Redis在windows下的环境搭建
下载windows版本redis,,官方下载地址:http://redis.io/download,
不过官方没有Windows版本,官网只提供linux版本的下载,目前有个开源的托管在github上, 地址:https://github.com/MicrosoftArchive/redis/tags
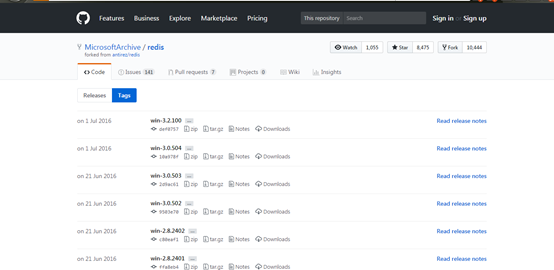

上面提供了两种安装方式,一种是解压版,一种是安装版;
图简单省事可以选择安装版,选择解压版为了达到和安装板一样的效果,还得自己去加环境变量,去进行各种设置。

选择安装目录,打钩会帮你添加安装路径的环境变量

选择服务开启的端口号,打钩选择让防火墙放过对这个端口的限制;
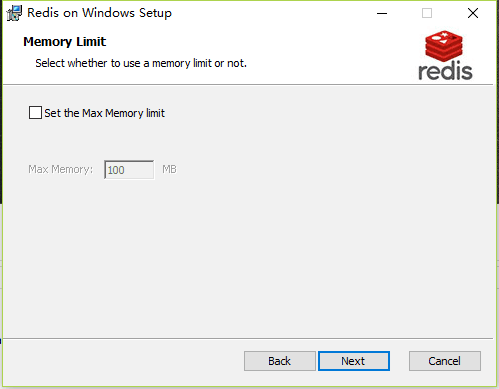
指定Redis最大内存限制,Redis在启动时会把数据加载到内存中,达到最大内存后,Redis会先尝试清除已到期或即将到期的Key,当此方法处理后,仍然到达最大内存设置,将无法再进行写入操作,但仍然可以进行读取操作。
Redis存在vm机制,如果打开后,在上面的情况下会把Key存放内存,Value会存放在swap区。
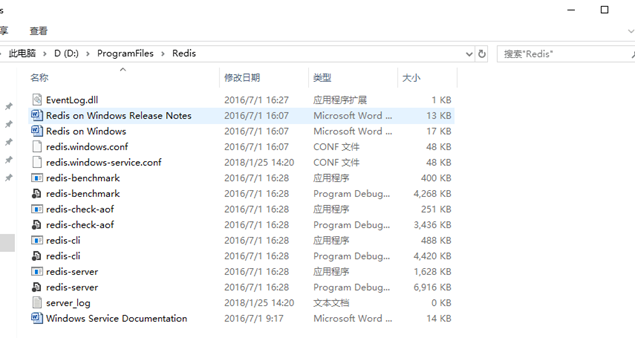
以上是安装好以后的目录
|
文件名 |
简要 |
|
redis-benchmark.exe |
基准测试 redis-benchmark为redis性能测试工具 |
|
redis-check-aof.exe |
aof AppendOnly File的缩写,是Redis系统提供的一种记录Redis操作的持久化方案 |
|
redischeck-dump.exe |
dump redis的备份和还原,借助了第三方的工具,redis-dump |
|
redis-cli.exe |
客户端 |
|
redis-server.exe |
服务器 |
|
redis.windows.conf |
配置文件 |
在redis.windows.conf文件中设置redis密码,在这里:# requirepass foobared
比如设置密码 test

requirepass test
如果你需要其他机器连接这台机器的redis服务器的话,需要注释掉 #bind 127.0.0.1
双击redis-server.exe,弹出如下界面,可以启动redis。

但是关掉这个UI后,redis也会随之停止,可以采取以redis后台服务的这种方法运行:

选中redis服务,右键启动;
这里有个坑,如果你通过双击redis-server.exe方式访问,redis读取的是redis.windows.conf中的配置信息;
如果你以服务的方式启动,redis读取的是redis.windows-service.conf中的配置信息,你需要重新在redis.windows-service.conf中配置是否绑定ip,以及密码等,
否则就会出现127.0.0.1可以访问,但是通过本机ip却不能访问的现象;
安装redis数据库可视化工具,这里安装 RedisDesktopManager,软件地址:https://github.com/uglide/RedisDesktopManager/releases


