首先,查看local模式下程序是如何运行的,上代码,从最简单的例子开始,
第一步:编写流处理的小例子
需求:接收来自Kafka中sensor-temperature主题下的温度传感器数据,计算各传感器每天的5秒内的平均温度
代码:TemperatureAnalysis.java


package com.mengyao.flink;
import org.apache.commons.lang3.StringUtils;
import org.apache.flink.api.common.accumulators.AverageAccumulator;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.PrintSinkFunction;
import org.apache.flink.streaming.api.functions.source.FromElementsFunction;
import org.apache.flink.streaming.api.windowing.time.Time;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.time.Duration;
import java.util.*;
/**
* @ClassName TemperatureAnalysis
* @Description
* @Created by MengYao
* @Date 2020/11/18 10:14
* @Version V1.0
*/
public class TemperatureAnalysis {
// 作业名称
private static final String JOB_NAME = TemperatureAnalysis.class.getSimpleName();
// 解析字符串时间
private static final ThreadLocal<SimpleDateFormat> FMT = ThreadLocal.withInitial(() -> new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"));
// 输入的温度数据
private static final List<String> DATA = Arrays.asList(
"T1,2020-01-30 19:00:00,22",
"T1,2020-01-30 19:00:01,25",
"T1,2020-01-30 19:00:03,28",
"T1,2020-01-30 19:00:06,26",
"T1,2020-01-30 19:00:05,27",
"T1,2020-01-30 19:00:12,31"
);
public static void main(String[] args) {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment()
// 每隔5秒进行一次CheckPoint,事件传递语义为恰好一次
.enableCheckpointing(5000, CheckpointingMode.EXACTLY_ONCE);
// 使用事件时间
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
try {
// 从集合中创建数据源
env.addSource(new FromElementsFunction<>(Types.STRING.createSerializer(env.getConfig()), DATA), Types.STRING)
.map(line -> TemperatureBean.of(line))// 将字符串时间转换为Temperature类型的POJO
.filter(Objects::nonNull)// 排除空数据
