定数据库。例子:use footar
2)查看所有数据库:show dbs;可以显示所有数据的列表
3)我们刚创建的数据库footar并不在数据库的列表中, 要显示它,我们需要向 footar数据库插入一些数据。
db.footar.insert({"name":"教程"})
MongoDB 中默认的数据库为 test,如果你没有创建新的数据库,集合将存放在 test 数据库中。
2、删除数据库
1)db.dropDatabase():删除当前数据库,默认为 test,你可以使用 db 命令查看当前数据库名。
2)db.collection.drop():删除集合
例子 use mwxq
db.footar.drop()
3、插入文档
文档的数据结构和JSON基本一样。
所有存储在集合中的数据都是BSON格式。
BSON是一种类json的一种二进制形式的存储格式,简称Binary JSON。
MongoDB 使用 insert() 或 save() 方法向集合中插入文档,语法如下:
db.COLLECTION_NAME.insert(document)
例子1: db.persons.insert({name:"uspact"}) //双引号,单引号我试了都可以。
例子2:
db.person1.insert(
{title:'教程',
description:'解释',
tags:['mongodb','database','NoSql']
})
例子3:我们也可以将数据定义为一个变量
document=({title: 'MongoDB 教程',
description: 'MongoDB 是一个 Nosql 数据库',
by: '菜鸟教程',
url: 'http://www.runoob.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100
});
db.person1.insert(document)
以上实例中 person1、persons 是我们的集合名,如果该集合不在该数据库中, MongoDB 会自动创建该集合并插入文档。
插入文档你也可以使用 db.col.save(document) 命令。如果不指定 _id 字段 save() 方法类似于 insert() 方法。如果指定 _id 字段,则会更新该 _id 的数据。
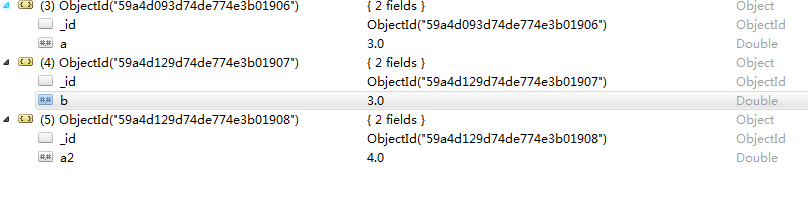
- db.collection.insertOne():向指定集合中插入一条文档数据:db.collection.insertOne({"a": 3})
- db.collection.insertMany():向指定集合中插入多条文档数据:db.items.insertMany([{"b":3},{"a2":4}])
结果如下:
4 、更新文档
MongoDB 使用 update() 和 save() 方法来更新集合中的文档。接下来让我们详细来看下两个函数的应用及其区别。
1)update()方法
update() 方法用于更新已存在的文档。语法格式如下:
db.collection.update(
<query>,
<update>,
{
upsert: <boolean>,
multi: <boolean>,
writeConcern: <document>
}
)
参数说明:
- query : update的查询条件,类似sql update查询内where后面的。
- update : update的对象和一些更新的操作符(如$,$inc...)等,也可以理解为sql update查询内set后面的
- upsert : 可选,这个参数的意思是,如果不存在update的记录,是否插入objNew,true为插入,默认是false,不插入。
- multi : 可选,mongodb 默认是false,只更新找到的第一条记录,如果这个参数为true,就把按条件查出来多条记录全部更新。
- writeConcern :可选,抛出异常的级别。
例子1:var p=db.persons.findOne()
db.persons.update(p,{name :"uspcat"})
例子2:db.persons.update({name:"extjs4.0"},{$set:{name:"extjs4.1"}})
以上语句只会修改第一条发现的文档,如果你要修改多条相同的文档,则需要设置 multi 参数为 true。
例子3:db.persons.update({'title':'MongoDB 教程'},{$set:{'title':'MongoDB'}},{multi:true})
2)save() 方法
save() 方法通过传入的文档来替换已有文档。语法格式如下:
db.collection.save(
<document>,
{
writeConcern: <document>
}
)
参数说明:
- document : 文档数据。
- writeConcern :可选,抛出异常的级别。
例子
以下实例中我们替换了 _id 为 59a4b9d4d74de774e3b018f7的文档数据:
db.person1.save({
"_id":ObjectId("59a4b9d4d74de774e3b018f7"),
"title":"MongoDBCS",
"dE":"11",
"tag2":["11","22"]
})
更多实例
只更新第一条记录:
全部更新:
只添加第一条:
全部添加加进去:
全部更新:
只更新第一条记录:
5、删除文档
MongoDB remove()函数是用来移除集合中的数据。
在执行remove()函数前先执行find()命令来判断执行的条件是否正确,这是一个比较好的习惯。
db.collection.remove(
<query>,
{
justOne: <boolean>,
writeConcern: <document>
}
)
参数说明:
- query :(可选)删除的文档的条件。
