神经机器翻译(Neural Machine Translation,NMT)建立源语言到目标语言的映射。多语种神经机器翻译(Multilingual NMT)能够实现一个模型在多个语言之间映射。本篇主要介绍神经机器翻译,以及多语种神经机器翻译的最新研究进展。
Does Multi-Encoder Help? A Case Study on Context-Aware Neural Machine Translation
来自金山AI Lab的一篇文章,探讨机器翻译中Context-Aware的作用。在编解码器机器翻译中,通常会使用额外的编码器来表征句子的上下文信息,该文研究了这个上下文编码器(context encoder)的工作机制:上下文编码器不仅仅编码句子的上下文,更重要的是扮演了一个噪声生成器的角色。实验证明,充满噪声的训练对于多编码器机器翻译模型非常重要,特别是数据量较少的情况下尤甚。
代码地址:Context-Aware
简介
目前有两种普遍的方法将上下文信息注入到机器翻译模型中。
-
最简单的方法就是,将上下文信息和当前的句子做拼接,插入特殊的符号区分它们,组合成上下文感知的输入序列,这种方法的缺陷在于需要编码较长的输入序列,计算效率低下;
-
更为普遍的方式是,利用额外的神经网络编码上下文句子,这种方法又可以细分为两种方式,一种是外部集成(Outside integration),一种是内部集成(Inside integration)。如图所示。
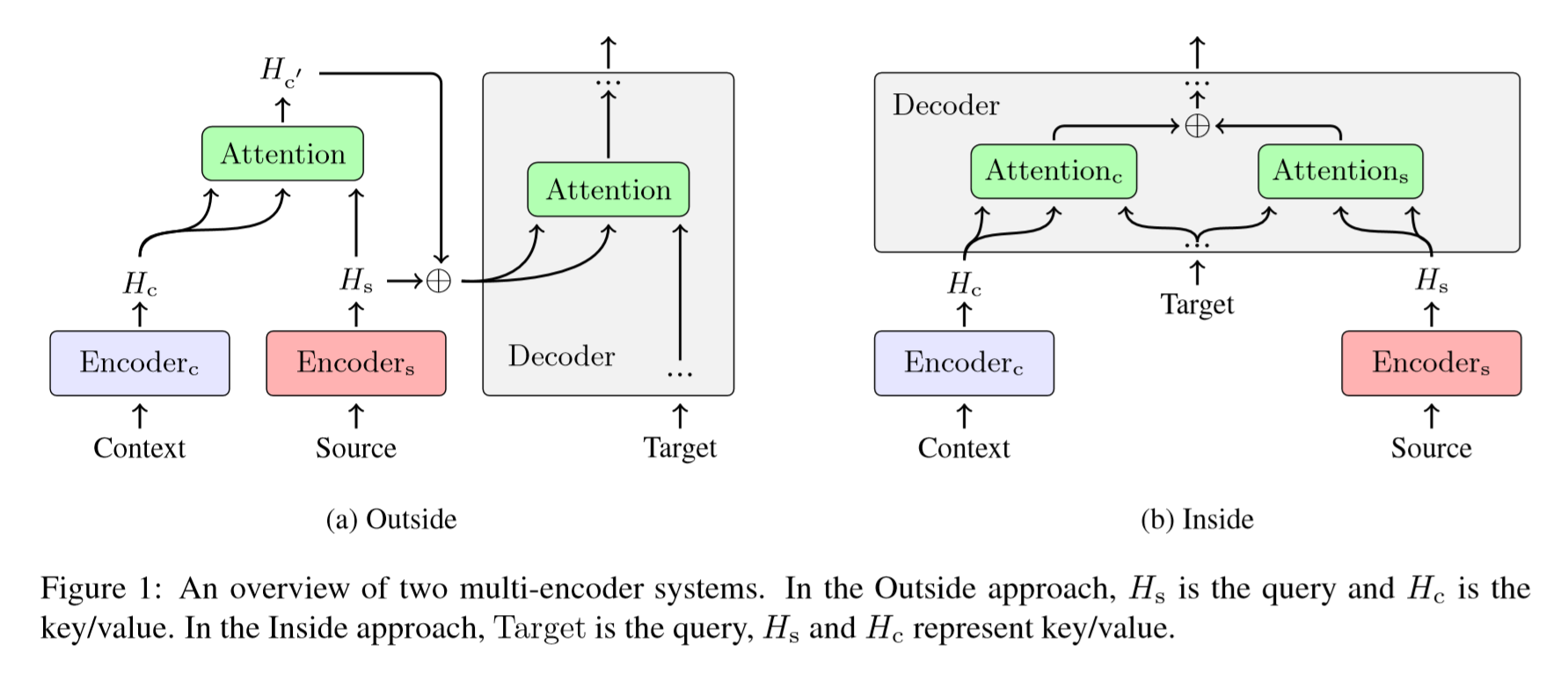
-
外部集成。如上图1(a),外部集成将上下文和当前句子通过注意力网络融合成一种新的表征,之后注意力网络的输出和当前句子的表征元素求和。
-
内部集成。如上图1(b),内部集成使用两个编码器,这两个编码器的输出使用解码器内部的门机制获得融合向量。
-
几个结论
-
不使用Context-Aware的基线模型(Sentence-Level Model)如果精调参数,比如调整Dropout率,相比于使用Context-Aware模型(Context-Aware/Multi-Encoder Model),两者BLEU差距会降低。
-
