1.bin()函数将十进制转换成而进制
2.oct()函数将十进制转换成八进制
3.hex()函数将十进制转换成十六进制
十六进制表示:0-9 a b c d e f
4.数字类型的特性:
只能存放一个值
一经定义,不可更改
直接访问
分类:整型,布尔,浮点,复数
字符串类型
1.字符串类型
判断类型type()
引号包含的都是字符串类型
S1='hello world' s="hello world"
s2="""hello world"""
s3='''hello world'''
单引双引没有区别
2.字符串是字符的序列
字符串是若干字符的序列。
在Python中,索引是从字符串头部算起的一个偏移量,第一个字母的偏移量为0
a='abcd'
a[0]
- [:] 提取从开头(默认位置0)到结尾(默认位置-1)的整个字符串
- [start:] 从start 提取到结尾
- [:end] 从开头提取到end - 1
- [start:end] 从start 提取到end - 1
- [start:end:step] 从start 提取到end - 1,每step 个字符提取一个
- 左侧第一个字符的位置/偏移量为0,右侧最后一个字符的位置/偏移量为-1
6.字符串的常用操作
in 判断一个字符串是否在另一个字符串中
strip()移除空白,也可以去除其他的字符
s.lstrip(rm) 删除s字符串中开头处,位于 rm删除序列的字符
s.rstrip(rm) 删除s字符串中结尾处,位于 rm删除序列的字符
slipt()分割,默认以空格分割。也可以以其他的字符分割
s='tom,21'
print s.split(',')
name,age=s.split(',')
len()长度
切片:如print(x[1:3])也是顾头不顾尾 print(x[0:5:2])#0 2 4
capitalize()首字母大写
center()居中显示例如:x='hello' print(x.center(30,'#'))
count():计数,顾头不顾尾,统计某个字符的个数,空格也算一个字符
endswith()以什么结尾
satrtswith()以什么开头
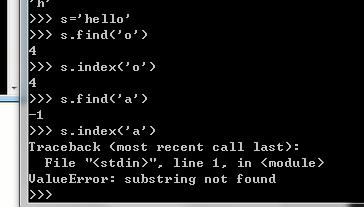
find()查找字符的索引位置,如果是负数,代表查找失败
index()索引
find()和index()的区别,如下图:
方法1
a=1
b=2
print 'a=%s'% a
print 'a = %d,b = %s'%(a,b)
print 'a = %20d,b = %s'%(a,b)
print '我 = %.8f,年 = %s'%(a,b)
方法2
format()字符串格式化
1.msg='name:{},age:{},sex:{}'
print(msg.format('haiyan',18,女))
2.msg='name:{0},age:{1},sex:{0}'
print(msg.format('aaaaaa','bbbbbb'))
3.msg='name:{x},age:{y,sex:{z}'
print(msg.format(x='haiyan',y='18',z='女'))
isdigit()判断是否是数字
islower()判断是否是全部小写
isupper()判断是否是全部大写
lower()全部转换为小写
upper()全部转换为大写
isspace()判断是否是全都是空格
istitle()判断是否是标题(首字母大写)
swapcase()大小写字母翻转
join()连接 +'.join(['a','b','c']) print '+'.join(['a','b','c']) print '/'.join('abc')
repalce()替换
msg='hello alex'
print(msg.replace('e'),'A',1)
print(msg.replace('e'),'A',2)
ljust()左对齐
X='ABC' print(x.ljust(10,'*'))
列表
ist 是有序集合
一、创建一个列表
list1 = ["a", "b", "c", "d"];
二、访问列表中的值 用索引来访问list中每一个位置的元素,记得索引是从0开始的
list1 = ['physics', 'chemistry', 1997, 2000];
print "list1[0] print "list1[1:3]
三、更新列表
你可以对列表的数据项进行修改或更新,你也可以使用append()方法来添加列表项,
l= ['physics', 'chemistry', 1997, 2000];
l[2] = 2001;
l.insert(1, 'Jack')
l.appent(2)
四、删除列表元素
要删除list末尾的元素,用pop()方法
list1 = ['physics', 'chemistry', 1997, 2000];
list1.pop()
要删除指定位置的元素,用pop(i)方法,其中i是索引位置
list1.pop(0)
五、Python列表脚本操作符
列表对 + 和 * 的操作符与字符串相似。+ 号用于组合列表,* 号用于重复列表。
listt里面的元素的数据类型也可以不同
s = ['python', True, ['asp', 'php'], 1]
六、Python列表截取
序列:(三种类型)
字符串 不可以修改
列表list [] 可以修改
元组tuple () 不可以修改
----特点:
1.可以进行索引,索引为负数,则从右边开始计数
2.可以使用切片操作符 [m:n]
for 和 in :
forvarinlist #遍历一个列表valueincollection #测试集合中是否存在一个值
七、Python列表操作的函数和方法
列表操作包含以下函数:
1、cmp(list1, list2):比较两个列表的元素
2、len(list):列表元素个数
3、max(list):返回列表元素最大值
4、min(list):返回列表元素最小值
5、list(seq):将元组转换为列表
列表操作包含以下方法:
1、list.append(obj):在列表末尾添加新的对象
2、list.count(obj):统计某个元素在列表中出现的次数
3、list.extend(seq):在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表)
4、list.index(obj):从列表中找出某个值第一个匹配项的索引位置
5、list.insert(index, obj):将对象插入列表
6、list.pop(obj=list[-1]):移除列表中的一个元素(默认最后一个元素),并且返回该元素的值