- justOne : (可选)如果设为 true 或 1,则只删除一个文档。
- writeConcern :(可选)抛出异常的级别
例子1:db.persons.remove({name:'uspcat'})
例子2 :db.items.remove({'name':'测试'},{justOne:1}) //删除一条
例子3;db.col.remove({}) //删除所有
6、查询文档
MongoDB 查询文档使用 find() 方法。
find() 方法以非结构化的方式来显示所有文档。
db.collection.find(query, projection)
- query :可选,使用查询操作符指定查询条件
- projection :可选,使用投影操作符指定返回的键。查询时返回文档中所有键值, 只需省略该参数即可(默认省略)。
如果你需要以易读的方式来读取数据,可以使用 pretty() 方法,语法格式如下:
db.col.find().pretty()
pretty() 方法以格式化的方式来显示所有文档。
除了 find() 方法之外,还有一个 findOne() 方法,它只返回一个文档。
例子1:db.persons.findOne()
例子2:db.persons.find()
MongoDB 与 RDBMS Where 语句比较
如果你熟悉常规的 SQL 数据,通过下表可以更好的理解 MongoDB 的条件语句查询:
| 操作 | 格式 | 范例 | RDBMS中的类似语句 |
|---|---|---|---|
| 等于 | {<key>:<value>} |
db.col.find({"by":"菜鸟教程"}).pretty() |
where by = '菜鸟教程' |
| 小于 | {<key>:{$lt:<value>}} |
db.col.find({"likes":{$lt:50}}).pretty() |
where likes < 50 |
| 小于或等于 | {<key>:{$lte:<value>}} |
db.col.find({"likes":{$lte:50}}).pretty() |
where likes <= 50 |
| 大于 | {<key>:{$gt:<value>}} |
db.col.find({"likes":{$gt:50}}).pretty() |
where likes > 50 |
| 大于或等于 | {<key>:{$gte:<value>}} |
db.col.find({"likes":{$gte:50}}).pretty() |
where likes >= 50 |
| 不等于 | {<key>:{$ne:<value>}} |
db.col.find({"likes":{$ne:50}}).pretty() |
where likes != 50 |
MongoDB AND 条件
MongoDB 的 find() 方法可以传入多个键(key),每个键(key)以逗号隔开,及常规 SQL 的 AND 条件。
语法格式如下:
db.col.find({key1:value1, key2:value2}).pretty()
例子:db.items.find({name:'测试',address:'333'}).pretty()
MongoDB OR 条件
MongoDB OR 条件语句使用了关键字 $or,语法格式如下:
>db.col.find(
{
$or: [
{key1: value1}, {key2:value2}
]
}
).pretty()
例子:db.items.find({$or:[{name:'测试'},{name:'3'}]}).pretty()
AND 和 OR 联合使用
例子
db.items.find({'address':'4',$or:[{name:'测试'},{name:'3'}]}).pretty()
7、MongoDB条件操作符
条件操作符用于比较两个表达式并从mongoDB集合中获取数据。
MongoDB中条件操作符有:
- (>) 大于 - $gt
- (<) 小于 - $lt
- (>=) 大于等于 - $gte
- (<= ) 小于等于 - $lte
MongoDB (>) 大于操作符 - $gt
集合中大于 100 的数据
db.person1.find({"likes":{$gt:100}}).pretty()
MongoDB(>=)大于等于操作符 - $gte
集合中 "likes" 大于等于 100 的数据
db.person1.find({"likes":{$gte:100}}).pretty()
MongoDB (<) 小于操作符 - $lt
集合中 "likes" 小于 150 的数据
db.person1.find({likes : {$lt : 150}})
MongoDB (<=) 小于操作符 - $lte
获取"col"集合中 "likes" 小于等于 150 的数据
db.col.find({likes : {$lte : 150}})
MongoDB 使用 (<) 和 (>) 查询 - $lt 和 $gt
db.person1.find({"likes":{$lt:200,$gt:100}}).pretty()
类似于SQL语句:
Select * from col where likes>100 AND likes<200;
$gt -------- greater than >
$gte --------- gt equal >=
$lt -------- less than <
$lte --------- lt equal <=
$ne ----------- not equal !=
$eq -------- equal =
8、MongoDB $type 操作符
$type操作符是基于BSON类型来检索集合中匹配的数据类型,并返回结果。
| 类型 | 数字 | 备注 |
|---|---|---|
| Double | 1 | |
