《Very Deep Convolutional Networks for Large-Scale Image Recognition》
2014年牛津大学著名研究组VGG(Visual Geometry Group)提出
主要工作是证明了增加网络的深度能够在一定程度上影响网络最终的性能。
网络亮点
通过堆叠多个3*3的卷积核来替代大尺度卷积核(减少参数)
- 堆叠2个3 * 3的卷积核替代5 * 5的卷积核
- 堆叠3个3 * 3的卷积核替代7 * 7的卷积核
目的是在保证具有相同感知野的条件下,提升了网络的深度,在一定程度上提升了神经网络的效果。
缺点
- 参数量大
感受野计算公式
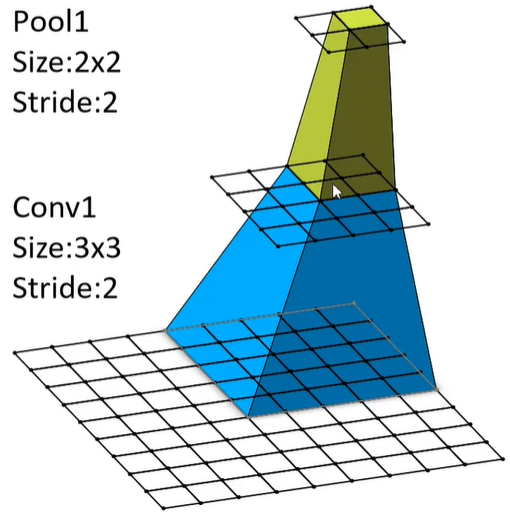

参数量

网络简洁和实用,整个网络都使用了同样大小的卷积核尺寸(3x3)和最大池化尺寸(2x2)
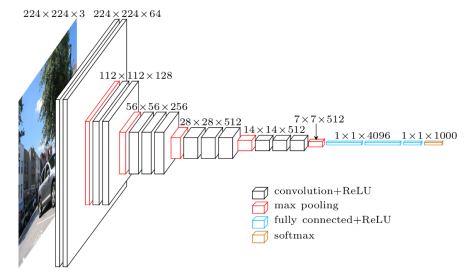
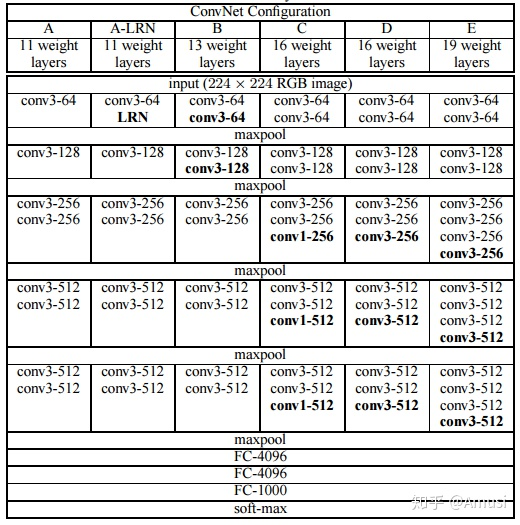
例:16 weight layers 16=13个卷积层+3个全连接层
代码实现 D
class VGG(nn.Module):
def __init__(self):
super(VGG, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.conv2 = nn.Sequential(
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(128, 128, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.conv3 = nn.Sequential(
nn.Conv2d(128, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.conv4 = nn.Sequential(
nn.Conv2d(256, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.conv5 = nn.Sequential(
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.fc1 = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(True),
nn.Dropout(p=0.5),
)
self.fc2 = nn.Sequential(
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(p=0.5),
)
self.fc3 = nn.Linear(4096, 1000)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.conv5(x)
x = torch.flatten(x, start_dim=1)
x = self.fc1(x)
x = self.fc2(x)
x = self.fc3(x)
return x