下载下来以后,一路next安装,打开软件

测试一下:
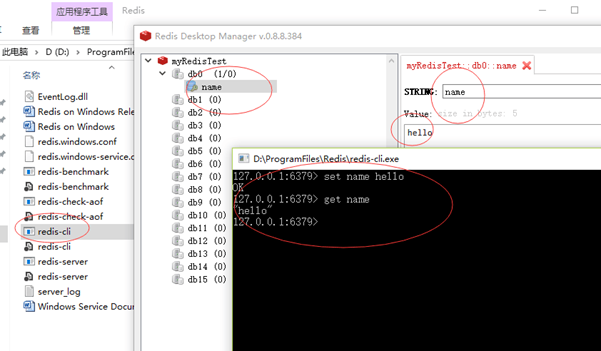
双击redis-cli.exe打开redis客户端,存一个key 为name ,value为hello的值进redis,然后取一下,能获取到值,在图形化工具内部,打开连接的redis实例,也能看到刚才存放的值;说明环境搭建成功!
Redis的配置信息在redis.windows.conf文件中,可以根据自己的需要进行修改;
1. Redis默认不是以守护进程的方式运行,默认daemonize no,可以通过该配置项修改,使用yes启用守护进程,不过windows上不支持 daemonize no;
2.指定Redis监听端口,默认端口为6379,作者在自己的一篇博文中解释了为什么选用6379作为默认端口,因为6379在手机按键上MERZ对应的号码,而MERZ取自意大利歌女Alessia Merz的名字
port 6379
3.绑定的主机地址
bind 127.0.0.1
绑定后只能该ip访问redis,不绑定可以注释掉;
4. 当客户端闲置多长时间后关闭连接,如果指定为0,表示关闭该功能
timeout 0
5. 指定日志记录级别,Redis总共支持四个级别:debug、verbose、notice、warning,默认为verbose,logfile为日志名字
loglevel verbose
logfile ""
6.设置数据库的数量,默认使用数据库为0,可以使用SELECT <dbid>命令在连接上指定数据库;
databases 16
7.指定在多长时间内,有多少次更新操作,就将数据同步到数据文件,可以多个条件配合;
save <seconds> <changes>
Redis默认配置文件中提供了三个条件:
save 900 1
save 300 10
save 60 10000
分别表示900秒(15分钟)内有1个更改,300秒(5分钟)内有10个更改以及60秒内有10000个更改。
8. 指定存储至本地数据库时是否压缩数据,默认为yes,Redis采用LZF压缩,如果为了节省CPU时间,可以关闭该选项,但会导致数据库文件变的巨大
rdbcompression yes
9. 指定本地数据库文件名,默认值为dump.rdb
dbfilename dump.rdb
10. 指定本地数据库存放目录
dir ./
11. 设置当本机为slav服务时,设置master服务的IP地址及端口,在Redis启动时,它会自动从master进行数据同步
slaveof <masterip> <masterport>
12. 当master服务设置了密码保护时,slav服务连接master的密码
masterauth <master-password>
13. 设置同一时间最大客户端连接数,默认无限制
# maxclients 10000
14. 指定Redis最大内存限制,Redis在启动时会把数据加载到内存中,达到最大内存后,Redis会先尝试清除已到期或即将到期的Key,当此方法处理后,仍然到达最大内存设置,将无法再进行写入操作,但仍然可以进行读取操作。Redis新的vm机制,会把Key存放内存,Value会存放在swap区
maxmemory <bytes>
15. 如果Redis是只用于内存缓存,不做任何持久化,这时背后AOF/RDB的fork()机制就没必要了;作为一个优化,所有的持久化操作可以在redis的windows版本上被关掉;选择 no 后,不持久数据,数据在服务终止后将消失,此模式下也将不存在"数据恢复"的手段
# persistence-available [(yes)|no]
16. Redis中采取了AOF/RDB两种手段来直接或者间接的持久化数据;
在数据恢复时,如果开启了AOF,那么服务器端将优先使用AOF文件恢复数据,否则才会使用snapshot的RDB文件来恢复数据。
1.AOF
AOF保存了历史所有的操作过程,我们可以简单的认为AOF就是日志文件,此文件只会记录"变更操作"(例如:set/del等),如果server中持续的大量变更操作,将会导致AOF文件非常的庞大,意味着server失效后,数据恢复的过程将会很长;事实上,一条数据经过多次变更,将会产生多条AOF记录,其实只要保存当前的状态,历史的操作记录是可以抛弃的;因为AOF持久化模式还伴生了"AOF rewrite"。
当server需要数据恢复时,可以直接replay此日志文件,即可还原所有的操作过程。AOF相对可靠,它和mysql中bin.log、apache.log、zookeeper中txn-log简直异曲同工。AOF文件内容是字符串,非常容易阅读和解析,它和redis-protocol具有一样的格式约束:
##此选项为aof功能的开关,默认为"no",可以通过"yes"来开启aof功能
##只有在"yes"下,aof重写/文件同步等特性才会生效
appendonly no
##指定aof文件名称
appendfilename appendonly.aof
##指定aof操作中文件同步策略,有三个合法值:always everysec no,默认为everysec
always:每一条aof记录都立即同步到文件,这是最安全的方式,也以为更多的磁盘操作和阻塞延迟,是IO开支较大。
everysec:每秒同步一次,性能和安全都比较中庸的方式,也是redis推荐的方式。如果遇到物理服务器故障,有可能导致最近一秒内aof记录丢失(可能为部分丢失)。
