1 JML语言的理论基础及应用工具链
1.1 JML语言
Java建模语言(JML)是一种行为接口规范语言,可用于指定Java模块的行为。它结合了Eiffel的“契约设计(design by contract)”方法和Larch系列接口规范语言的基于模型的规范方法,以及细化演算的一些元素。对JML语言起到理论支撑作用的文章主要是以下三篇:
- Leavens G T, Cheon Y. Design by Contract with JML[J]. 2006. 这篇文章解释了JML语言作为一种契约设计语言的基本使用方法;
- Patrice Chalin, Joseph R. Kiniry, Gary T. Leavens, and Erik Poll. Beyond Assertions: Advanced Specification and Verification with JML and ESC/Java2. In Formal Methods for Components and Objects (FMCO) 2005, Revised Lectures, pages 342-363. Volume 4111 of Lecture Notes in Computer Science, Springer Verlag, 2006. 这篇文章包含对JML语言的解释以及对主流工具的介绍;
- Lilian Burdy, Yoonsik Cheon, David Cok, Michael Ernst, Joe Kiniry, Gary T. Leavens, K. Rustan M. Leino, and Erik Poll. An overview of JML tools and applications. International Journal on Software Tools for Technology Transfer, 7(3):212-232, June 2005. 该文章列举了当前所有已知的JML工具并相应地进行了简单介绍。
1.2 JML语言相关工具
现在已经有大量的开源和非开源的基于JML语言编写的相关工具。其中,应用相对广泛的主流工具有如下几个:
- The AspectJML tool:为Java和AspectJ做运行时检查的工具
- The jml4c tool:基于Eclipse Java编译器开发的JML语言编译器
- Sireum/Kiasan for Java:一个基于契约的自动化验证测试工具
- JMLEclipse:在Eclipse的JDT编译器基础上开发的JML工具包
- JMLUnitNG:自动化测试生成工具
- JMLOK:用随机测试检查java代码是否符合JML规格并对不一致现象给出可能的原因
2 部署JMLUnitNG并进行简要分析
JMLUnitNG是一个自动化的单元测试用例生成工具,专门为JML语言标注的Java代码而设计的。理论上,可以基于代码的JML注释来生成较为完备的测试用例。但正如讨论区里某些同学指出的,该工具并不支持JML语言中forall和exist等语法,因而对于本单元程序的帮助极为有限。下面我只对一个演示用程序做了简单的JMLUnitNG实践,更多的对于该工具的使用还有待进一步探索。
测试用源代码如下(引用自讨论区):
// demo/Demo.java
package demo;
public class Demo {