.assignTimestampsAndWatermarks(WatermarkStrategy.<TemperatureBean>forBoundedOutOfOrderness(Duration.ofSeconds(5)).withTimestampAssigner((TemperatureBean event, long timestamp) -> event.getTs(FMT.get())))// 提取Temperature类型事件的事件时间字段(cdt)作为注册水位线的时间戳
.keyBy(TemperatureBean::getKey)// 根据Key(ID_yyyy-MM-dd)分组,按照每个温度传感器每天的所有温度数据放到一个分区中
.timeWindow(Time.seconds(5))// 5秒的滚动窗口
.aggregate(new AggregateFunction<TemperatureBean, Acc, String>() {// 对每个窗口的温度数据进行聚合运算(平均)
@Override
public Acc createAccumulator() {
return new Acc();
}
@Override
public Acc add(TemperatureBean value, Acc acc) {
acc.setKey(value.getKey());
acc.add(value.getTemperature());
return acc;
}
@Override
public String getResult(Acc acc) {
return acc.toString();
}
@Override
public Acc merge(Acc a, Acc b) {
b.add(a.getLocalValue());
return b;
}
})
.addSink(new PrintSinkFunction<>());// 从控制台中打印
env.execute(JOB_NAME);// 执行作业
} catch (Exception e) {
e.printStackTrace();
}
}
static class TemperatureBean {
private String sensorId;
private String cdt;
private double temperature;
public static TemperatureBean of(String line) {
return of(",", line);
}
public static TemperatureBean of(String delimiter, String line) {
if (StringUtils.isNotEmpty(line)) {
String[] values = line.split(delimiter, 3);
return new TemperatureBean(values[0], values[1], Double.parseDouble(values[2]));
}
return null;
}
public TemperatureBean() {}
public TemperatureBean(String sensorId, String cdt, double temperature) {
this.sensorId=sensorId;
this.cdt = cdt;
this.temperature = temperature;
}
public String getKey() {
return getSensorId()+"_"+getDay();
}
public long getTs(SimpleDateFormat sdf) {
try {
return sdf.parse(cdt).getTime();
} catch (ParseException e) {
e.printStackTrace();
}
return -1;
}