| String | 2 | |
| Object | 3 | |
| Array | 4 | |
| Binary data | 5 | |
| Undefined | 6 | 已废弃。 |
| Object id | 7 | |
| Boolean | 8 | |
| Date | 9 | |
| Null | 10 | |
| Regular Expression | 11 | |
| JavaScript | 13 | |
| Symbol | 14 | |
| JavaScript (with scope) | 15 | |
| 32-bit integer | 16 | |
| Timestamp | 17 | |
| 64-bit integer | 18 | |
| Min key | 255 | Query with -1. |
| Max key | 127 |
MongoDB 操作符 - $type 实例
如果想获取 "person1" 集合中 title 为 String 的数据,你可以使用以下命令:
db.person1.find({'title':{$type : 2 }})
9、MongoDB Limit与Skip方法
MongoDB Limit() 方法
如果你需要在MongoDB中读取指定数量的数据记录,可以使用MongoDB的Limit方法,limit()方法接受一个数字参数,该参数指定从MongoDB中读取的记录条数。
db.COLLECTION_NAME.find().limit(NUMBER)
显示查询文档中的两条记录:
db.person1.find({},{"title":1,_id:0}).limit(2)
- 第一个 {} 放 where 条件,为空表示返回集合中所有文档。
- 第二个 {} 指定那些列显示和不显示 (0表示不显示 1表示显示)。
注:如果你们没有指定limit()方法中的参数则显示集合中的所有数据。
MongoDB Skip() 方法
我们除了可以使用limit()方法来读取指定数量的数据外,还可以使用skip()方法来跳过指定数量的数据,skip方法同样接受一个数字参数作为跳过的记录条数。
db.COLLECTION_NAME.find().limit(NUMBER).skip(NUMBER)
db.person1.find({},{"title":1,_id:0}).limit(1).skip(1)//以下实例只会显示第二条文档数据
db.COLLECTION_NAME.find().skip(10).limit(100)//10条后100条
注:skip()方法默认参数为 0 。
当查询时同时使用sort,skip,limit,无论位置先后,最先执行顺序 sort再skip再limit。
10、MongoDB 排序
MongoDB sort()方法
在MongoDB中使用使用sort()方法对数据进行排序,sort()方法可以通过参数指定排序的字段,并使用 1 和 -1 来指定排序的方式,其中 1 为升序排列,而-1是用于降序排列。
db.COLLECTION_NAME.find().sort({KEY:1})
以下实例演示了person1集合中的数据按字段 likes 的降序排列
db.person1.find({},{"title":1}).sort({"likes":-1})
11、MongoDB 索引
索引通常能够极大的提高查询的效率,如果没有索引,MongoDB在读取数据时必须扫描集合中的每个文件并选取那些符合查询条件的记录。
这种扫描全集合的查询效率是非常低的,特别在处理大量的数据时,查询可以要花费几十秒甚至几分钟,这对网站的性能是非常致命的。
索引是特殊的数据结构,索引存储在一个易于遍历读取的数据集合中,索引是对数据库表中一列或多列的值进行排序的一种结构
ensureIndex() 方法
MongoDB使用 ensureIndex() 方法来创建索引。
db.COLLECTION_NAME.ensureIndex({KEY:1})
语法中 Key 值为你要创建的索引字段,1为指定按升序创建索引,如果你想按降序来创建索引指定为-1即可。
db.col.ensureIndex({"title":1,"description":-1})
ensureIndex() 接收可选参数,可选参数列表如下:
| Parameter | Type | Description |
|---|---|---|
| background | Boolean | 建索引过程会阻塞其它数据库操作,background可指定以后台方式创建索引,即增加 "background" 可选参数。 "background" 默认值为false。 |
| unique | Boolean | 建立的索引是否唯一。指定为true创建唯一索引。默认值为false. |
| name | string | 索引的名称。如果未指定,MongoDB的通过连接索引的字段名和排序顺序生成一个索引名称。 |
| dropDups | Boolean | 在建立唯一索引时是否删除重复记录,指定 true 创建唯一索引。默认值为 false. |
| sparse | Boolean | 对文档中不存在的字段数据不启用索引;这个参数需要特别注意,如果设置为true的话,在索引字段中不会查询出不包含对应字段的文档.。默认值为 false. |
| expireAfterSeconds | integer | 指定一个以秒为单位的数值,完成 TTL设定,设定集合的生存时间。 |
| v | index version | 索引的版本号。默认的索引版本取决于mongod创建索引时运行的版本。 |
| weights | document | 索引权重值,数值在 1 到 99,999 之间,表示该索引相对于其他索引字段的得分权重。 |
| default_language | string | 对于文本索引,该参数决定了停用词及词干和词器的规则的列表。 默认为英语 |