/*@ public normal_behaviour
@ ensures
esult == lhs - rhs;
*/
public static int compare(int lhs, int rhs) {
return lhs - rhs;
}
public static void main(String[] args) {
compare(114514,1919810);
}
}
在经过生成测试文件和编译两步操作后,运行结果截图如下:
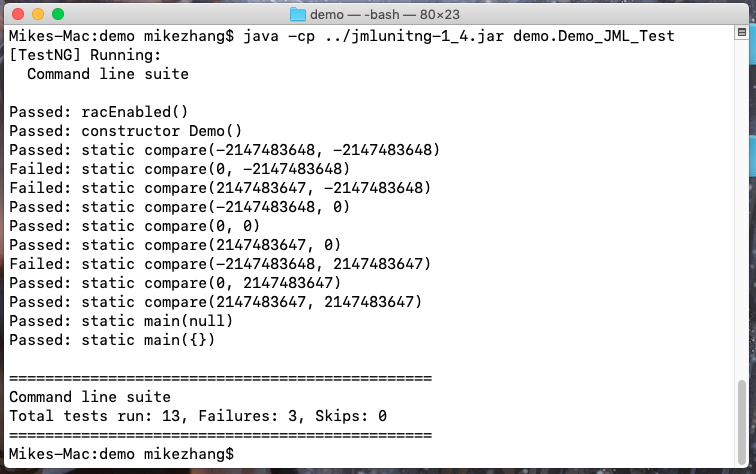
可以看出测试样例覆盖了所有的边界情况,较为详尽和完备。
3 架构设计及重构分析
3.1 第1次作业
事实上第1次作业并没有太多和架构有关的内容,它的主要目的是帮助大家熟悉JML语言并根据JML方法规格正确地写出相应的Java代码,方法的规格逻辑也都比较简单,无需复杂的架构设计。
本次作业值得一提的是两个类中的容器设计。MyPath类实现了Path接口,其中储存node的容器为整型的ArrayList;MyPathContainer类实现了PathContainer接口,其中储存path ID的容器为整型ArrayList,储存path的容器为Path类型的ArrayList。另外对于分配path ID的功能,另设一个静态成员变量pid,在每次分配path ID后自增,以确保没有两个path被分配到了相同的path ID。最后是nodeSet集合,具体是用HashSet来实现,储存的是所有path的所有节点,以便快速获取不同节点的个数。
3.2 第2次作业
第2次作业中,新的Graph接口在原来PathContainer的基础上增加了一些图相关的方法,因此需要相应地增加新的数据结构去储存这些图的信息。
最重要的问题就是用何种方法存储图。众所周知图可以分为稀疏图和稠密图,前者用邻接链表的结构存储可以最大程度地减少不必要的内存开销,后者用邻接矩阵存储可以避免通过指针访问的低效率。考虑到需求书中要求的节点数并不是很高(不超过250个),而且对操作的性能有一定要求,以及相关图算法在不同数据结构上面的实现难度,我选择了用邻接矩阵的数据结构。
具体来说有两个二维数组,edge[][]储存任意两点间连边的“个数“,供containsEdge()。举例来说,对于节点a和b,pathList中每添加一个包含边(a, b)的path,edge[][]中相应的位置就加1。第2个二维数组是len[][],储存任意两点间的最短距离,以便isConnected()和getShortestPathLength()两个方法使用。len[][]在添加和删除path的时候更新,而不是在每次查询的时候都要重复计算。需要指出的是,因为是无向图,这两个二维数组均为对称矩阵,因此所有的更新操作都要成对出现。
此外,因为path ID的范围很大,与int类型范围一致,因此还需要一个字典结构储存(path ID, index of matrix)二元组。我设置了一个名为id2Pos的HashMap,同样还是在添加和删除path的时候更新。
最后,不是矩阵里所有的位置都是有意义的,只有那些出现在id2Pos的value部分的index才是有意义的位置,因此我们还需要一个布尔类型的、长度和最大节点数(在本次作业中是250个)相同的valid[]数组来记录矩阵的哪些行和列是有意义的,对于没意义的行和列,在遍历和执行各种图算法的时候跳过(continue语句)就好。换句话来说,我们每次只用全部矩阵的一个子矩阵来作为图的表示。