public String getDay() {
return cdt.substring(0,10);
}
public String getSensorId() {
return sensorId;
}
public void setSensorId(String sensorId) {
this.sensorId = sensorId;
}
public String getCdt() {
return cdt;
}
public void setCdt(String cdt) {
this.cdt = cdt;
}
public double getTemperature() {
return temperature;
}
public void setTemperature(double temperature) {
this.temperature = temperature;
}
@Override
public String toString() {
return String.join(", ", sensorId, cdt, Double.toString(temperature));
}
}
static class Acc extends AverageAccumulator {
private String key;
public void setKey(String key) {
this.key = key;
}
@Override
public String toString() {
return String.join(",", key, Double.toString(super.getLocalValue()));
}
}
}
第二步:在开发工具IDEA中运行程序,查看作业是如何执行的
整体的运行流程为:
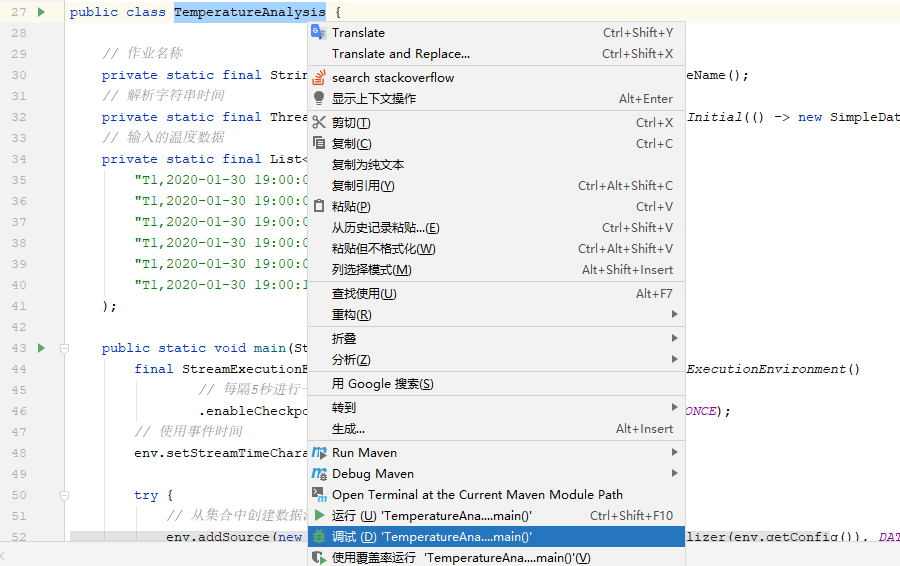
1、创建LocalStreamEnvironment实例(它继承自StreamExecutionEnvironment类)
