在上一小节的学习中,我们解决了python解析器输出汉字乱码的问题。但是一些关于编码的概念并没有解析清楚。这一小节,将继续学习字符编码的知识。
先提出以下问题:
1.什么是字符编码?
2.什么是ACSII编码?
3.什么是Unicode编码?
4.什么是UTF-8编码?
5.什么是cp950编码?
在开始之前我们需要先理解什么是编码?
在一些电影情节中,我们经常会看到某个活动于“地下的英雄们”在做一些不法活动时,通常用手电的“明,灭”或者“在空中画个大圈圈”来向对方传递某种不为人知的信息。在这里手电的明灭就是一种信息编码,传递了双方事先约定好的信息,比如“亮-灭--亮-灭”表示危险取消交易,“画个大圈圈”表示OK,安全可以交易。
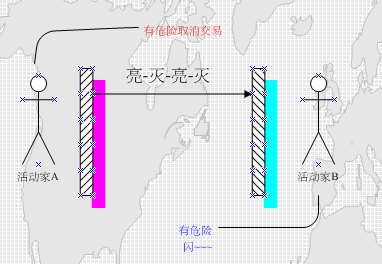
图1
从图1我们可以知道,把信息以事先约定好的规则(编码原则)转化为另一种方式(方便使用工具传播比如手电的光信号),这就是对信息编码。
A把信息“有危险取消交易”的信息转换为手电信号“亮-灭-亮-灭”这个过程是编码(encode)。
B收到信号“亮-灭-亮-灭”根据事先约定的信息把这个信号翻译为“有危险取消交易”这个过程是解码(decode)。
再更进一步学习字符编码前,先学习下字符在内存中的存储。在X86CPU计算机实现中规定(X86表示CPU指令集,详细信息参考维基百科条目):
8位二进制代码称为一个字节(byte)。
双字节16位二进制代码表示为一个字(word)。
双字32位二进制代码表示为双倍字(dword)。
4个字64位二进制代码表示为四倍字(qword)。
字节是计算存储的最小单位,也是内存地址编码的最小单位。操作系统为内存单元也就是为每个字节指定一个值,这就是我们在上一节中使用id()可以输出的内容。
而在数据存储上又有“大小端之分”。

0A是最高有效位,存储在内存的低地址位,这称为大端序。
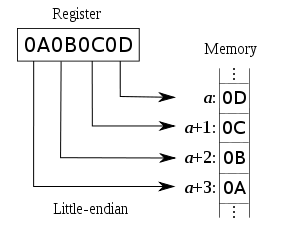
0A是最高有效位,存储在内存的高地址,这称为小端序。
(上图来源维基百科,参考文末链接)
我们都知道在计算机内部CPU执行的指令都是01二进制代码,如果计算机只能输入和输出01代码,阅读起来太过痛苦也不便于计算机的推广使用,于是ASCII编码就被开发出来,用01序列来表示我们人类可以识别的自然语言。
ASCII(American Standard Code for Information Interchange 美国信息交换标准代码)采用了一个字节来编码英文世界的信息。
具体来说只使用了低7位(第八位也就是最高位默认为0,第一位又称为最低位),127个字符就满足了英文编码的需要。

图2

图3来源于维基百科
0~32和第127个位置,总共33个控制字符,控制字符不会在终端(显示器)上显示主要用来实现特殊的目的,比如换行和退格。
在编程中经常使用的是第10个字符换行和第十三个回车键(enter键)。这个一部分符号历史可以追溯那种古老的机械打印机。
余下94个字符都是可以显示字符,其中48~57表示数字0~9,第65~90表示大写字母‘A’~‘Z’,第97~122表示小写字母'a'~'z'
(更容易阅读的ASCII表见文末)
随着计算机在全世界范围内广泛使用,ASCII不能满足更广范围的编码需求,比如汉字的编码,目前的GB2312汉字编码是使用两个字节来实现汉字的编码的,
理论上可以实现256*256 = 65536个汉字。但是目前统计说有10万汉字,要想实现这么多的汉字编码就需要使用Unicode编码,当然在存储上会占用更多的字节。
Unicode用来解决全世界范围内的字符编码问题。Unicode像ASCII一样只是定义了二进制字符序列与字符的对照关系。
我们测试下一个汉字采用ASCII编码和Unicode会有什么区别。
在windows记事本,中输入汉字“万”,分别另存为,ANSI编码,Unicode编码,Unicode bigendian编码和UTF-8编码。
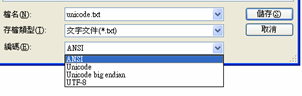
然后是用UltaEdit的切换16进制模式查看。
汉字 “万” ANSI编码:C9 45 Unicdoe编码: FF FE 07 4E Unicode Bigendian:FE FF 4E 07 UTF-8: EF BB BF E4 B8 87