多编码器系统对上下文输入并不敏感。即使将随机的句子作为上下文编码器的输入,也会得到显著的性能提升。
-
使用Context-Aware训练的模型,在推断时候没有上下文输入的情况下,相反会带来更好的表现。实验结果如下。
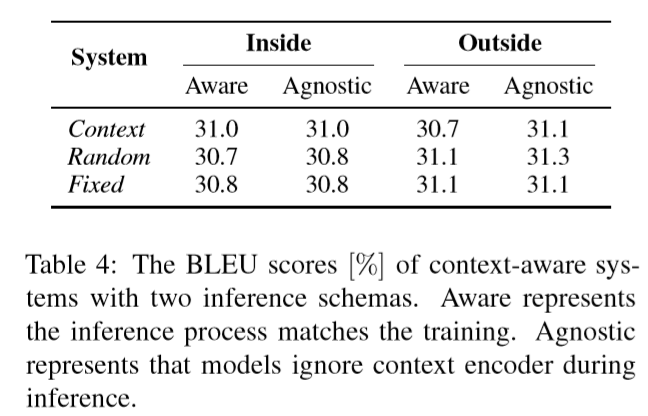
其中,Agnostic表示推断时候忽略上下文输入,Aware表示推断时候的输入和训练时一致。
基于以上的结论,Context-Aware模型相比于基线模型,主要是提供了一种正则化手段。该文在训练时向编码器输出注入高斯噪声,也能够提供相似甚至超越的性能表现。实验结果如下。
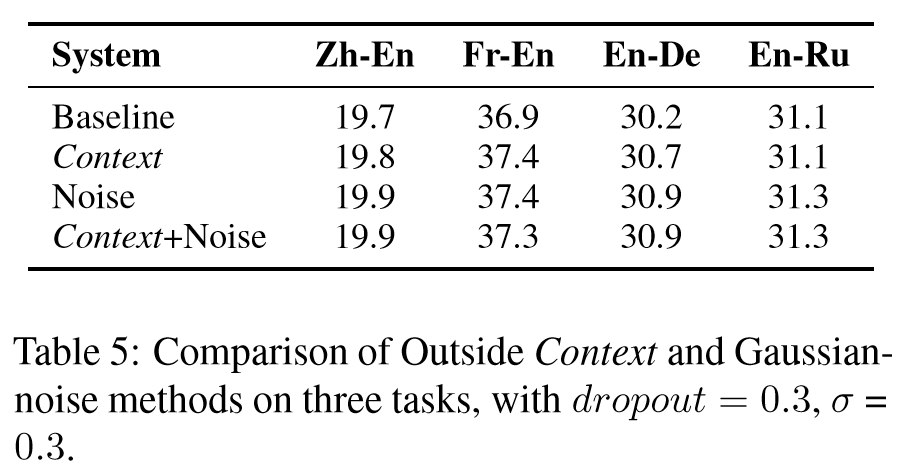
Multilingual Neural Machine Translation with Knowledge Distillation
使用训练好的单语言机器翻译模型作为老师,多语言机器翻译模型作为学生,进行知识蒸馏。
简介
- 一个老师一个学生
记(D={(x,y)in X imes Y})为双语数据集,则翻译模型( heta)在语料(D)上的对数似然损失(one-hot标签的交叉熵):
其中,(T_y)为目标序列的长度,(|V|)为目标语言的词汇表大小,(y_t)是第(t)个目标token,(mathbb{I}(cdot))是one-hot标签的指示函数,(P(cdot|cdot))是模型( heta)的条件概率。
在知识蒸馏中,学生模型(模型( heta))不仅仅匹配真实one-hot标签,而且拟合老师模型(模型( heta_T))的概率输出。记老师模型对于(y_t)的输出分布(Q(y_t|y_{<t},x; heta_T)),则学生模型和老师模型的输出分布之间的交叉熵,作为蒸馏损失:
(L_{NLL}(D; heta))和(L_{KD}(D; heta, heta_T))之间的差异主要是目标分布(L_{KD}(D; heta, heta_T))不再是原始的one-hot标签,而是老师的输出分布,老师对标签均分配一个非零概率,因而更平滑,计算出的梯度方差更小,因此整个的损失函数变为:
其中,(lambda)是平衡两个损失项的系数。
- 使用一个学生多个老师,进行多语种知识蒸馏