2、
2.1、在StreamExecutionEnvironment.java类中
由于是直接在IDEA中执行,StreamExecutionEnvironment会创建LocalStreamEnvironment的实例,如下:

我们可以看到,LocalStreamEnvironment中只有三个方法:构造方法、校验配置对象方法和执行作业方法(调用父类实现提交)
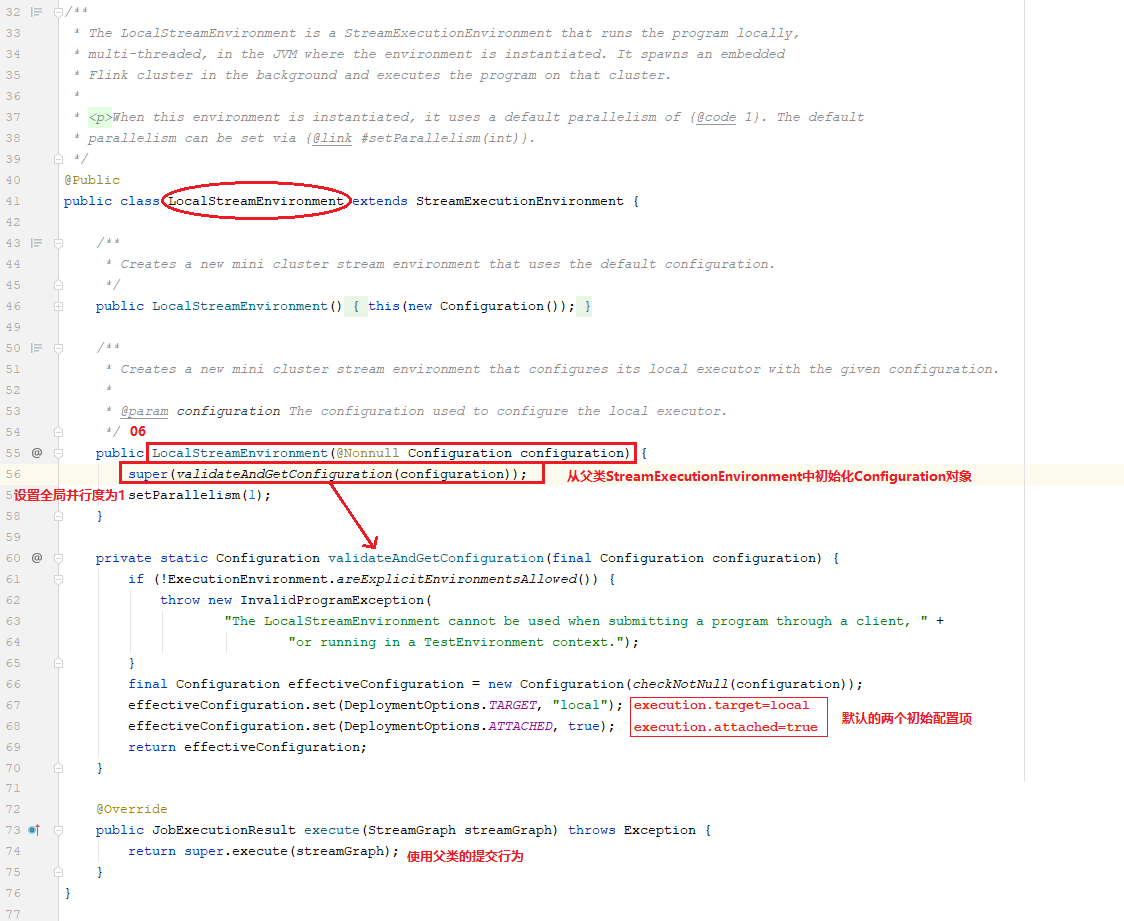
上面主要描述了Environment是如何初始化的,接下来我们看一下主程序TemperatureAnalysis中的env.execute(JOB_NAME)方法实际上是StreamExecutionEnvironment类的1694行的execute(String jobName)。
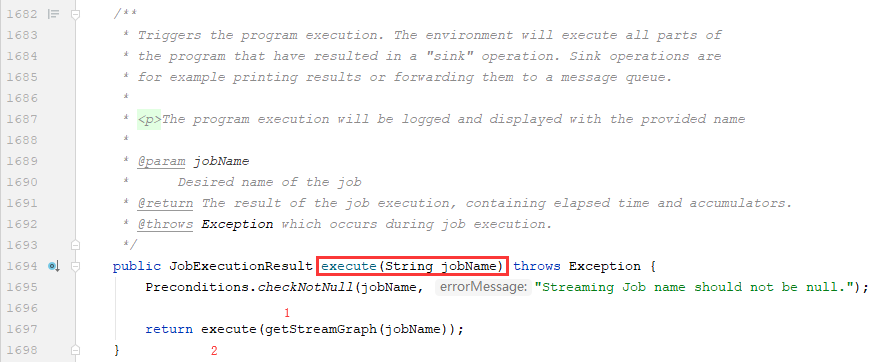
然后,在此方法中,做了两件事情:1)调用getStreamGraph(jobName)方法来得到一个StreamGraph对象;2)将StreamGraph对象传递给execute(StreamGraph streamGraph)方法;
1)获取StreamGraph对象的方法:getStreamGraph(jobName)方法的源码实现
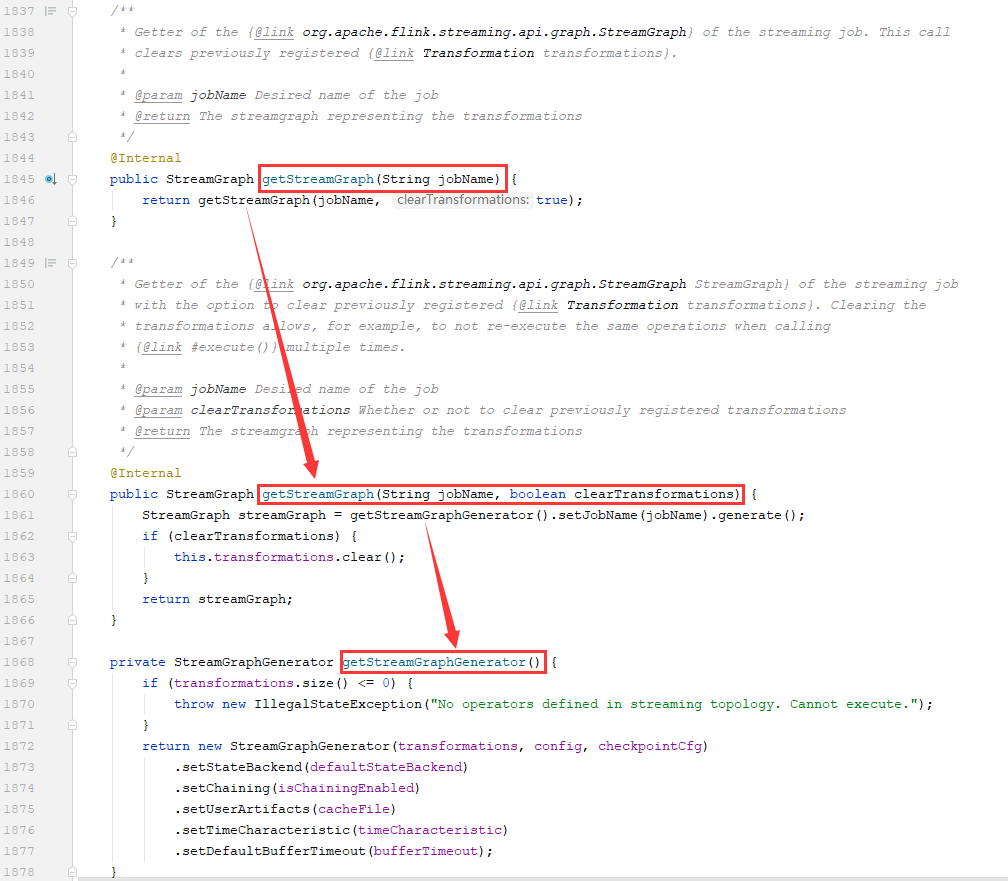
2)将StreamGraph对象传递给execute(StreamGraph streamGraph)方法,我们发现它又调用了executeAsync(streamGraph)方法
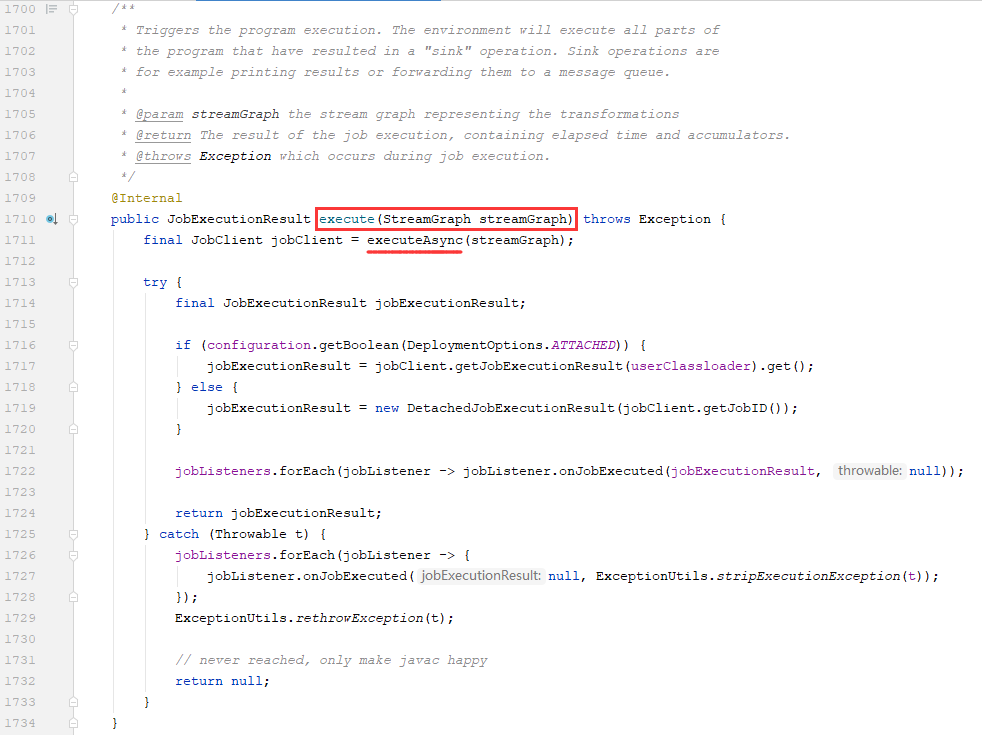
最后,来到executeAsync(StreamGraph streamGraph)方法中,发现它也做了2件事:1创建LocalExecutorFactory来获取LocalExecutor对象;2通过LocalExecutor对象的execute提交作业