(这例子学习自阮一峰的blog,阮大师举例为“严”,这里采用“万”字,是为了自己学习,链接见文末)
“万”的Unicode的编码可以在“Unicode与汉字对照表”查到是“4E07”说明对照表中编码是Big endian的。
记事本中的Unicode是采用little endian方式存储的,双字节的UCS2实现。
Unicode规范中定义,每一个文件的最前面分别加入一个表示编码顺序的字符,这个字符的名字叫做"零宽度非换行空格"(ZERO WIDTH NO-BREAK SPACE),用FEFF表示。这正好是两个字节,而且FF比FE大1。 如果一个文本文件的头两个字节是FE FF,就表示该文件采用大头方式;如果头两个字节是FF FE,就表示该文件采用小头方式。(摘自阮一峰blog)
UTF-8以EF,BB,BF开头表示文档的编码格式,实际上“万”字的UTF-8表示为:E4 B8 87
通过上面的例子我们可以看到UTF-8与Unicode编码不同,UTF-8是Unicode的一种实现方式。UTF-8编码采用了变长的字节存储比Unicode节省空间,且兼容ASCII字符,是目前网络最通用的一种编码方式。
在我们最后的一个问题中的cp950是“操作系统实现的字符集”,这个在windows中表示繁体字符集。
在python2.7中已经支持了Unicode字符集,在不同的字符集之间切换需要借助utf-8编码为中间码做转换,然后再转换为目标字符集。
print(msg.decode("utf-8").encode("950"))
参考资料:
字符编码
http://zh.wikipedia.org/zh-cn/%E5%AD%97%E7%AC%A6%E7%BC%96%E7%A0%81
ASCII
http://zh.wikipedia.org/wiki/ASCII
32位元
http://zh.wikipedia.org/wiki/32%E4%BD%8D
unicode与汉字对照表
http://www.chi2ko.com/tool/CJK.htm
unicode
http://zh.wikipedia.org/wiki/Unicode
关于大端和小端
http://zh.wikipedia.org/wiki/%E5%AD%97%E8%8A%82%E5%BA%8F
UTF-8
http://zh.wikipedia.org/wiki/UTF-8
阮一峰blog
http://www.ruanyifeng.com/blog/2007/10/ascii_unicode_and_utf-8.html
以下表格整理在维基百科
| 二进制 | 十六进制 | 十进制 | 缩写 | Unicode | 脱出字符 | 名称/意义 |
| 表示法 | 表示法 | |||||
| 0000 0000 | 0 | 0 | NUL | ␀ | ^@ | 空字符(Null) |
| 0000 0001 | 1 | 1 | SOH | ␁ | ^A | 标题开始 |
| 0000 0010 | 2 | 2 | STX | ␂ | ^B | 本文开始 |
| 0000 0011 | 3 | 3 | ETX | ␃ | ^C | 本文结束 |
| 0000 0100 | 4 | 4 | EOT | ␄ | ^D | 传输结束 |
| 0000 0101 | 5 | 5 | ENQ | ␅ | ^E | 请求 |
| 0000 0110 | 6 | 6 | ACK | ␆ | ^F | 确认回应 |
| 0000 0111 | 7 | 7 | BEL | ␇ | ^G | 响铃 |
| 0000 1000 | 8 | 8 | BS | ␈ | ^H | 退格 |
| 0000 1001 | 9 | 9 | HT | ␉ | ^I | 水平定位符号 |
| 0000 1010 | 0A | 10 | LF | ␊ | ^J | 换行键 |
| 0000 1011 | 0B | 11 | VT | ␋ | ^K | 垂直定位符号 |
| 0000 1100 | 0C | 12 | FF | ␌ | ^L | 换页键 |
| 0000 1101 | 0D | 13 | CR | ␍ | ^M | Enter键 |