7、list.remove(obj):移除列表中某个值的第一个匹配项
8、list.reverse():反向列表中元素
9、list.sort([func]):对原列表进行排序
列表去重复
方法1
ids = [1,2,3,3,4,2,3,4,5,6,1]
newids=[]
for i in ids:
if i not in newids:
newids.append(i)
print newids
方法2
ids = [1,2,3,3,4,2,3,4,5,6,1]
c=set(ids)
print list(c)
以下是列表的常用操作:

l=[1,2,3] #l=list([1,2,3]) # print(type(l)) #pat1===》优先掌握部分 # 索引:l=[1,2,3,4,5] print(l[0]) 7 # 切片 l=['a','b','c','d','e','f'] # print(l[1:5]) # print(l[1:5:2]) # print(l[2:5]) # print(l[-1]) #了解 # print(l[-1:-4]) # print(l[-4:]) # l=['a','b','c','d','e','f'] # print(l[-2:]) # 追加 # hobbies=['play','eat','sleep','study'] # hobbies.append('girls') # print(hobbies) # 删除 hobbies=['play','eat','sleep','study'] # x=hobbies.pop(1) #不是单纯的删除,是删除并且把删除的元素返回,我们可以用一个变量名去接收该返回值 # print(x) # print(hobbies) # x=hobbies.pop(0) # print(x) # # x=hobbies.pop(0) # print(x) #队列:先进先出 queue_l=[] #入队 # queue_l.append('first') # queue_l.append('second') # queue_l.append('third') # print(queue_l) #出队 # print(queue_l.pop(0)) # print(queue_l.pop(0)) # print(queue_l.pop(0)) #堆栈:先进后出,后进先出 # l=[] # #入栈 # l.append('first') # l.append('second') # l.append('third') # #出栈 # print(l) # print(l.pop()) # print(l.pop()) # print(l.pop()) #了解 # del hobbies[1] #单纯的删除 # hobbies.remove('eat') #单纯的删除,并且是指定元素去删除 # 长度 # hobbies=['play','eat','sleep','study'] # print(len(hobbies)) # 包含in # hobbies=['play','eat','sleep','study'] # print('sleep' in hobbies) # msg='hello world egon' # print('egon' in msg) ##pat2===》掌握部分 hobbies=['play','eat','sleep','study','eat','eat'] # hobbies.insert(1,'walk') # hobbies.insert(1,['walk1','walk2','walk3']) # print(hobbies) # print(hobbies.count('eat')) # print(hobbies) # hobbies.extend(['walk1','walk2','walk3']) # print(hobbies) hobbies=['play','eat','sleep','study','eat','eat'] # print(hobbies.index('eat')) #pat3===》了解部分 hobbies=['play','eat','sleep','study','eat','eat'] # hobbies.clear() # print(hobbies) # l=hobbies.copy() # print(l) # l=[1,2,3,4,5] # l.reverse() # print(l) l=[100,9,-2,11,32] l.sort(reverse=True) print(l)
tuple
另一种有序列表叫元组:tuple。tuple和list非常类似,但是tuple一旦初始化就不能修改
Python在显示只有1个元素的tuple时,也会加一个逗号,,以免你误解成数学计算意义上的括号
t = (1,)


#为何要有元组,存放多个值,元组不可变,更多的是用来做查询 t=(1,[1,3],'sss',(1,2)) #t=tuple((1,[1,3],'sss',(1,2))) # print(type(t)) # #元组可以作为字典的key # d={(1,2,3):'egon'} # print(d,type(d),d[(1,2,3)]) # 切片 # goods=('iphone','lenovo','sanxing','suoyi') # print(goods[1:3]) # 长度 #in: #字符串:子字符串 #列表:元素 #元组:元素 #字典:key # goods=('iphone','lenovo','sanxing','suoyi') # print('iphone' in goods)看的是里面的元素在不在里面 # d={'a':1,'b':2,'c':3} # print('b' in d) 看的是key在不在d里面 #掌握 # goods=('iphone','lenovo','sanxing','suoyi') # print(goods.index('iphone')) # print(goods.count('iphone')) #补充:元组本身是不可变的,但是内部的元素可以是可变类型 t=(1,['a','b'],'sss',(1,2)) #t=tuple((1,[1,3],'sss',(1,2))) # t[1][0]='A' # print(t) # t[1]='aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa'
python中列表,元组,字符串如何互相转换
1. str转list
