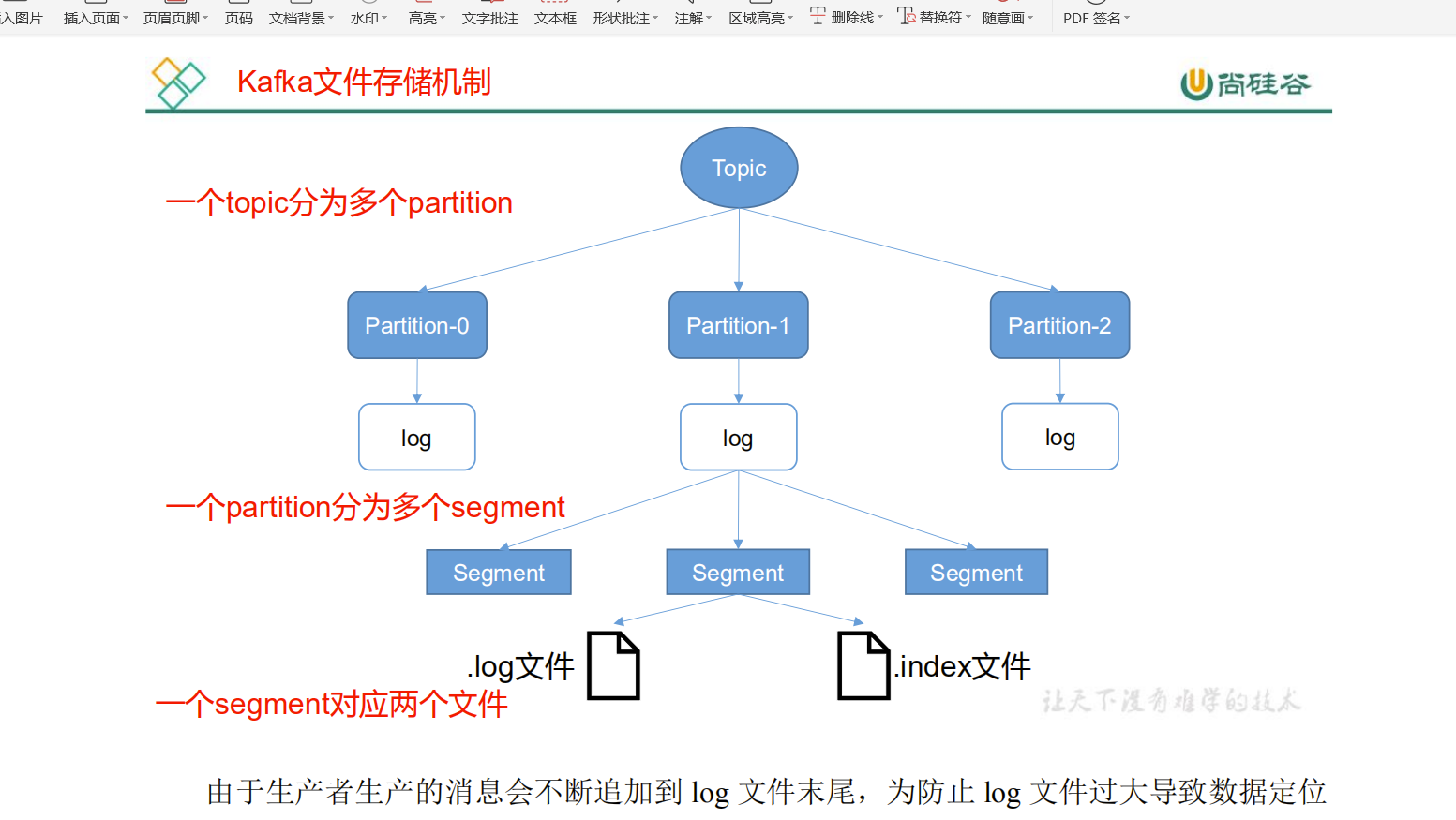
topic 是一个逻辑的概念 ,partition是一个物理的概念 ,每一个partition对应一个log文件
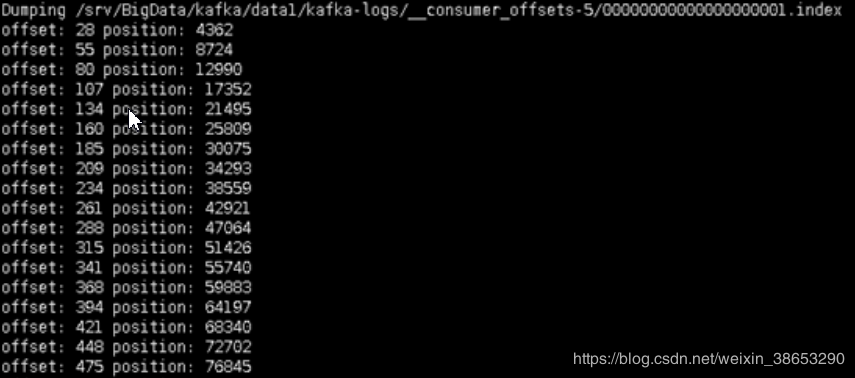
index文件的内容 , offset 值和 position 值
分区:
kafka分区的作用个人觉得就是提供一种负载均衡的能力
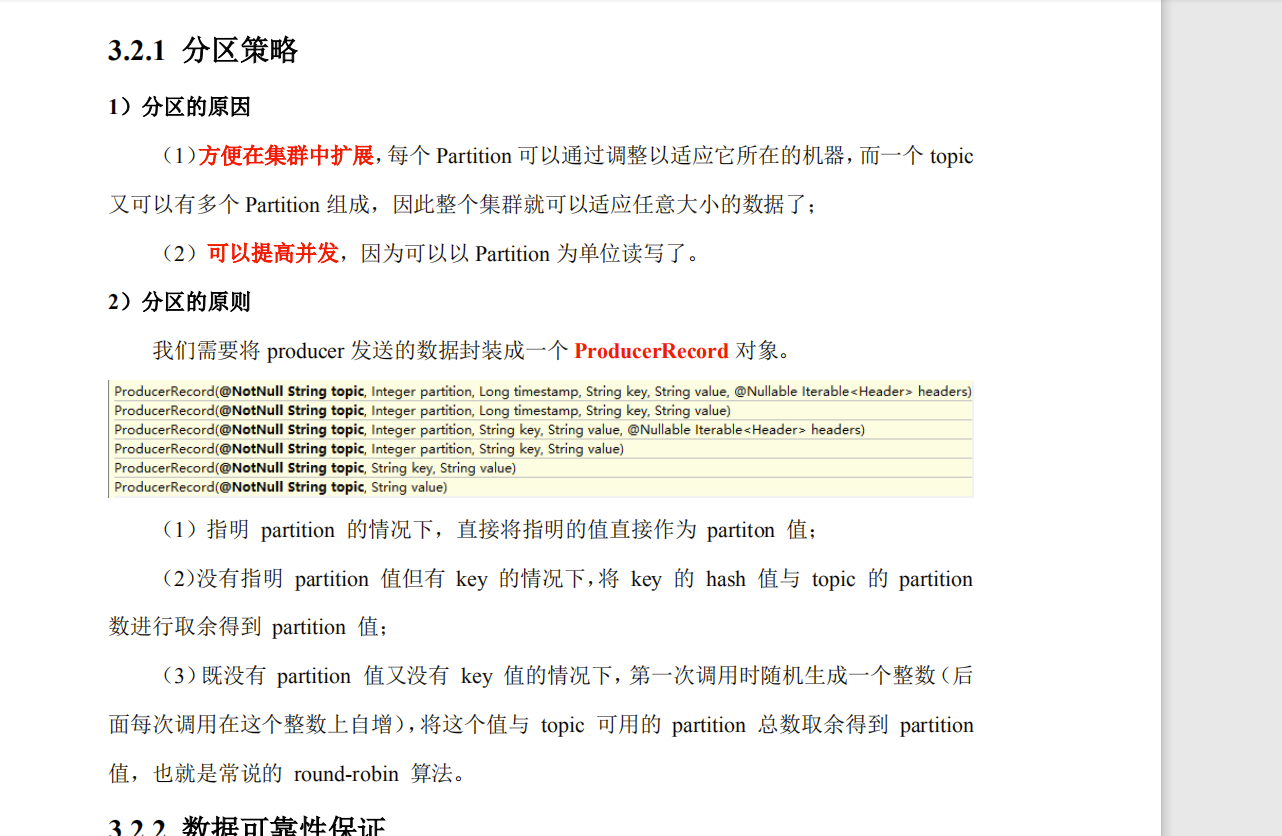
所谓分区策略是决定生产者将消息发送到哪个分区的算法
分区策略:
1. 轮询策略
也称 Round-robin 策略,即顺序分配。比如一个主题下有 3 个分区,那么第一条消息被发送到分区 0,第二条被发送到分区 1,第三条被发送到分区 2,以此类推。当生产第 4 条消息时又会重新开始,即将其分配到分区 0,就像下面这张图展示的那样。
2. 随机策略
也称 Randomness 策略。所谓随机就是我们随意地将消息放置到任意一个分区上,如下面这张图所示。
3. 按消息key 比如部门ID
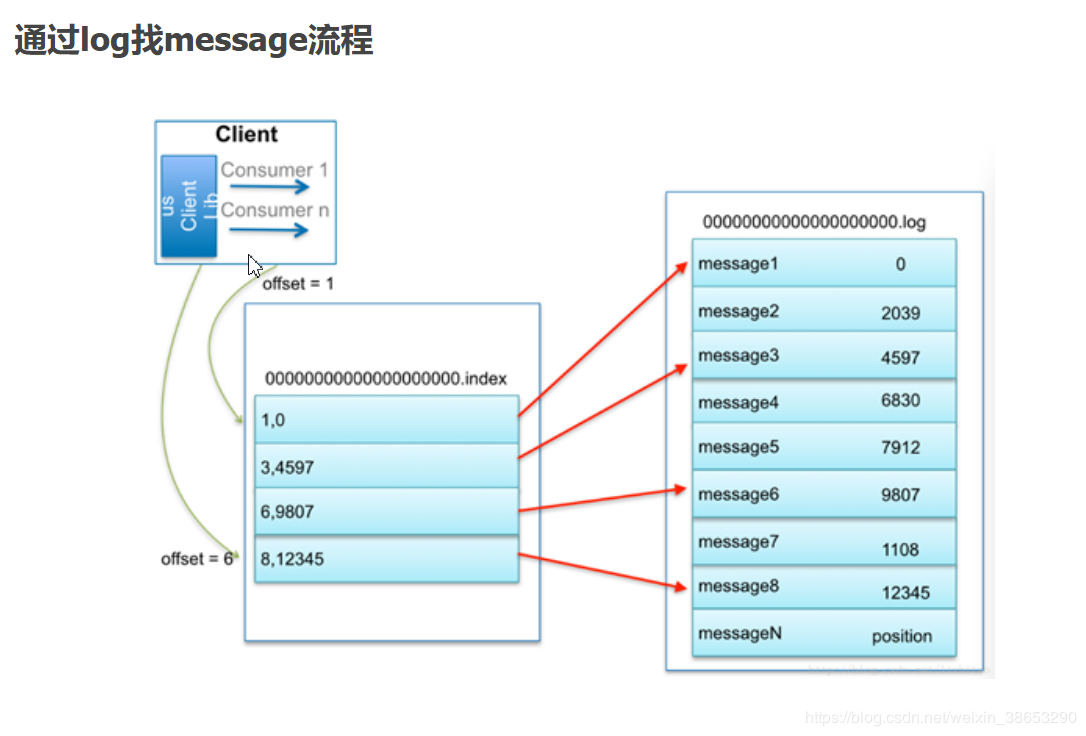
比如:要查找绝对offset为7的Message:
1、用二分查找确定它是在哪个LogSegment中,自然是在第一个Segment中。
