1、UTF-32
先来看简单的 UTF-32
这个就是字符所对应编号的整数二进制形式,四个字节。这个就是直接转换。 比如马的 Unicode 为:U+9A6C,那么直接转化为二进制,它的表示就为:1001 1010 0110 1100。
这里需要说明的是,转换成二进制后计算机存储的问题,我们知道,计算机在存储器中排列字节有两种方式:大端法和小端法,大端法就是将高位字节放到底地址处,比如 0x1234, 计算机用两个字节存储,一个是高位字节 0x12,一个是低位字节 0x34,它的存储方式为下:
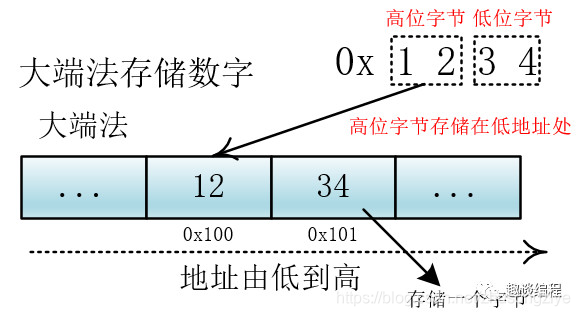
UTF-32 用四个字节表示,处理单元为四个字节(一次拿到四个字节进行处理),如果不分大小端的话,那么就会出现解读错误,比如我们一次要处理四个字节 12 34 56 78,这四个字节是表示 0x12 34 56 78 还是表示 0x78 56 34 12?不同的解释最终表示的值不一样。
我们可以根据他们高低字节的存储位置来判断他们所代表的含义,所以在编码方式中有 UTF-32BE 和 UTF-32LE,分别对应大端和小端,来正确地解释多个字节(这里是四个字节)的含义。
2、UTF-16
UTF-16 使用变长字节表示
① 对于编号在 U+0000 到 U+FFFF 的字符(常用字符集),直接用两个字节表示。
② 编号在 U+10000 到 U+10FFFF 之间的字符,需要用四个字节表示。
同样,UTF-16 也有字节的顺序问题(大小端),所以就有 UTF-16BE 表示大端,UTF-16LE 表示小端。
3、UTF-8
UTF-8 就是使用变长字节表示,顾名思义,就是使用的字节数可变,这个变化是根据 Unicode 编号的大小有关,编号小的使用的字节就少,编号大的使用的字节就多。使用的字节个数从 1 到 4 个不等。
UTF-8 的编码规则是:
① 对于单字节的符号,字节的第一位设为 0,后面的7位为这个符号的 Unicode 码,因此对于英文字母,UTF-8 编码和 ASCII 码是相同的。
② 对于n字节的符号(n>1),第一个字节的前 n 位都设为 1,第 n+1 位设为 0,后面字节的前两位一律设为 10,剩下的没有提及的二进制位,全部为这个符号的 Unicode 码 。
举个例子:比如说一个字符的 Unicode 编码是 130,显然按照 UTF-8 的规则一个字节是表示不了它(因为如果是一个字节的话前面的一位必须是 0),所以需要两个字节(n = 2)。
根据规则,第一个字节的前 2 位都设为 1,第 3(2+1) 位设为 0,则第一个字节为:110X XXXX,后面字节的前两位一律设为 10,后面只剩下一个字节,所以后面的字节为:10XX XXXX。
所以它的格式为 110XXXXX 10XXXXXX 。
下面我们来具体看看具体的 Unicode 编号范围与对应的 UTF-8 二进制格式
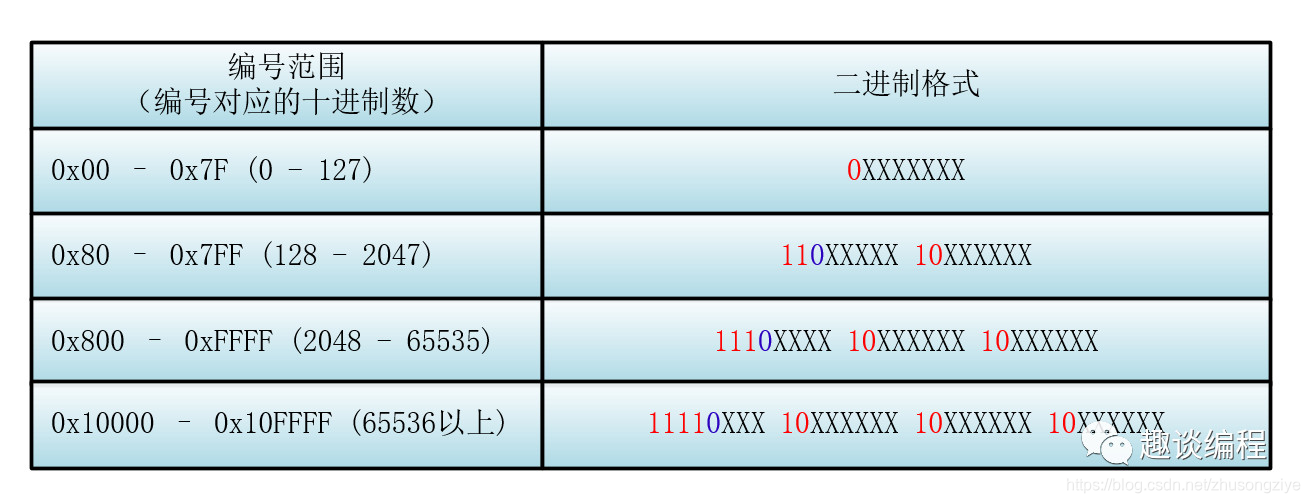
那么对于一个具体的 Unicode 编号,具体怎么进行 UTF-8 的编码呢?