3.3 第3次作业
第3次作业需要实现的功能陡然增加,导致程序的逻辑比上一次作业复杂得多,所以我对整个程序的设计做了比较大的改动和重构。第3次作业的整体结构即类图如下图所示:
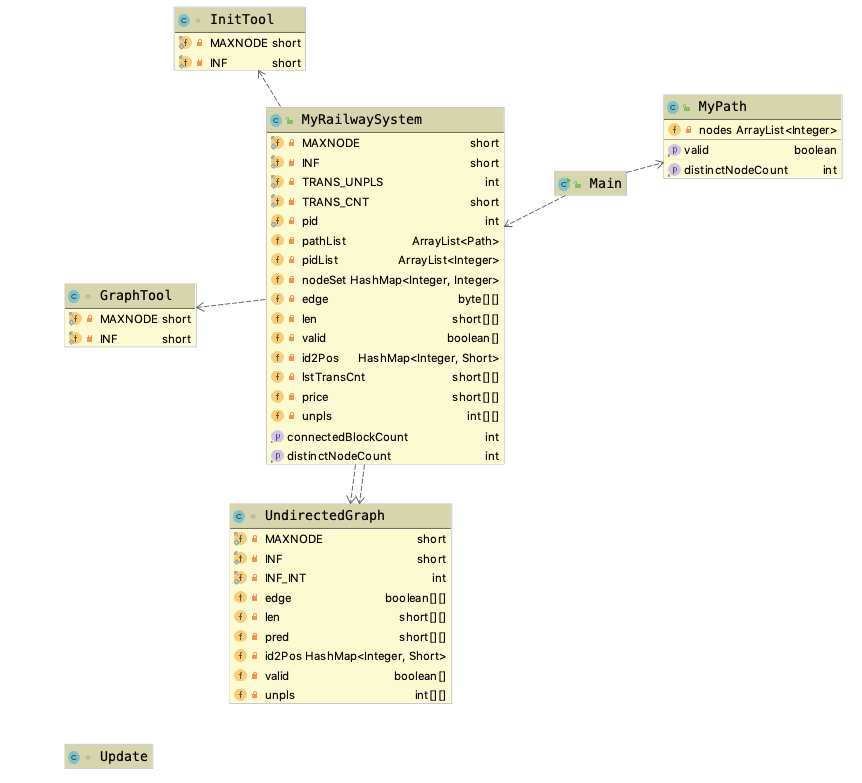
首先,我把图结构、画图、以及查询最短路径等方法独立出来,封装成了一个新的类UndirectedGraph,用来处理一切通过path建图、跑最短路径等细节事物,从而降低了系统的耦合度,让RailwaySystem类专心致力于高层逻辑。
细致分析这一次作业和上一次作业相比新增的功能,实际上我们可以把他们分成两类:新的查询方法和update()中新增的需要更新的数据(update()是每次添加或删除path后都要运行一遍的、用来更新相关数据的专用方法)。和前两次作业相似,新的查询方法并不复杂,只是检查是否满足规格中的前提条件,是否需要throws exception,并简单地读取相应的数据。复杂的是update()的部分。新增的数据包括两点间票价price[][], 两点间最少换乘次数lstTransCnt[][], 两点间最小不满意度unpls[][]和连通集数量ccNum。对于这些数据的处理,我并没有采用讨论区很多同学提到的“拆点”的做法,下面来一一介绍:
-
对于
price[][],在添加新的path时的更新分为两步:“手动”为这一条path里任意两点间赋票价,随后跑Floyd算法。我规定在同一条path内任意两点的票价为实际距离+2,这样通过Floyd算法计算出的最低票价-2即为真实的最低票价,因为实际的换乘次数=经过的path数量-1。对于删除path时的更新,把它看作将pathList剩下的path重新添加一遍。 -
对于
unpls[][],同样是这两个步骤。在第一步手动为path内两点赋值时,需要注意其值应是任意两点间的全部边的不满意度之和+32,而并不是基于这两点之间的最短路径来计算。同样地,对于删除path时的更新,把它看作将pathList剩下的path重新添加一遍。 -
对于
lstTransCnt[][]的处理,其实思路是一样的,只是改变一下两点间“距离”的定义。这里的处理稍微有些特殊,path内任意两点间的“距离”都是1+130,其中130可以替换成任意大于最大换乘数的值。如此赋的初值经过Floyd算法计算后得到的结果/130即可得到经过了几次换乘。 -
最后,对于连通集个数
ccNum,我通过多次运行深度优先搜索DFS算法,记录需要“开启”几次DFS才可以遍历完图中全部的点,从而得到连通集的数目。这样做的原因是在同一连通集内只需一次DFS递归调用便可以访问到所有的节点。
4 代码bug和修复情况
和上一单元类似,因为Java语法产生的错误和typo已经几乎为零,大部分的bug产生的原因是程序架构的错误。下面列举出破坏性最大、最严重的3处错误,与大家共勉:
第一个bug是忽视了valid[]指示数组的必要性。最开始我觉得没有必要设置这样的一个指示数组,只需保持edge[][], len[][]等矩阵里面的前n行和前n列有意义即可(n为当前不同的节点数),这样可以通过如下的方式遍历矩阵:
for (int i = 0; i < getDistinctNodeCount(); i++) {
......
