记录一些常用的pandas基础的使用方法。
1. 数据结构
pandas有两种主要的数据结构:Series和DataFrame
1.1 Series
Series是一个一维的数组对象,它包含了一个数据标签(称为索引)和一个数组数据。事实上,可以将Series理解为一个以数据标签为key,以数值为value的键值对(字典)。
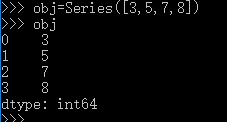
A.创建一个最简单的Series(其标签默认生成):
obj=Series([3,5,7,8])
生成结果:
B.获取其中的值(获取Series的数组表示):
obj.values

C.获取索引对象:
obj.index
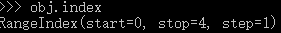
注意默认的索引,obj.index返回的对象是一个Int64的list对象
D.创建带有索引的Series:
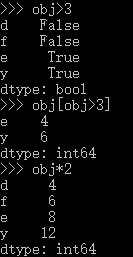
obj=Series([2,3,4,6],index=['d','f','e','y'])

E.利用索引获取值
obj['d']

F.通过bool数组过滤,使用乘法
obj[obj>3]
G.Series中的空值使用NaN表示,可以通过
pd.isnull(obj)
pd.notnull(obj)
检查数据是否为空值。
1.2 DataFrame
DataFrame类似于关系型数据库中的一张二维表。DataFrame在Series的基础上添加了列索引,因此可以看作是添加了列索引的Series数组。
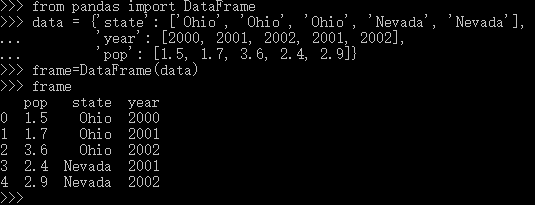
A.创建一个DataFrame
data = {'state': ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada'],
'year': [2000, 2001, 2002, 2001, 2002],
'pop': [1.5, 1.7, 3.6, 2.4, 2.9]}
frame=DataFrame(data)
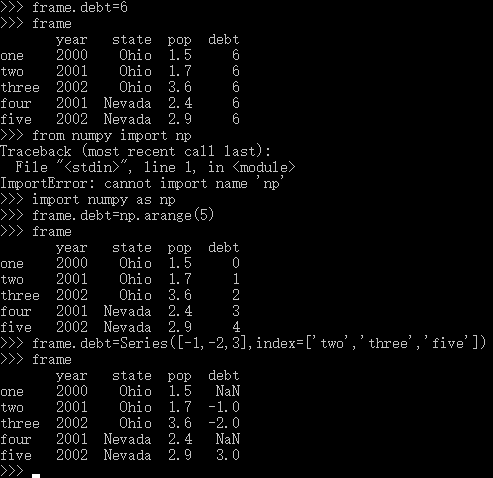
B.如果传递了一个行,但不包括在data中,创建的DataFrame将表示为NaN。(在这个例子中,debt所在列所有的行都为空值NaN,且我们显式地指定了行索引)
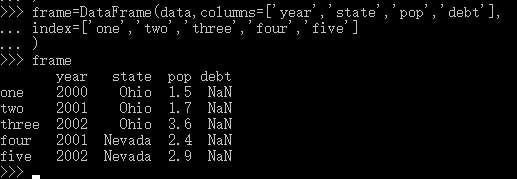
C.利用列索引,通过字典或者属性形式,获取DataFrame对象的一列
frame['year'] frame.year
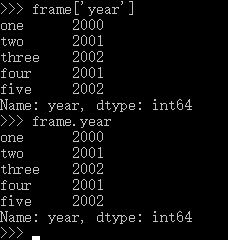
D.利用DataFrame.ix[]获取DataFrame对象的一行。注意向ix中传入的可以是行索引名字(如字符串形式),也可以是位置号
frame.ix[1] frame.ix['two']
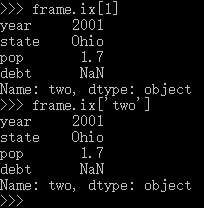
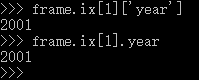
利用ix索引行,利用字典或者属性形式索引列,则可以组合以索引到DataFrame中的任意一个值
E.列可以通过赋值来修改,赋予的值可以是数字,数组或者Series对象
F.对一个不存在的列赋值,将会创建一个新的列
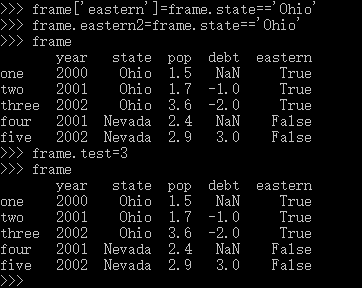
注意,利用字典形式对一个不存在的列赋值,才会新建一个列
2. 一些功能
2.1 重新索引
reindex使数据符合一个新的行索引,以构造一个新的对象。如果重新索引时,部分行不存在值,将置为NaN。columns可以对列重新索引
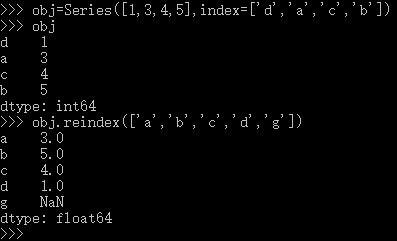
重新索引时,可以对丢失的值进行填充。可以传入method或者fill_value填充

当method为ffill表示填充值为前一行的值(前向填充),bfill表示填充值为后一行的值(后向填充)
2.2 从坐标轴删除条目
可以使用drop方法删除Series中的一个或多个值,删除DataFrame中的一个或多个行
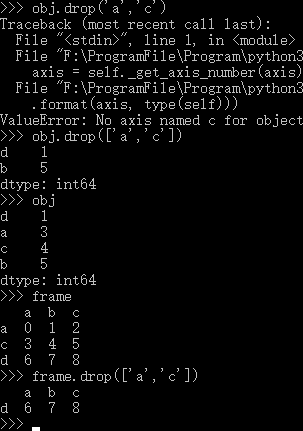
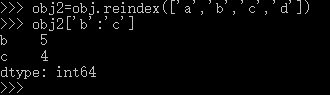
2.3 切片
可以使用标签切片,注意,这里切片和Python的切片并不一样,他会把结束点也包括在内
2.4 大文件读写
csv大文件读写一般向read_csv()函数中传入chunksize或者iterator参数完成
reader=pd.read_csv('./data1.csv',chunksize=10000) for chunk in reader:#chunk为DataFrame类型(二维表) for i in chunk.index:#chunk.index为元素类型为Int64的list value1=chunk.ix[i]['column']#获取chunk表中的一个值,先取行,在得列 value2=chunk['column'][i]#获取chunk中的一个值,先取列,再得行