CSS篇
1. CSS 盒子模型,绝对定位和相对定位?
① 盒模型
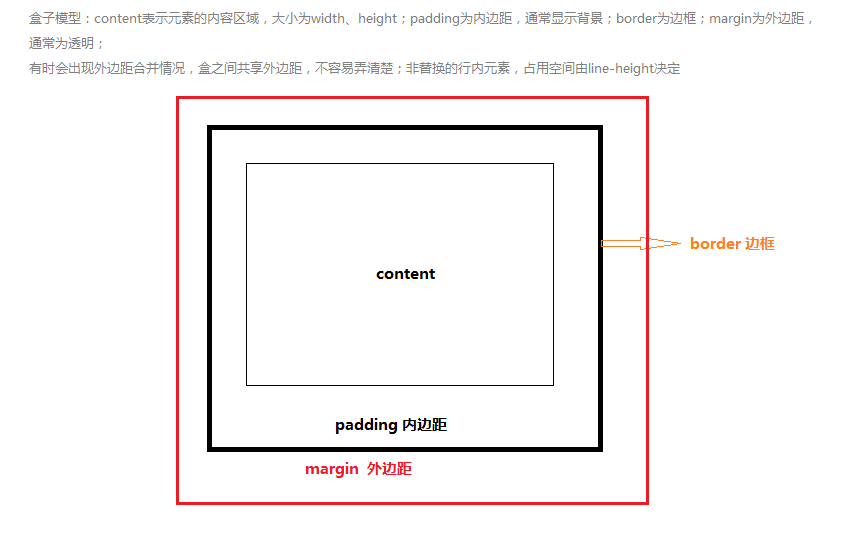
背景会应用于元素内容、内边距、边框三者组成的区域;
margin值可以设置为负值,很多情况下会需要使用margin负值;padding没有负数;
浏览器的兼容性:IE5.X 和 6 在怪异模式中使用自己的非标准模型。这些浏览器的 width 属性不是内容的宽度,而是内容、内边距和边框的宽度的总和。
目前最好的解决方案是回避这个问题。也就是,不要给元素添加具有指定宽度的内边距,而是尝试将内边距或外边距添加到元素的父元素和子元素
② 绝对定位和相对定位
position:absolute | relative | fixed | static | inherit
absolute:绝对定位;相对于除了static定位以外的第一个父元素进行定位;将元素从文档流中拖出来,不占用原来元素的空间,相对于其最接近的一个具有定位属性的父级元素进行绝对定位
relative:相对定位;生成相对定位的元素,相对于其正常位置进行定位。还是会占用该元素在文档中初始的页面空间。
fixed:固定定位;生成绝对定位的元素,相对于浏览器窗口进行定位。
static:默认值;
inherit:继承
绝对定位会隐式改变元素的display类型,同元素设置float:left | right;时一样,都会隐式将元素的display设置为inline-block;
但是float在IE6下的双边距bug就是用display:inline; 来解决的。
2. 清除浮动,什么时候需要清除浮动,清除浮动都有哪些方法?
浮动带来的影响——父元素高度塌陷了,此时就需要来清楚浮动
清除浮动的方法:
① 为父元素设置高度
为父元素定高,简单粗暴,但是网页制作中,很少出现高度height。因为盒子能被内容撑高!所以这种清除浮动的方法工作中用的很少
② 在父元素的最后设置clear:both
缺点 在页面中添加这么多没有意义的冗余元素,太麻烦,而且不符合语义化。
③ 伪元素
:after {
content:"";
display:table;
clear:both;
}
④ 给父元素添加overflow:hidden
可以了解下 BFC 块级格式化上下文
添加overflow: hidden就能清除浮动的工作原理是:
如果没有明确设定容器高情况下
它要计算内容全部高度才能确定在什么位置hidden
浮动的高度就要被计算进去
顺带达成了清理浮动的目标
同理
overflow 非默认值
position 非默认值
float 非默认值
等都是遵循这个布局计算思路
3. 如何保持浮层水平垂直居中
// 下面列举几种常用的 <div class="parent"> <div class="child">hello world-3</div> </div> ① 思路:子元素绝对定位,距离顶部50%,左边50%,然后使用css3 transform:translate(-50%,-50%) 优点:高大上,可以在webkit内核的浏览器中使用 缺点:不支持IE9以下 不支持transform属性 .parent { position: relative; height:300px; 300px; background: #FD0C70; } .parent .child { position: absolute; top: 50%; left: 50%; color: #fff; transform: translate(-50%, -50%); } ② 思路:使用css3 flex布局 优点:简单 快捷 缺点:兼容性不好 .parent { display: flex; justify-content: center; align-items: center; 300px; height:300px; background: #FD0C70; } .parent .child { color:#fff; } ③ 这个方法使用绝对定位的 div,把它的 top 设置为 50%,margin-top设置 为负的 content 高度。这意味着对象必须在 CSS 中指定固定的高度。 因为有固定高度,或许你想给 content 指定 overflow:auto,这样如果 content 太多的话,就会出现滚动条,以免content 溢出。 优点:适用于所有浏览器,不需要嵌套标签 缺点:没有足够空间时,content 会消失(类似div 在 body 内,当用户缩小 浏览器窗口,滚动条不出现的情况) .child { position: absolute; top: 50%; height: 240px; margin-top: -120px; /* 盒子本身高度的一半 */ } ④ 这个方法使用了一个 position:absolute,有固定宽度和高度的 div。这个 div 被设置为 top:0; bottom:0;。但是因为它有固定高度,其实并不能和 上下都间距为 0,因此 margin:auto; 会使它居中。使用 margin:auto;使 块级元素垂直居中是很简单的。 优点:简单粗暴,代码简单,其实设计者当初也根本没想到也能这样用,但是聪 明的大家硬是凿出了一条简单的路。 缺点:IE(IE8 beta)中无效。无足够空间时,content 被截断,但是不会有 滚动条出现 .child { position: absolute; top: 0; bottom: 0; left: 0; right: 0; margin: auto; height: 240px; 70%; }