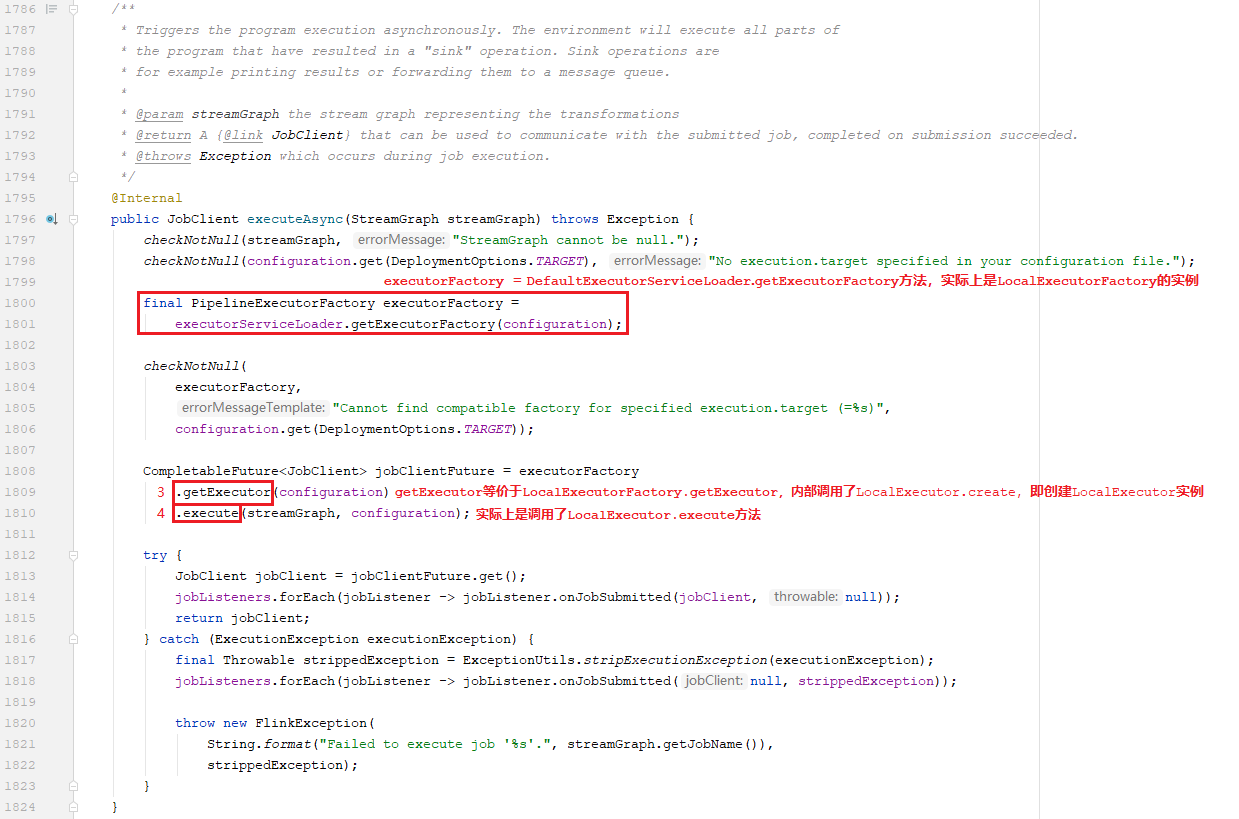
2.2、进入LocalExecutor.java类中
通过2.1部分的代码,我们已经知道了StreamExecutionEnvironment类的executeAsync方法中,是通过创建LocalExecutor对象并调用其execute方法来进行提交作业的,然后,我们来看一下LocalExecutor类的execute方法是怎么实现的
我们看到在方法内部,又是两件事:1)先获取JobGraph对象(标记红色数字5的地方),2)再通过PreJobMiniClusterFactory创建工厂实例并进行提交作业(标记红色数字12的地方)
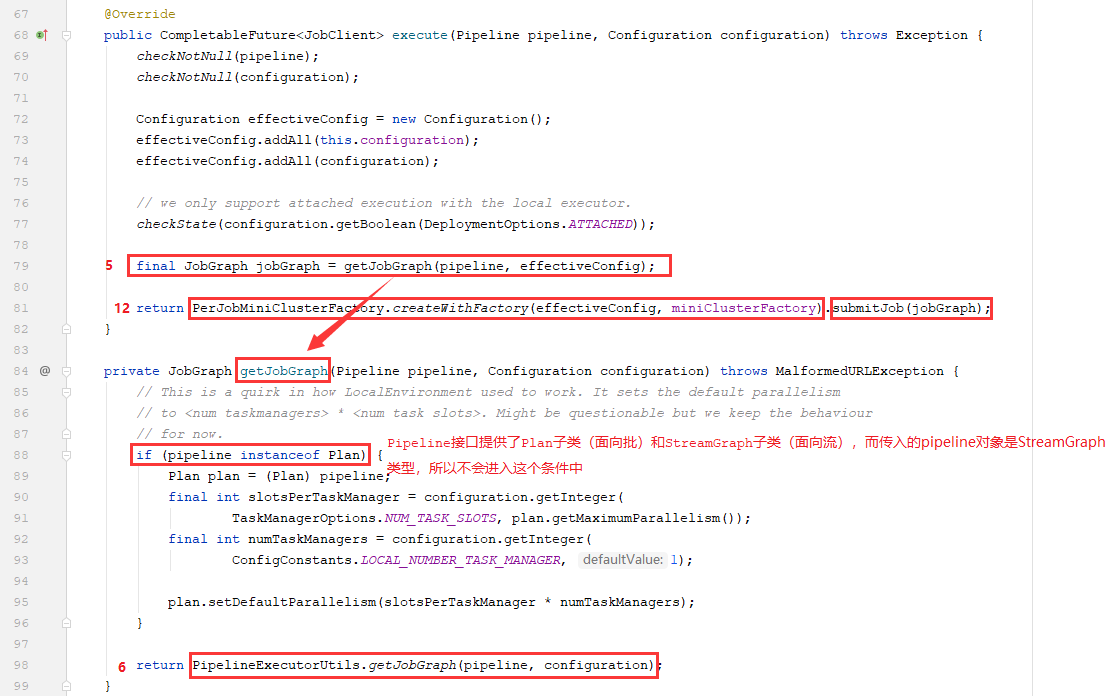
1)先获取JobGraph对象-1:先看一下获取JobGraph对象的源码定义,看到实际上是调用了LocalExecutor类中的getJobGraph方法,
在LocalExecutor.getJobGraph方法中:
1、判断传入的Pipeline接口的pipeline对象是属于StreamGraph类型还是Plan类型(因为Pipeline接口具有两个子类,分别是面向批的Plan类和面向流的StreamGraph类)
2、调用PipelineExecutorUtils类的静态方法getJobGraph来获取最终的JobGraph对象
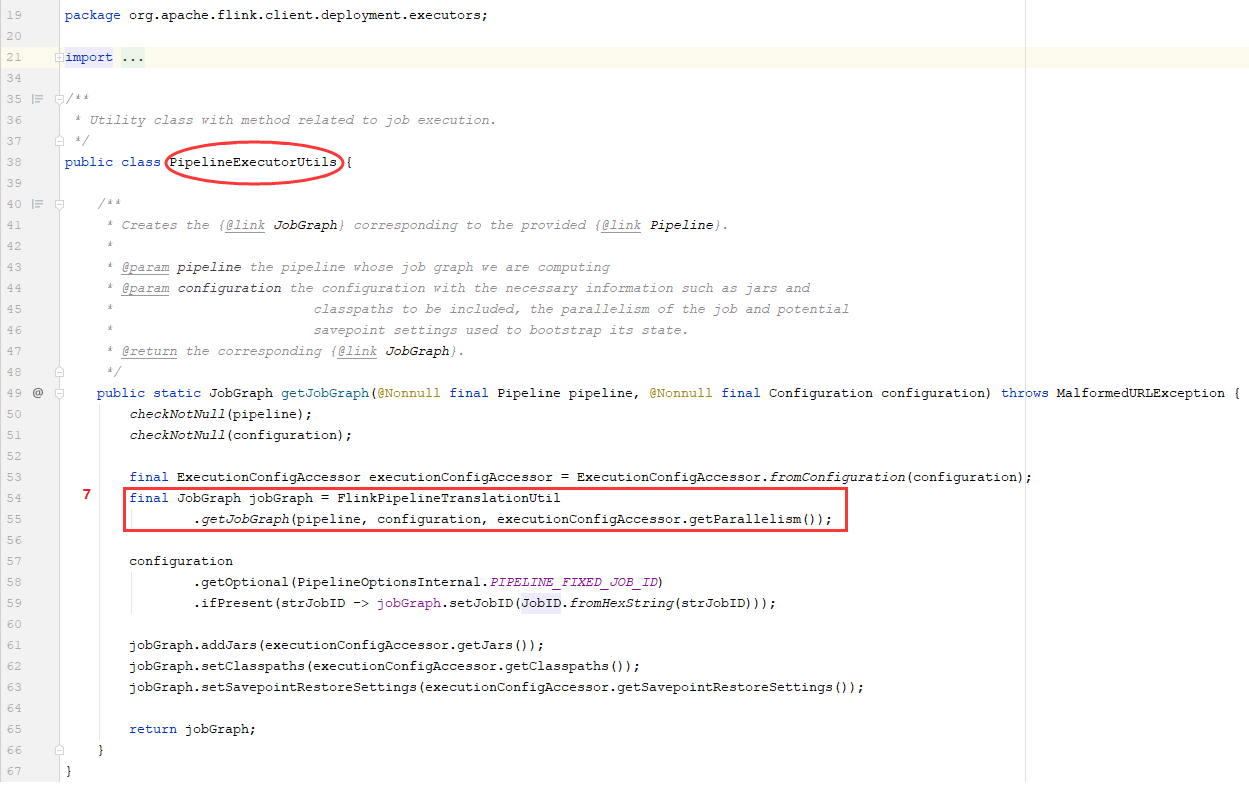
1)先获取JobGraph对象-2:查看PipelineExecutorUtils类中,getJobGraph方法是如何实现的
在PipelineExecutorUtils.getJobGraph方法中:
1、使用FlinkPipelineTranslationUtil类的静态方法getJobGraph来获取JobGraph对象