当多语种机器翻译模型的准确率没有超过某一阈值时,则使用损失函数(L_{ALL})不仅仅拟合真实数据,而且学习老师的输出,该阈值每( au_{check})步检查一次;否则,多语种机器翻译模型使用对数似然损失(L_{NLL})仅仅拟合真实数据。如下图,是整个算法的计算流程图,注意在训练过程中会动态切换损失函数。

多语种机器翻译蒸馏的两个技巧
- 选择性蒸馏
这里考虑到,一个较差的老师模型,有可能会损害学生模型的表现,导致较差的准确率。因此采用上图算法1中15-19行,使用所谓的“选择性蒸馏”的训练策略。当多语种机器翻译模型的准确率超过单语种模型某个阈值,则抛掉蒸馏损失。当然,如果后续准确率有降低了,蒸馏损失则又会加回来。
- Top-K蒸馏
主要是在训练之前,首先让老师模型生成Top-K标签,然后归一化作为蒸馏的老师输入。减少显存占用(将显存占用由词表大小(|V|)降低为(K)),而且对最终的蒸馏效果还有所提升。
Multilingual Neural Machine Translation with Soft Decoupled Encoding
多语种机器翻译有效提升了低数据资源语言上的准确率,本篇主要解决多语种机器翻译中的词表征问题。不同于以字符、子词(sub-word)、单词为单位的输入,软解耦编码(Soft Decoupled Encoding,SDE)多层次表征一个单词。
代码地址:SDE
简介
SDE主要包括三个部分:1)使用字符N-gram的单词编码;2)针对字符编码的特定语言转换;3)字符编码参与的,共享词嵌入空间的词嵌入。如图所示。
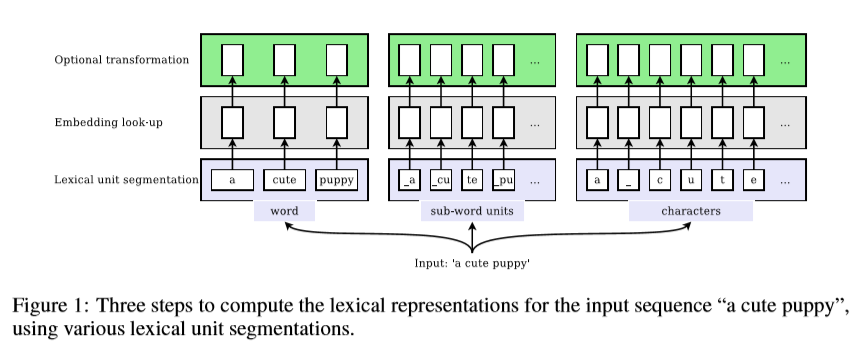
多语种机器翻译的词汇表征(Lexical Unit)
通常情况下,首先需要将一个句子分割成词汇单元,目前主要有三种形式:
-
单词。根据空格或者发音,将序列分割成单词。
-
字符。将输入序列分割为一个个字符。
-
子词(subword)。将语料中频繁出现的字符单元,切分出来,作为词汇表中的词。
之后,利用词嵌入(Emebdding)将这些词汇单元,转化为嵌入向量。
SDE的表征方法

如图,计算词汇嵌入,语言特定的转换和隐语义嵌入。