| 0000 1110 | 0E | 14 | SO | ␎ | ^N | 取消变换(Shift out) |
| 0000 1111 | 0F | 15 | SI | ␏ | ^O | 启用变换(Shift in) |
| 0001 0000 | 10 | 16 | DLE | ␐ | ^P | 跳出数据通讯 |
| 0001 0001 | 11 | 17 | DC1 | ␑ | ^Q | 设备控制一(XON 激活软件速度控制) |
| 0001 0010 | 12 | 18 | DC2 | ␒ | ^R | 设备控制二 |
| 0001 0011 | 13 | 19 | DC3 | ␓ | ^S | 设备控制三(XOFF 停用软件速度控制) |
| 0001 0100 | 14 | 20 | DC4 | ␔ | ^T | 设备控制四 |
| 0001 0101 | 15 | 21 | NAK | ␕ | ^U | 确认失败回应 |
| 0001 0110 | 16 | 22 | SYN | ␖ | ^V | 同步用暂停 |
| 0001 0111 | 17 | 23 | ETB | ␗ | ^W | 区块传输结束 |
| 0001 1000 | 18 | 24 | CAN | ␘ | ^X | 取消 |
| 0001 1001 | 19 | 25 | EM | ␙ | ^Y | 连接介质中断 |
| 0001 1010 | 1A | 26 | SUB | ␚ | ^Z | 替换 |
| 0001 1011 | 1B | 27 | ESC | ␛ | ^[ | 退出键 |
| 0001 1100 | 1C | 28 | FS | ␜ | ^\ | 文件分区符 |
| 0001 1101 | 1D | 29 | GS | ␝ | ^] | 组群分隔符 |
| 0001 1110 | 1E | 30 | RS | ␞ | ^^ | 记录分隔符 |
| 0001 1111 | 1F | 31 | US | ␟ | ^_ | 单元分隔符 |
| 0111 1111 | 7F | 127 | DEL | ␡ | ^? | 删除 |
| 二进制 | 十六进制 | 十进制 | 图形 |
| 0010 0000 | 20 | 32 | (空格,␠) |
| 0010 0001 | 21 | 33 | ! |
| 0010 0010 | 22 | 34 | " |
| 0010 0011 | 23 | 35 | # |
| 0010 0100 | 24 | 36 | $ |
| 0010 0101 | 25 | 37 | % |
| 0010 0110 | 26 | 38 | & |
| 0010 0111 | 27 | 39 | ' |
| 0010 1000 | 28 | 40 | ( |
| 0010 1001 | 29 | 41 | ) |
| 0010 1010 | 2A | 42 | * |
| 0010 1011 | 2B | 43 | + |
| 0010 1100 | 2C | 44 | , |
| 0010 1101 | 2D | 45 | - |
| 0010 1110 | 2E | 46 | . |
| 0010 1111 | 2F | 47 | / |
| 0011 0000 | 30 | 48 | 0 |
| 0011 0001 | 31 | 49 | 1 |
| 0011 0010 | 32 | 50 | 2 |
| 0011 0011 | 33 | 51 | 3 |
| 0011 0100 | 34 | 52 | 4 |
| 0011 0101 | 35 | 53 | 5 |
| 0011 0110 | 36 | 54 | 6 |
| 0011 0111 | 37 | 55 | 7 |
| 0011 1000 | 38 | 56 | 8 |
| 0011 1001 | 39 | 57 | 9 |
| 0011 1010 | 3A | 58 | : |
| 0011 1011 | 3B | 59 | ; |
| 0011 1100 | 3C | 60 | < |
| 0011 1101 | 3D | 61 | = |