2、对得到的JobGraph对象设置Jar、Classpath和Savepoint等配置项
1)先获取JobGraph对象-3:查看FlinkPipelineTranslationUtil类中,getJobGraph方法是如何实现的
在FlinkPipelineTranslationUtil.getJobGraph方法中:
1、创建FlinkPipelineTranlator接口的实例(FlinkPipelineTranlator接口分别提供了面向流的StreamGraphTranslator子类和面向批的PlanTranlator子类),因为我们写的代码是流处理代码,所以这个传入的pipeline实际上是StreamGraph类型,所以会返回StreamGraphTranslator对象
2、调用StreamGraphTranslator对象的.translateToJobGraph方法。

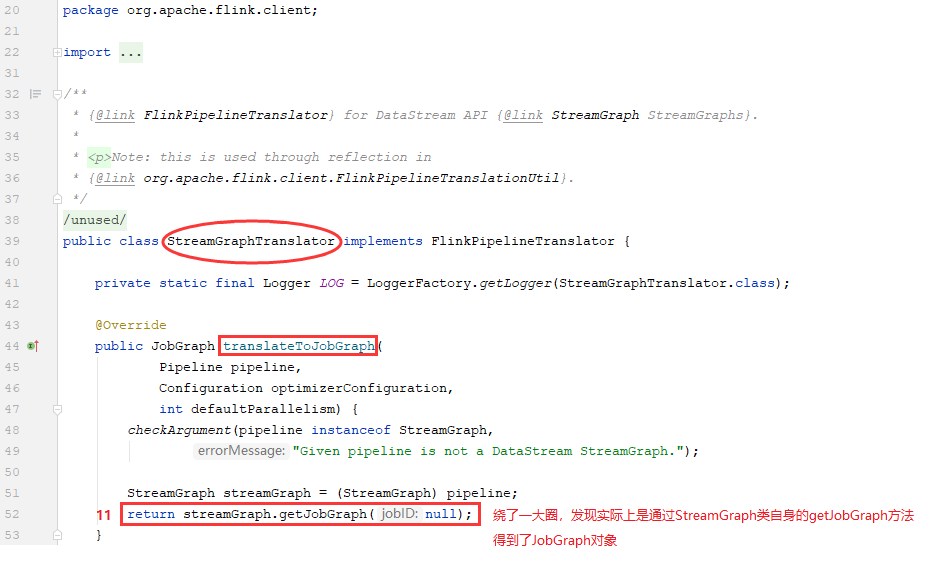
1)先获取JobGraph对象-4:查看StreamGraphTranslator类中,translateToJobGraph方法是如何实现的
在StreamGraphTranslator.translateToJobGraph方法中:
1、将Pipeline强转为StreamGraph类型,并调用StreamGraph类自身的getJobGraph方法来得到最终的JobGraph实例(到此处,有没有豁然开朗!)。
2)再通过PreJobMiniClusterFactory创建工厂实例并进行提交作业-1:
红色数字12部分显示的代码【return PerJobMiniClusterFactory.createWithFactory(effectiveConfig, miniClusterFactory).submitJob(jobGraph)】的主要作用是,创建PerJobMiniClusterFactory实例,然后提交作业。