词汇嵌入(Lexical Embedding)
令(W_cin mathbb{R}^{C imes D}),其中,(D)为嵌入维度,(C)为词汇表中的(n)-gram大小,(W_c)在所有语言中共享。计算(w)的字符(n)-gram词袋,记作BoN((w))。如上图2,是词"puppy"当(n=1,2,3,4)时的(n)-gram。最终,计算词汇嵌入的公式如下:
其中,(W_c)为(C imes D)大小的嵌入矩阵。
特定语言转换(Language-specific Transformation)
特定语言转换主要是为了消除不同语言之间的拼写不同,比如“你好”和“hello”,拼写不同,但是含义相同。利用一个简单的全连接层进行这样的转换,对于语言(L_i),
其中,(W_{L_i}in mathbb{R}^{D imes D})是针对语言(L_i)的变换矩阵。
潜在语义嵌入(latent Semantic Embedding)
主要是为了建模不同语言间共享的语义,这里又用到一个嵌入矩阵(W_sin mathbb{R}^{S imes D}),其中,(S)是假设一个语言可以表达核心语义的数量。和词汇嵌入矩阵(W_c)一样,语义嵌入矩阵(W_S)也在不同语言之间共享。在这一部分,使用一种简单的注意力机制计算潜在语义嵌入:
其中,(c_i(w))为上述对于词(w)的特定语言转换向量。
最后,为了简化模型优化,将特定语言转换向量(c_i(w))作为跳连加入到(e_{latent}(w))中,也就是对于词(w)的软解耦编码为:
实验
在该文实验没有什么好说的,使用的是几个较低和较高数据资源的数据集。如下:
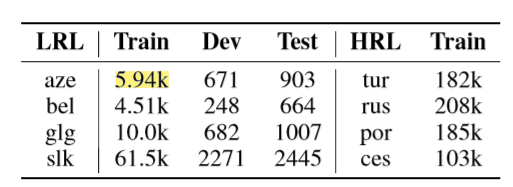
其中,aze、bel等均为语种代号,LRL表示低数据资源语料,HRL表示高数据资源语料。
A Compact and Language-Sensitive Multilingual Translation Method
在多语种机器翻译模型中,兼顾参数共享的同时,引入语言敏感嵌入、注意力和判别器,以增强模型表现。如下图。
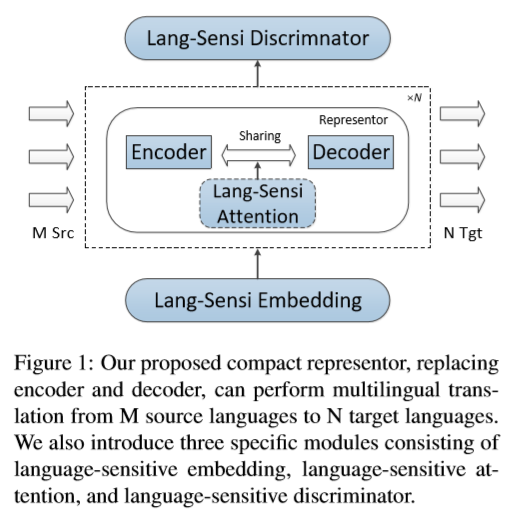
一个统一的特征表征器