list = list(str)
2. list转str
str= ''.join(list)
3. tuple list相互转换 元组不能修改,列表可以修改
tuple=tuple(list)
list=list(tuple)
dict
Python内置了字典:dict的支持在其他语言中也称为map,使用键-值(key-value)存储,具有极快的查找速度
列表也是序列,字符串也是序列
字典
字典类型与序列类型的区别:
1.存取和访问数据的方式不同。
2.序列只能用整数做为索引;
3.字典中索引几乎可以是任意类型
4.映射类型中的数据是无序排列的、字典中的键必须是唯一的,而值可以不唯一
注意:如果字典中的值为数字,最好使用字符串数字形式,如:'age':'040′ 而不用 ‘age':040
1.创建一个字典
d = {} 空字典
dict1={“name”:”jiamingqiang”,tel:”132567890345”,”sex”:”man”}

2.返回字典的长度 len(dict1)
3.添加一项 dict1[“age”]=25
4.如何获取字典对应K的 value
dict1[“name”]
dict1.get(“name”)
5.如何获取所有的kye和values
dict1.kyes
dict1.values
6.pop和popitem del
pop弹出给定key的项的值,然后在字典中删除该项,popitem弹出任意一项
d.pop(key)
d.popitem() 删除任意项,因字典是无序的
del d[key]
7.判断key是否存在
key in d
d.has_key(key)
a={"name":"2","age":"胡晓燕"}
if "name" in a:
print "huxiaoyan"
if a.has_key("name"):
print "huxiaoyan"
遍历字典
d = {'name':'jia', 'age':'25'}
for key in d:
print key
for key in d.keys():
print key
a='abc'
b='123'
c=zip(a,b)
d1=dict(c)
print d1
八、使用字典的注意事项
1、不能允许一键对应多个值;
2、键必须是可哈希的。
和list比较,dict有以下几个特点:
-
查找和插入的速度极快,不会随着key的增加而变慢;
-
需要占用大量的内存,内存浪费多。
而list相反:
-
查找和插入的时间随着元素的增加而增加;
-
占用空间小,浪费内存很少。
set
set和dict类似,也是一组key的集合,但不存储value。由于key不能重复,所以,在set中,没有重复的key。
l=[1,2,3,3]
s=set(l)
s.add('4')
s.remove(1)
字典的表示方法: info_dic={'name':'haiyna','age':18,'sex':'female'} # 常用操作: # 1.存/取 info_dic={'name':'egon','age':18,'sex':'male'} print(info_dic['name11111111'])#找不到则报错了 print(info_dic.get('name',None)) print(info_dic.get('name222222',None))#get方法找不到不报错,可以自己设定默认值 #pop:key存在则弹出值,不存在则返回默认值,如果没有默认值则报错 # print(info_dic.pop('nam123123123123123123e',None)) # print(info_dic) # print(info_dic.popitem()) # print(info_dic) # info_dic['level']=10 # print(info_dic) # # 删除 info_dic={'name':'egon','age':18,'sex':'male'} # info_dic.pop() # info_dic.popitem() # del info_dic['name'] # # 键s,值s,键值对 info_dic={'name':'egon','age':18,'sex':'male'} # print(info_dic.keys()) # print(info_dic.values()) # print(info_dic.items()) # for k in info_dic: # # print(k,info_dic[k]) # print(k) # print('========>') # for k in info_dic.keys(): # print(k) # for val in info_dic.values(): # print(val) # for k,v in info_dic.items(): #k,v=('name', 'egon') # print(k,v) # 长度 # info_dic={'name':'egon','age':18,'sex':'male'} # print(len(info_dic)) # # 循环 # # 包含in # info_dic={'name':'egon','age':18,'sex':'male'} # print('name' in info_dic) # print('name' in info_dic.keys()) # print('egon' in info_dic.values()) # print(('name','egon') in info_dic.items()) #掌握 info_dic={'name':'egon','age':18,'sex':'male'} # info_dic.update({'a':1,'name':'Egon'}) # print(info_dic) # info_dic['hobbies']=[] # info_dic['hobbies'].append('study') # info_dic['hobbies'].append('read') # print(info_dic) #setdefault:key不存在则设置默认值,并且放回值默认值 #key存在则不设置默认,并且返回已经有的值 # info_dic.setdefault('hobbies',[1,2]) # print(info_dic) # info_dic.setdefault('hobbies',[1,2,3,4,5]) # print(info_dic) # info_dic={'name':'haiyan','age':18,'sex':'male'} # {'name':'egon','age':18,'sex':'male','hobbies':['study']} # info_dic.setdefault('hobbies',[]).append('study') # {'name':'egon','age':18,'sex':'male','hobbies':['study','read']} # info_dic.setdefault('hobbies',[]).append('read') # {'name':'egon','age':18,'sex':'male','hobbies':['study','read','sleep']} # info_dic.setdefault('hobbies',[]).append('sleep') # l=info_dic.setdefault('hobbies',[]) # print(l,id(l)) # print(id(info_dic['hobbies'])) # print(info_dic) #了解 # d=info_dic.copy() # print(d) # info_dic.clear() # print(info_dic) # d=info_dic.fromkeys(('name','age','sex'),None) # print(d) # d1=dict.fromkeys(('name','age','sex'),None) # d2=dict.fromkeys(('name','age','sex'),('egon',18,'male')) # print(d1) # print(d2) # info=dict(name='haiyan',age=18,sex='male') # print(info) # # info=dict([('name','haiyan'),('age',18)]) # print(info)
一、集合的作用
知识点回顾:可变类型是不可hash类型,不可变类型是可hash类型
作用:去重,关系运算
定义:可以包含多个元素,用逗号分割,集合的元素遵循三个原则:
1.每个元素必须是不可变类型(可hash,可作为字典的key)
2.没有重复的元素
4.无序
注意集合的目的是将不同的值存放在一起,不同的集合间用来做关系运算,无需纠结集合中的单个值
二、常用方法

in 和 not in
|并集(print(pythons.union(linuxs)))
&交集(print(pythons.intersection(linuxs)))
-差集(print(pythons.difference(linuxs)))
^对称差集(print(pythons.symmetric_difference(linuxs)))
==
>,>= ,<,<= 父集(issuperset),子集(issuberset)
>,>=,<,<= set1={1,2,3,4,5} set2={1,2,3,4} print(set1 >= set2) print(set1.issuperset(set2)) set1={1,2,3,4,5} set2={1,2,3} print(set1<=set2) print(set1.issubset(set2))
三、练习
一.关系运算
有如下两个集合,pythons是报名python课程的学员名字集合,linuxs是报名linux课程的学员名字集合
pythons={'alex','egon','yuanhao','wupeiqi','gangdan','biubiu'}
linuxs={'wupeiqi','oldboy','gangdan'}
1. 求出即报名python又报名linux课程的学员名字集合
2. 求出所有报名的学生名字集合
3. 求出只报名python课程的学员名字
4. 求出没有同时这两门课程的学员名字集合
pythons={'haiyan','fank','yaling','lalal','haidong','biubiu'}
linuxs={'six','wu','dabao'}
# 1. 求出即报名python又报名linux课程的学员名字集合
pythons={'haiyan','fank','yaling','lalal','haidong','biubiu'}
linuxs={'six','wu','dabao'}
print(pythons & linuxs)
# 2. 求出所有报名的学生名字集合
pythons={'haiyan','fank','yaling','lalal','haidong','biubiu'}
linuxs={'six','wu','dabao'}
print(pythons | linuxs)
# 3. 求出只报名python课程的学员名字
pythons={'haiyan','fank','yaling','lalal','haidong','biubiu'}
linuxs={'six','wu','dabao'}
print(pythons - linuxs)
# 4. 求出没有同时这两门课程的学员名字集合
pythons={'haiyan','fank','yaling','lalal','haidong','biubiu'}
linuxs={'six','wu','dabao'}
print(pythons ^ linuxs)
四、方法
# ========掌握部分=======
linuxs={'six','wu','dabao'}
linuxs.add('xiaoxiao')#说明set类型的集合是可变类型
linuxs.add([1,2,3])#报错,只能添加不可变类型
print(linuxs)
# 2.
linuxs={'six','wu','dabao'}
res=linuxs.pop() #不用指定参数,随机删除,并且会有返回值
print(res)
# 3.
res=linuxs.remove('wupeiqi')#指定元素删除,元素不存在则报错,单纯的删除,没有返回值,
print(res)
# 4.
res=linuxs.discard('egon1111111111') #指定元素删除,元素不存在不报错,单纯的删除,没有返回值,
# =========了解部分=========
linuxs={'wupeiqi','egon','susan','hiayan'}
new_set={'xxx','fenxixi'}
linuxs.update(new_set)
print(linuxs)
linuxs.copy()
linuxs.clear()
#解压
a,*_={'zzz','sss','xxxx','cccc','vvv','qqq'}
print(a)