}
然而实际情况却是,可以通过删掉某些path,使得上述的那些矩阵中有意义的行列交错分布。如果还按照上面代码的方法遍历就会读到一些没有意义的值,让程序进入不可预测的状态。在增设了valid[]数组之后,正确的遍历各个矩阵的人方式如下:
for (int i = 0; i < MAXNODE; i++) {
if (!valid[i]) {
continue;
}
......
}
第二个bug出现在最短路径算法的实现中。大家都知道,Dijkstra算法中最内层是一个判断语句+松弛操作(relax)。这两个语句均需要用到u, v两点的边权,而我在实现的时候为了简单和性能直接把边权硬编码成了1,这样的做法在计算票价矩阵是不存在任何问题,因为票价本身也是这么算的(即每通过一条边票价+1),但是在计算最小不满意度矩阵时就会出现问题,因为票价最低路线不一定和最小不满意度路线是同一条。后来对于不满意度问题,我转而使用了两层Floyd算法。内层的Floyd算法的输入是同一条path内相邻的点间的不满意度,算法的输出是同一条path内任意两点的不满意度;外层的Floyd算法继续“接力“,并输出全图任意两点的不满意度。对于不满意度的图画图方法如下,需要指出的是,这里的不满意度矩阵是两点间真实的不满意度,并不是如上文提到的计算方法那样是不满意度+32(换乘增量)。
void drawUnpls(Path path) {
// add unpleasant manually
for (int i = 0; i < path.size() - 1; i++) {
short pos1;
short pos2;
// update id2Pos & valid[]
pos1 = updateDictValid(path.getNode(i));
pos2 = updateDictValid(path.getNode(i + 1));
edge[pos1][pos2] = true;
edge[pos2][pos1] = true;
unpls[pos1][pos2] = edgeUnpls(path.getNode(i), path.getNode(i + 1));
unpls[pos2][pos1] = edgeUnpls(path.getNode(i), path.getNode(i + 1));
}
// run Floyd
Floyd();
}
最后一个bug属于细节问题,在应用了上文提到的计算最低票价矩阵price[][]等矩阵的方法之后,在查询方法中按理说只需读取矩阵数据并做简单计算即可,但是我当时忽略了接近0时的边界情况。举例来说,从某一站到其自身的票价应该是0,但是按我的方法计算出来的票价=矩阵里的值(0)-2=-2,这显然是错误的,因此还需要在返回结果前增加一步对返回值的检查。该方法的代码如下。对于最少换乘次数矩阵和不满意度矩阵也需要做类似的处理。
public int getLeastTicketPrice(int fromNodeId, int toNodeId)
throws NodeIdNotFoundException, NodeNotConnectedException {
// exceptional_behavior
if (!containsNode(fromNodeId)) {
throw new NodeIdNotFoundException(fromNodeId);
}
if (!containsNode(toNodeId)) {
throw new NodeIdNotFoundException(toNodeId);
}
if (!isConnected(fromNodeId, toNodeId)) {
throw new NodeNotConnectedException(fromNodeId, toNodeId);
}
// normal_behavior
if (price[id2Pos.get(fromNodeId)][id2Pos.get(toNodeId)] - 2 >= 0) {
return price[id2Pos.get(fromNodeId)][id2Pos.get(toNodeId)] - 2;
} else {
return 0;
}
}
5 心得体会
这一单元的训练重点,我认为,在于对于JML规格的理解以及将JML规格正确且高效地转化为Java代码的能力。而通过这一单元的三次作业,我相信我已经很好地掌握了这些能力。JML规格,正如老师在课上提到过的,确实是一种很好的工具来显式地表达程序员在设计架构和定义方法功能时的思路,同时在多人协作的开发任务中也是一种高效的交流方式(尽管我们暂时还没有多人协作开发的机会)。
不过,我确实还有一点疑惑,为什么只是高强度地训练我们根据JML语言进行架构设计和编程的能力,而仅仅在实验课中才略微涉及到根据代码撰写JML规格文档的能力呢?在我看来,这两种能力是相辅相成的,同时也是具有同等重要性的。