骨架仍然是Transformer,self-attention、feed-forward和normalization模块权重共享,共享的表征器参数记作( heta_{rep}),因此损失函数为:
其中,(L)是平行语料的对数,(P(y_t^l|x^l,y^l_{<t}; heta))表示第(l)个平行语料对的第(d)句话的第(t)个词的翻译概率(the probability of t-th word of the d-th sentence in l-th translation pair)。
语种敏感模块
- 语种敏感嵌入
该文中,对每个token加上一个表征语种的嵌入向量,该嵌入矩阵记作(E_{lang}in mathbb{R}^{|K|*d_{model}}),其中,(K)为参与训练的语种数量,(d_{model})为模型中隐向量的维度。
- 语种敏感注意力
在Transformer中,除了自注意力之外,还有一个用于桥接编码器和解码器的跨注意力(cross-attention),这种注意力用于解码器选择最相关的编码器输入。该文的所谓“语种敏感注意力”,就是每个语种都有各自对应的跨注意力参数。
- 语种敏感判别器
使用一个神经网络(f_{dis})在表征器(h_{top}^{rep})的顶层,神经网络的输出就是一个语种的判别分数(P_{lang})。
其中,对于句子对(d)的语种判别分为(P_{lang}(d)),(W_{dis},b_{dis})均为参数,可以统一记作( heta_{dis})。在这里可以采用两种神经网络:带有最大池化的卷积和两层全连接层。因此,可以获得判别目标函数:
其中,(mathbb{I}{cdot})为指示函数,(g_d)属于语种(k)。
因此整个多语种机器翻译模型的损失函数为:
其中,(lambda)是预先定义的,用于平衡翻译任务和语种判别任务的平衡系数。

Parameter Sharing Methods for Multilingual Self-Attentional Translation Models