| language_override | string | 对于文本索引,该参数指定了包含在文档中的字段名,语言覆盖默认的language,默认值为 language. |
12、MongoDB 聚合
MongoDB中聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果。有点类似sql语句中的 count(*)。
db.COLLECTION_NAME.aggregate(AGGREGATE_OPERATION)
db.col.aggregate({
$group :{_id:"$title",num_tutorial : {$sum :1}}
})
以上实例类似sql语句: select title as _id, count(*) as num_tutorial from col group by title
我们通过字段title字段对数据进行分组,并计算title字段相同值的总和。
下表展示了一些聚合的表达式:
| 表达式 | 描述 | 实例 |
|---|---|---|
| $sum | 计算总和。 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : "$likes"}}}]) |
| $avg | 计算平均值 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$avg : "$likes"}}}]) |
| $min | 获取集合中所有文档对应值得最小值。 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$min : "$likes"}}}]) |
| $max | 获取集合中所有文档对应值得最大值。 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$max : "$likes"}}}]) |
| $push | 在结果文档中插入值到一个数组中。 | db.mycol.aggregate([{$group : {_id : "$by_user", url : {$push: "$url"}}}]) |
| $addToSet | 在结果文档中插入值到一个数组中,但不创建副本。 | db.mycol.aggregate([{$group : {_id : "$by_user", url : {$addToSet : "$url"}}}]) |
| $first | 根据资源文档的排序获取第一个文档数据。 | db.mycol.aggregate([{$group : {_id : "$by_user", first_url : {$first : "$url"}}}]) |
| $last | 根据资源文档的排序获取最后一个文档数据 | db.mycol.aggregate([{$group : {_id : "$by_user", last_url : {$last : "$url"}}}]) |
管道的概念
管道在Unix和Linux中一般用于将当前命令的输出结果作为下一个命令的参数。
MongoDB的聚合管道将MongoDB文档在一个管道处理完毕后将结果传递给下一个管道处理。管道操作是可以重复的。
表达式:处理输入文档并输出。表达式是无状态的,只能用于计算当前聚合管道的文档,不能处理其它的文档。
这里我们介绍一下聚合框架中常用的几个操作:
- $project:修改输入文档的结构。可以用来重命名、增加或删除域,也可以用于创建计算结果以及嵌套文档。
- $match:用于过滤数据,只输出符合条件的文档。$match使用MongoDB的标准查询操作。
- $limit:用来限制MongoDB聚合管道返回的文档数。
- $skip:在聚合管道中跳过指定数量的文档,并返回余下的文档。
- $unwind:将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值。
- $group:将集合中的文档分组,可用于统计结果。
- $sort:将输入文档排序后输出。
- $geoNear:输出接近某一地理位置的有序文档。
1、$project实例
db.col.aggregate({
$project:{
title:1,
description:1,}
})
这样的话结果中就只还有_id,tilte和description三个字段了,默认情况下_id字段是被包含的,如果要想不包含_id话可以这样:
非0也可以进行表示显示该字段,负数也可以表示显示该字段。
1、$project实例
db.col.aggregate({
$project:{
_id:0,
title:1,
description:1,}
})
2.$match实例
db.col.aggregate([
{$match : {likes :{ $gte : 100,$lt:200}}
},
{$group :{_id:"$title",count : { $sum :1}}
}])
$match用于获取likes 大于等于100小于或等于200记录,然后将符合条件的记录送到下一阶段$group管道操作符进行处理。
3.$skip实例
db.col.aggregate({
$skip :2
})
经过$skip管道操作符处理后,前2个文档被"过滤"掉。
13、Shell
1)help:里面所有的shell可以完成的命令帮助
全局的help数据库相关的db.help()集合相关的db.documentName.help()
2)mongoDB的shell内置javascript引擎可以直接执行JS代码
function insert(object){
db.getCollection("db-text").insert(object)
}
insert({age:32})//调用上面的函数
shell 可以用eval
db.eval("return' upspcat' ")
14、BSON是json的扩展新增了诸如日期,浮点等json不支持数据