| 0011 1110 | 3E | 62 | > |
| 0011 1111 | 3F | 63 | ? |
| 0100 0000 | 40 | 64 | @ |
| 0100 0001 | 41 | 65 | A |
| 0100 0010 | 42 | 66 | B |
| 0100 0011 | 43 | 67 | C |
| 0100 0100 | 44 | 68 | D |
| 0100 0101 | 45 | 69 | E |
| 0100 0110 | 46 | 70 | F |
| 0100 0111 | 47 | 71 | G |
| 0100 1000 | 48 | 72 | H |
| 0100 1001 | 49 | 73 | I |
| 0100 1010 | 4A | 74 | J |
| 0100 1011 | 4B | 75 | K |
| 0100 1100 | 4C | 76 | L |
| 0100 1101 | 4D | 77 | M |
| 0100 1110 | 4E | 78 | N |
| 0100 1111 | 4F | 79 | O |
| 0101 0000 | 50 | 80 | P |
| 0101 0001 | 51 | 81 | Q |
| 0101 0010 | 52 | 82 | R |
| 0101 0011 | 53 | 83 | S |
| 0101 0100 | 54 | 84 | T |
| 0101 0101 | 55 | 85 | U |
| 0101 0110 | 56 | 86 | V |
| 0101 0111 | 57 | 87 | W |
| 0101 1000 | 58 | 88 | X |
| 0101 1001 | 59 | 89 | Y |
| 0101 1010 | 5A | 90 | Z |
| 0101 1011 | 5B | 91 | [ |
| 0101 1100 | 5C | 92 | \ |
| 0101 1101 | 5D | 93 | ] |
| 0101 1110 | 5E | 94 | ^ |
| 0101 1111 | 5F | 95 | _ |
| 0110 0000 | 60 | 96 | ` |
| 0110 0001 | 61 | 97 | a |
| 0110 0010 | 62 | 98 | b |
| 0110 0011 | 63 | 99 | c |
| 0110 0100 | 64 | 100 | d |
| 0110 0101 | 65 | 101 | e |
| 0110 0110 | 66 | 102 | f |
| 0110 0111 | 67 | 103 | g |
| 0110 1000 | 68 | 104 | h |
| 0110 1001 | 69 | 105 | i |
| 0110 1010 | 6A | 106 | j |
| 0110 1011 | 6B | 107 | k |
| 0110 1100 | 6C | 108 | l |
| 0110 1101 | 6D | 109 | m |
| 0110 1110 | 6E | 110 | n |
| 0110 1111 | 6F | 111 | o |
| 0111 0000 | 70 | 112 | p |
| 0111 0001 | 71 | 113 | q |
| 0111 0010 | 72 | 114 | r |
| 0111 0011 | 73 | 115 | s |
| 0111 0100 | 74 | 116 | t |
| 0111 0101 | 75 | 117 | u |
| 0111 0110 | 76 | 118 | v |
| 0111 0111 | 77 | 119 | w |
| 0111 1000 | 78 | 120 | x |
| 0111 1001 | 79 | 121 | y |
| 0111 1010 | 7A | 122 | z |
| 0111 1011 | 7B | 123 | { |
| 0111 1100 | 7C | 124 | | |
| 0111 1101 | 7D | 125 | } |
| 0111 1110 | 7E | 126 | ~ |