一个单语种机器翻译模型如果不加修改地训练为多语种模型,所有模型参数直接在多个语种之间共享,通常会导致准确率的下降。该文就是在Transformer模型的基础上,讨论多语种机器翻译模型的参数共享策略。实验发现,所有参数共享的方法,带来BLEU的提升主要是因为目标语言属于相似的语言族(language family),而如果目标语言属于不同的语言族中,所有参数共享则会带来显著的BLEU的降低。
代码地址:multilingual_nmt
简介
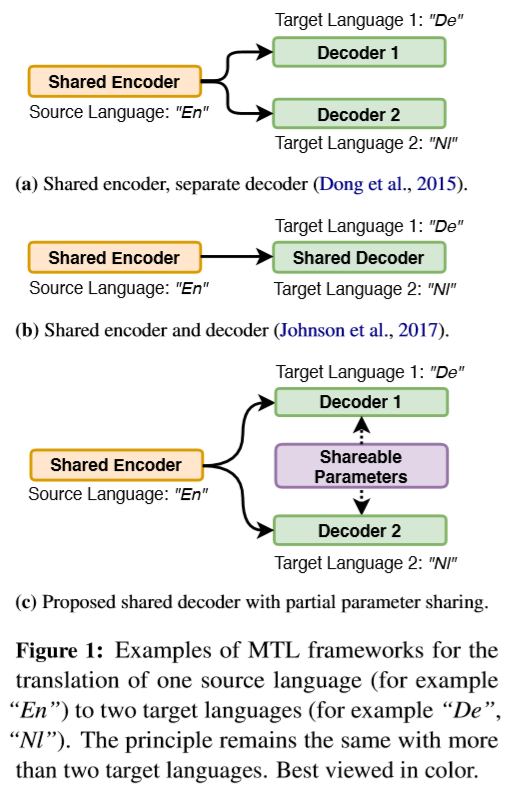
一翻多机器翻译任务是多语种机器翻译的典型任务,如上图1,之前的多任务学习(Multi-Task Learning,MTL)模型有两种方法:(a)一个共享编码器和每个语种特定的解码器,这种方法优势在于能够针对每一个目标语言建模,但缺陷也很明显,就是训练速度减慢,并且增加内存要求。(b)一个统一的,对所有语言对共享的编解码器,优点在于无论多少语种,参数量恒定,但这种方法大大加重了解码器的负担。因此该文中提出了一种折中方案:(c)一个共享编码器和部分参数共享的解码器。因此,选择哪些参数共享成为最重要的问题。
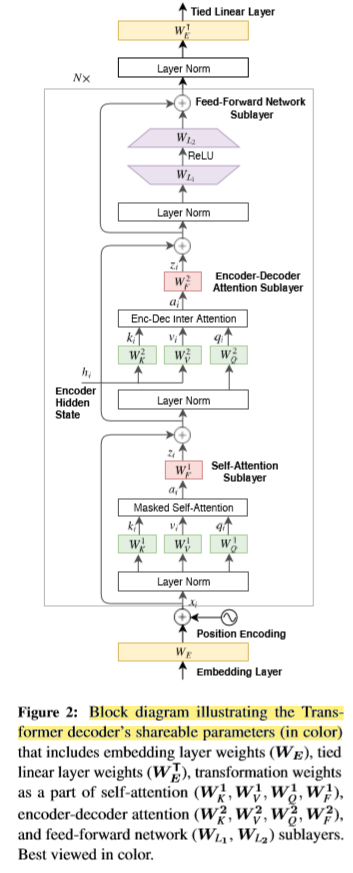
参数共享策略
将共享参数的集合记作(Theta),则:
-
共享前馈网络(Fully-Forward Network,FFN)参数,也即:(Theta={W_E, heta_{ENC},W_{L_1},W_{L_2}})
-
共享自注意力层的参数,也即:(Theta={W_E, heta_{ENC},W_K^1,W_Q^1,W_V^1,W_F^1})
-
共享编解码器注意力参数,也即:(Theta={W_E, heta_{ENC},W_K^2,W_Q^2,W_V^2,W_F^2})
-
注意力参数的共享仅仅局限在key和query的权重参数((Theta={W_E, heta_{ENC},W_K^1,W_Q^1,W_K^2,W_Q^2}))或者key和value的权重参数((Theta={W_E, heta_{ENC},W_K^1,W_V^1,W_K^2,W_V^2}))。这样做的主要动机是,共享的注意力层可以建模目标语言的相似信息,而独立的前馈层参数则可以建模各个语言之间的不同方面。
-
共享解码器的所有参数。
上述各种策略的实验结果如下:
