可能会遇到这样的场景
比如你有 N 个 cache 服务器(后面简称 cache ),那么如何将一个对象 object 映射到 N 个 cache 上呢,你很可能会采用类似下面的通用方法计算 object 的 hash 值,然后均匀的映射到到 N 个 cache :
hash(object)%N
如果增加一个cache,映射公式变成了 hash(object)%(N+1)
如果一个cache宕机了,映射公式变成了 hash(object)%(N-1)
在这两种情况下,几乎所有的 cache 都失效了。会导致数据库访问的压力陡增,严重情况,还可能导致数据库宕机。
一致性hash算法正是为了解决此类问题的方法,它可以保证当机器增加或者减少时,对缓存访问命中的概率影响减至很小。
一致性Hash环
通常的 hash 算法都是将 value 映射到一个 32 位的 key 值,也即是 0~2^32-1 次方的数值空间;我们可以将这个空间想象成一个首( 0 )尾( 2^32-1 )相接的圆环
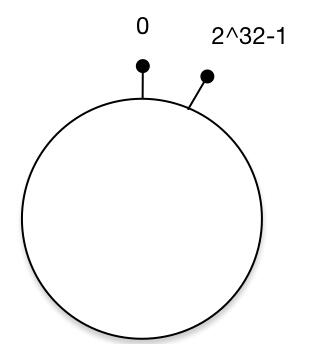
将对象映射到hash环上
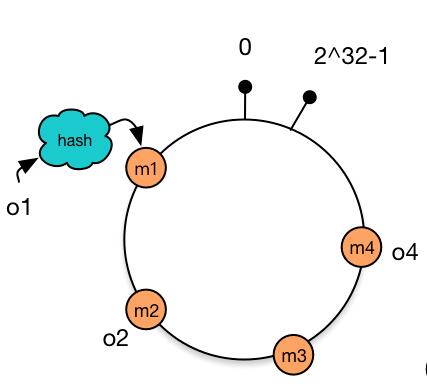
将cache 映射到hash环上
可以使用 cache 机器的 IP 地址或者机器名作为 hash 输入
把对象映射到cache
在这个环形空间中,如果沿着顺时针方向从对象的 key 值出发,直到遇见一个 cache ,那么就将该对象存储在这个 cache 上,因为对象和 cache 的 hash 值是固定的,因此这个 cache 必然是唯一和确定的。
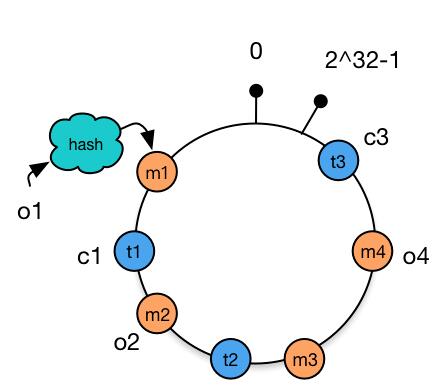
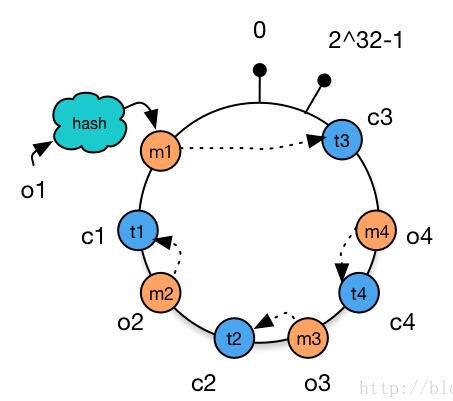
增加cache
使用简单的求模方法,当新添加机器后会导致大部分缓存失效的情况,使用一致性hash算法后这种情况则会得到大大的改善。
如下图,只有对象o4被重新分配到了c4,其他对象仍在原有机器上。
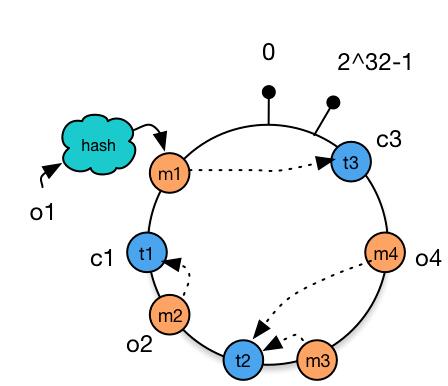
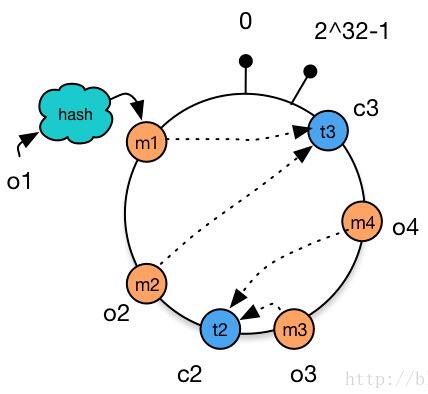
减少cache
只有对象o2被重新分配到机器c3,其他对象仍在原有机器上。
虚拟节点
哈希的结果能够尽可能分布到所有的cache中去,这样可以使得所有的缓冲空间都得到利用。
如果 cache 较少的话,对象并不能被均匀的映射到 cache 上。
可能o1映射到缓存a上,o2,o3,o4映射到缓存c上。
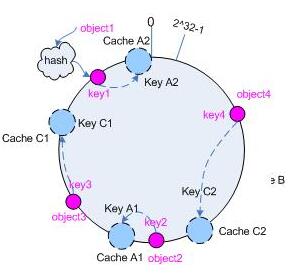
为了解决这种情况,需要引入虚拟节点的概念。
“虚拟节点”( virtual node )是实际节点在 hash 空间的复制品( replica ),一个实际节点对应了若干个“虚拟节点”。
如图,虚拟节点A1,A2都会映射到实际结点A上。
“虚拟节点”的 hash 计算可以采用对应节点的 IP 地址加数字后缀的方式。例如假设 cache A 的 IP 地址为 202.168.14.241 。
引入“虚拟节点”前,计算 cache A 的 hash 值:
Hash(“202.168.14.241”);
引入“虚拟节点”后,计算“虚拟节”点 cache A1 和 cache A2 的 hash 值:
Hash(“202.168.14.241#1”); // cache A1
Hash(“202.168.14.241#2”); // cache A2
参考:
https://blog.csdn.net/sparkliang/article/details/5279393
https://blog.csdn.net/lihao21/article/details/54193868