no:redis并不直接调用文件同步,而是交给操作系统来处理,操作系统可以根据buffer填充情况/通道空闲时间等择机触发appendfsync everysec
##在aof-rewrite期间,appendfsync是否暂缓文件同步,"no"表示"不暂缓","yes"表示"暂缓",默认为"no"
no-appendfsync-on-rewrite no
##aof文件rewrite触发的最小文件尺寸(mb,gb),只有大于此aof文件大于此尺寸是才会触发rewrite,默认"64mb",建议"512mb"
auto-aof-rewrite-min-size 64mb
##相对于"上一次"rewrite,本次rewrite触发时aof文件应该增长的百分比。
##每一次rewrite之后,redis都会记录下此时"新aof"文件的大小(例如A),那么当aof文件增长到A*(1 + p)之后
##触发下一次rewrite,每一次aof记录的添加,都会检测当前aof文件的尺寸。
auto-aof-rewrite-percentage 100
2. snapshots(RDB);
快照,这种思想被广泛的应用在多个技术领域,主要目的就是对当前数据的状态进行保存到文件中。redis中snapshot最终将内存数据序列化到dump.rdb文件中。
snapshot的主要目的,就是"数据备份",比如每隔12小时备份一次数据,并把snapshot生成的rdb文件保存起来,我们可以根据rdb文件将数据恢复到任意时间点上。此外rdb文件也是作为master-slave中数据同步的一种手段,一个slave加入集群,那么master(也可以是其他"领导者",--slaveof指定)将会立即执行一次"例外"的snapshot,并把snapshot期间的新变更操作收集起来(buffer),snapshot结束后,将rdb文件直接转发给slave,同时把收集的新变更操作依次同步给slave。(SYNC指令)
AOF和snapshot各有优缺点,这是有它们各自的特点所决定:
1) AOF更加安全,可以将数据更加及时的同步到文件中,但是AOF需要较多的磁盘IO开支,AOF文件尺寸较大,文件内容恢复数度相对较慢。
2) snapshot,安全性较差,它是"正常时期"数据备份以及master-slave数据同步的最佳手段,文件尺寸较小,恢复数度较快。
可以通过配置文件来指定它们中的一种,或者同时使用它们(不建议同时使用),或者全部禁用,在架构良好的环境中,master通常使用AOF,slave使用snapshot,主要原因是master需要首先确保数据完整性,它作为数据备份的第一选择;slave提供只读服务(目前slave只能提供读取服务),它的主要目的就是快速响应客户端read请求;但是如果你的redis运行在网络稳定性差/物理环境糟糕情况下,建议你master和slave均采取AOF,这个在master和slave角色切换时,可以减少"人工数据备份"/"人工引导数据恢复"的时间成本;如果你的环境一切非常良好,且服务需要接收密集性的write操作,那么建议master采取snapshot,而slave采用AOF。
1) 如果master失效,那么slave可以人工的方式"提升"为master:
Java代码收藏代码
redis 127.0.0.1:6379> config set appendonly yes
OK
redis 127.0.0.1:6379> BGREWRITEAOF
Background append only file rewriting started
redis 127.0.0.1:6379> SLAVEOF no one
OK
当然可以通过slaveof指令为当前server指定master。提升master的过程,首先开启slave的AOF功能,然后立即执行bgrewriteaof,然后将此slave提升为master。
如果此slave与master之间数据存在很大差异,那么需要把master中的aof文件copy一份到slave中,并重启slave:首先开启slave的appendonly,不执行bgrewriteaof,然后提升master,停止slave,将master的aof文件copy到slave中,然后重启slave。
2) 如果slave失效,这个非常好办,直接重启就行,slave重启后,会首先向master发送"SYNC"指令,那么master将会立即生成一份snapshot文件,并传输给slave,slave根据此snapshot文件恢复内存数据。
3) 在redis中master和slave的角色切换非常简单,可以通过指令将slaveof提升为master,反之亦然;事实上slave也可以接受write操作,只不过这些write操作,在和master进行"SYNC"之后,将会消失;建议将slave作为read-only模式。
4) 在redis中AOF和snapshot可以同时使用,但是在数据恢复时AOF会被优先采用,因为AOF比snapshot中数据更加完整。
参考:http://www.runoob.com/redis/redis-conf.html
http://blog.csdn.net/javahongxi/article/details/54578542
http://blog.csdn.net/erlian1992/article/details/54382443