- 目标语言均属同一语言族的一翻多(one-to-many)翻译。
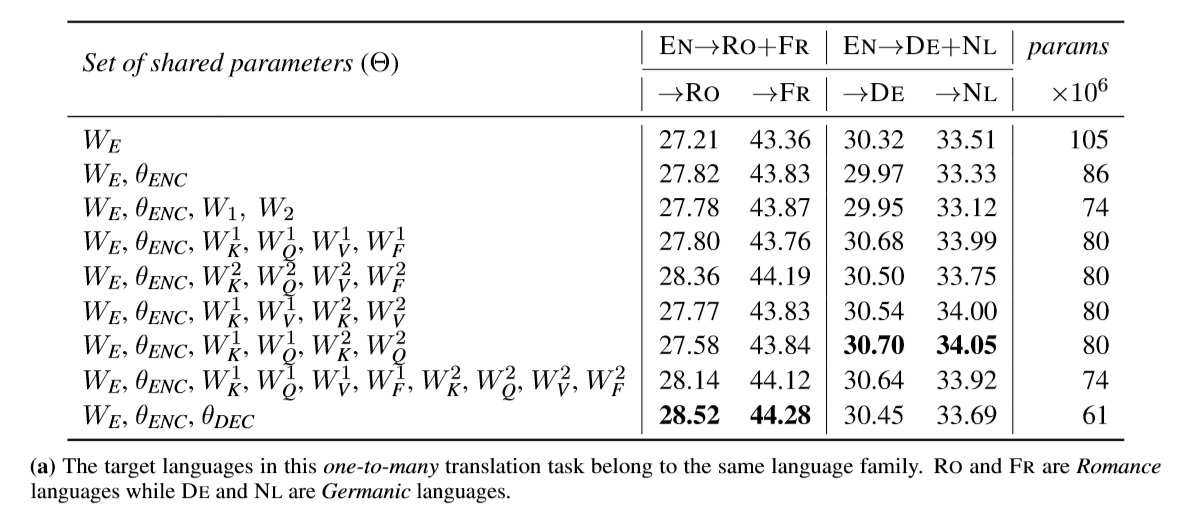
一些结论:
-
仅仅共享嵌入层效果最差;
-
共享编码器参数在有些任务上可以获得较好的提升,有些不行;
-
共享编解码器注意力的key-query或者key-value权重参数,可以带来一个较为平衡的表现;
-
共享编解码器注意力全部参数,或者编码器-注意力-解码器参数全部共享,有时可以带来最优表现。
- 目标语言属于不同语言族的一翻多(one-to-many)翻译。
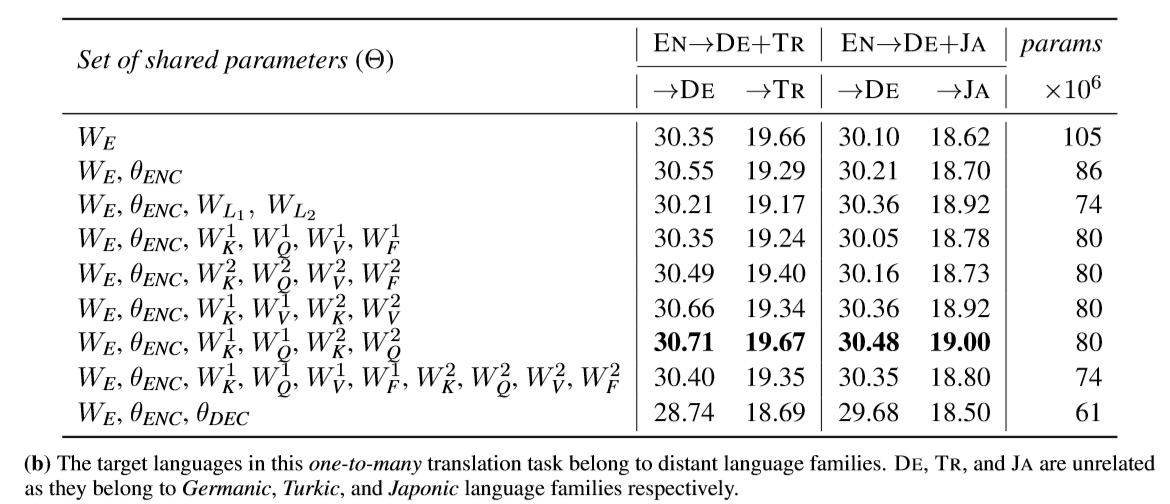
一些结论:
-
在目标语言属于不同语言族的实验中,共享编解码器的全部参数将会带来非常明显的BLEU分数下降,表现降低明显;
-
共享编码器和解码器的key-query的权重参数可以有效建模各语言的普遍共性,而各语言独立的前馈层可以建模各语言的特性,这种策略在该任务中取得最好的表现。
- 当然也做了一个整体的比较,在GNMT和Transformer上,不共享(No Sharing)、全部共享(Full Sharing),共享部分(Partial Sharing)参数的表现。其中,共享部分参数指的是共享嵌入层,编码器和编解码器的key-value权重参数。这里不明白,上面一张图明明共享编解码器的key-query权重参数的效果最好,在这里做整体比较却是用了共享编解码器的key-value权重系数。
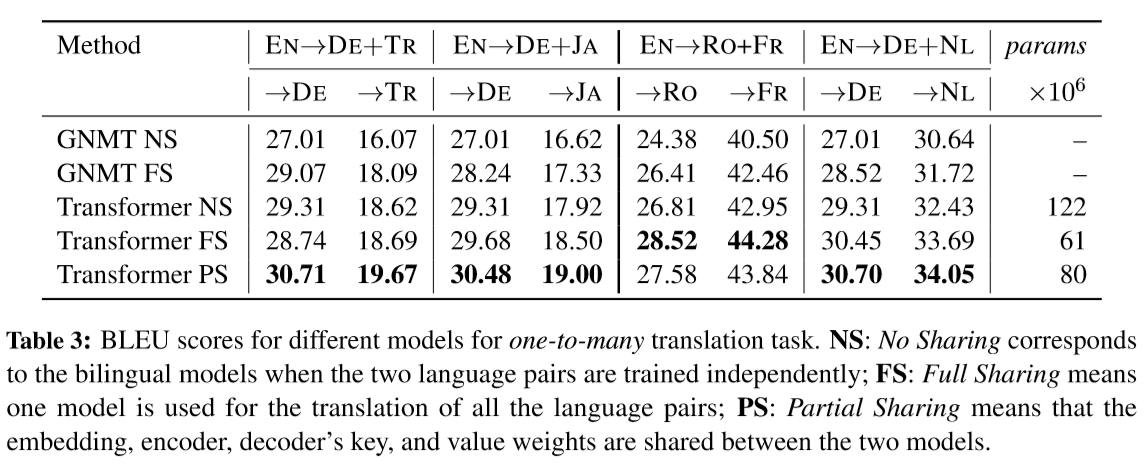
当然,部分参数共享的方法都能取得比较好的表现。有时候目标语言是相同语言族时,参数全共享可以得到比较好的BLEU值。
Contextual Parameter Generation for Universal Neural Machine Translation
和上面一篇讨论多语种机器翻译的参数共享不同,该文新增一个部件上下文参数生成器(Contextual Parameter Generator,CPG)为编解码器生成参数,该参数生成器输入是语言嵌入(Language Embeddings)张量,输出语言特定的模型参数,其余部分保持不变。该方法使得单一的统一模型在多个语言间进行互翻时,利用同样的网络结构,但使用语言特定的参数(language specific parameterization)。该方法同样可以用于领域自适应和零次学习等方面。