2、打开这个Segment的index文件,也是用二分查找找到offset小于或者等于指定offset的索引条目中最大的那个offset。自然offset为6的那个索引是我们要找的,通过索引文件我们知道offset为6的Message在数据文件中的位置为9807。
3、打开数据文件,从位置为9807的那个地方开始顺序扫描直到找到offset为7的那条Message。
————————————————
版权声明:本文为CSDN博主「从0到1哦」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_38653290/article/details/84864708
kafka 消息保证策略:
1. 卡夫卡的存储机制
每个partition对应一个log文件 ,log文件中存储的是producer生成的数据, produce 生成的数据不断追加到log的末端. 而且每条数据都有自己的offet ,
一个topic 对应多个parttion ,partition下面有多个log文件
2. 卡夫卡的分区策略
3 卡夫卡数据可靠性保证
Leader 维护了一个动态的ISR (in-sync-replica set )当isr中的follower 完成同步之后,leader就会给foller发送ack, 如果follower 长时间未发送同步信息, 则follower被踢出isr
ACK 的应答机制
对于不重要的信息,是容忍丢失的.
0 : Broker 一收到消息 还没写入磁盘 就返回ack消息. broker故障可能有丢失情况. ----不写 磁盘
1. producer 等待broker的ack ,当leader 写入磁盘数据后在返回ack , 如果在foller同步成功之前leader故障, 那么数据有可能丢失。 -----leader写磁盘
1-, 是说 partition的leader和follower全部落盘在返回ack。 如果foller同步完成 , broker发送ack之前,leader故障 ,会造成数据重复. -------follwer和leader都写磁盘.
4. Kafka选举leader机制
kafka在0.8.2版本开始采用了这种 选举方式
1)基于Controller的Leader Election
整个集群中选举出一个Broker作为Controller
Controller为所有Topic的所有Partition指定Leader及Follower
2)优点
极大缓解Herd Effect问题
减轻Zookeeper负载
Controller与Leader及Follower间通过RPC通信,高效且实时
3)缺点
引入Controller增加了复杂度
需要考虑Controller的Failover
总结:1、kafka利用zookeeper去选举出controller;2、kafka通过controller选指定出leader和follower,而无需通过zookeeper了。
5. kafka数据一致性问题。