首先找到该 Unicode 编号所在的编号范围,进而可以找到与之对应的二进制格式,然后将该 Unicode 编号转化为二进制数(去掉高位的 0),最后将该二进制数从右向左依次填入二进制格式的 X 中,如果还有 X 未填,则设为 0 。
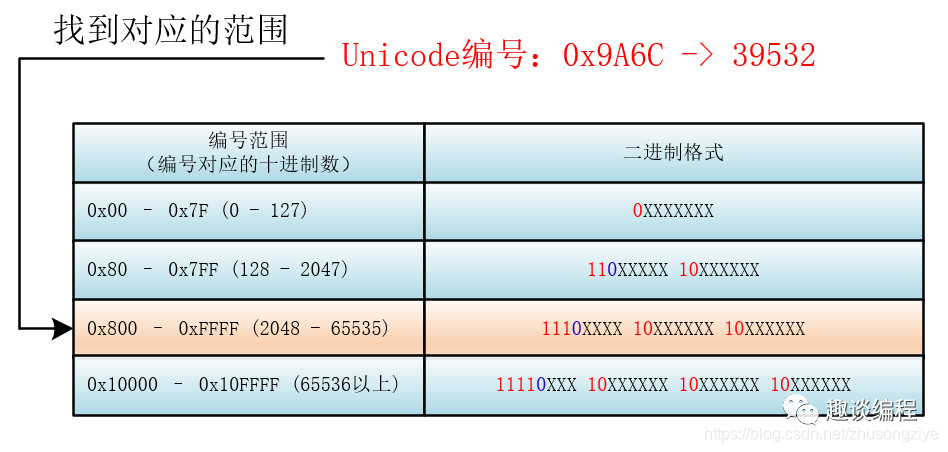
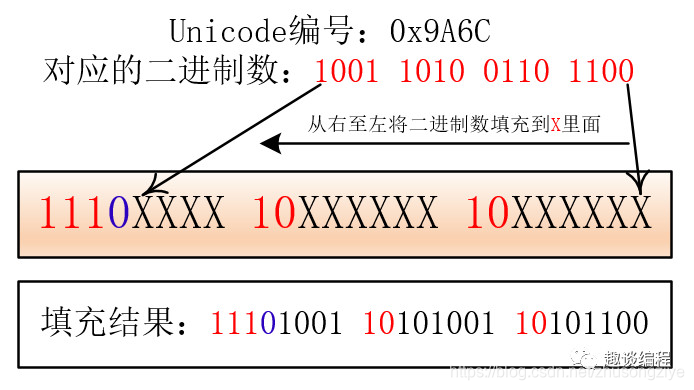
比如:“马”的 Unicode 编号是:0x9A6C,整数编号是 39532,对应第三个范围(2048 - 65535),其格式为:1110XXXX 10XXXXXX 10XXXXXX,39532 对应的二进制是 1001 1010 0110 1100,将二进制填入进入就为:
11101001 10101001 10101100 。
由于 UTF-8 的处理单元为一个字节(也就是一次处理一个字节),所以处理器在处理的时候就不需要考虑这一个字节的存储是在高位还是在低位,直接拿到这个字节进行处理就行了,因为大小端是针对大于一个字节的数的存储问题而言的。
综上所述,UTF-8、UTF-16、UTF-32 都是 Unicode 的一种实现。
原链接:https://blog.csdn.net/zhusongziye/article/details/84261211