使用该方法进行多语种语音合成的代码地址:Multilingual_Text_to_Speech
简介
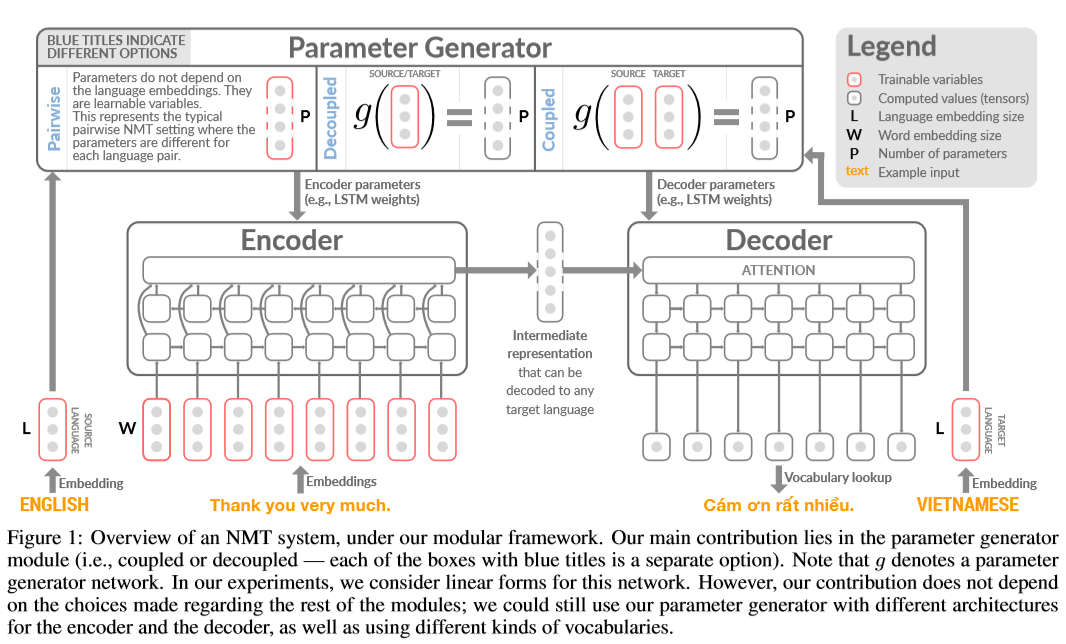
对一个给定的句子对,源语言记作(l_s),目标语言记作(l_t)。当使用上下文参数生成器(Contextual Parameter Generator)时,将编码器的参数记作( heta^{(enc)}=g^{(enc)}(I_s)),其中,(g^{(enc)})为编码器参数生成函数,(I_s)记作语言(l_s)的语言嵌入张量。相似地,( heta^{(dec)}=g^{(dec)}(I_t))为函数(g^{(dec)})使用语言(I_t)的语言嵌入张量(I_t)作为输入,为解码器生成参数。在该文的实验中,参数生成器被定义为一个简单的线性变换,并且在浅层网络中不使用偏置项:
其中,(I_s,I_tin mathbb{R}^M,W^{(enc)}in mathbb{R}^{P(enc) imes M},W^{(dec)}in mathbb{R}^{P(dec) imes M}),(M)是语言嵌入维度,(P^{(enc)})是编码器的参数数量,(P^{(dec)})是解码器的参数数量。当然该文并没有限制参数生成器的具体形式。由上式可以看出,该模型也可看作对参数的低阶约束(参见原文3.2节的具体解释)。
总结
本文主要讨论了机器翻译,特别是多语种机器翻译的进展。可以看到,实际上不加任何修改,利用多语种语料训练单语种翻译模型,也有可以立即将其转变为多语种翻译模型,这种方法的优点在于没有增加任何参数量,而且在语言族相同的情况下效果蛮好,缺点在于会给模型带来极大的负担。因此,有较多的方法在参数共享方面疯狂试探,一方面最大限度地共用语言特性无关的模块,另一方面加入一些能够表达语言特性的模块或者信息。
最后,推荐一份机器翻译论文列表。
清华大学机器翻译小组的推荐论文列表:MT-Reading-List