参考 https://www.cnblogs.com/memphis-f/p/7349587.html
4. 样式的层级关系,选择器优先级,样式冲突,以及抽离样式模块怎么写,说出思路,有无实践经验
1、样式的层级关系:一个是权重,另一个就是共用样式和私用样式了,比如说两个ul,它们的子元素除了背景色之外都一样,那可以直接用li {}来定义相同的公用样式,用 .ul_1 li {} , .ul_2 li {} 来定义不相同的样式。可以根据元素之间的差别来选择用哪种方法。推荐用多层级的方式书写css选择器
2、选择器优先级:(!important>)id选择器>class选择器(属性选择器/伪类选择器)>标签选择器(伪元素选择器) 同类选择符条件下层级越多的优先级越高。优先级就近原则,同权重情况下样式定义最近者为准。载入样式以最后载入的定位为准。
3、样式冲突: 如果同个元素有两个或以上冲突的CSS规则,浏览器有一些基本的规则来决定哪一个非常特殊而胜出。
选择器一样的情况下后面的会覆盖前面的属性。
使用嵌套选择器时:
一组嵌套选择器的实际特性可以计算出来。基本的,使用ID选择器的值是100,使用class选择器的值是10,每个html选择器的值是1。它们加起来就可以计算出特性的值。
p的特性是1(一个html选择器)
div p的特性是2(两个html选择器)
.tree的特性是10(1个class选择器)
div p.tree的特性是1+1+10=12,(两个html选择器,一个class选择器)
#baobab的特性是100(1个ID选择器)
body #content .alternative p的特性是112(两个html选择器,一个ID选择器,一个类选择器)
基本上,一个选择器越多特性,样式冲突的时候将显示它的样式。
4、抽离样式模块
因为浏览器的兼容问题,不同浏览器对有些标签的默认值是不同的,如果没对CSS初始化往往会出现浏览器之间的页面显示差异。当然,初始化样式会对SEO有一定的影响,但鱼和熊掌不可兼得,但力求影响最小的情况下初始化。
最简单的初始化方法: * {padding: 0; margin: 0;} (强烈不建议)
body, h1, h2, h3, h4, h5, h6, hr, p, blockquote, dl, dt, dd, ul, ol, li, pre, form, fieldset, legend, button, input, textarea, th, td { margin:0; padding:0; }
body, button, input, select, textarea { font:12px/1.5tahoma, arial, 5b8b4f53; }
h1, h2, h3, h4, h5, h6{ font-size:100%; }
address, cite, dfn, em, var { font-style:normal; }
code, kbd, pre, samp { font-family:couriernew, courier, monospace; }
small{ font-size:12px; }
ul, ol { list-style:none; }
a { text-decoration:none; }
a:hover { text-decoration:underline; }
sup { vertical-align:text-top; }
sub{ vertical-align:text-bottom; }
legend { color:#000; }
fieldset, img { border:0; }
button, input, select, textarea { font-size:100%; }
table { border-collapse:collapse; border-spacing:0; }
6. css3动画效果属性,canvas、svg的区别,CSS3中新增伪类举例
动画参考: https://blog.csdn.net/songchunmin_/article/details/54646090
CSS3中新增伪类:https://blog.csdn.net/qq_41696819/article/details/81531494
7. px和em和rem的区别,CSS中link 和@import的区别是?
px和em和rem的区别
PX特点
-1. IE无法调整那些使用px作为单位的字体大小;
-2. 国外的大部分网站能够调整的原因在于其使用了em或rem作为字体单位;
-3. Firefox能够调整px和em,rem,但是有大部分的国产浏览器使用IE内核。
px像素(Pixel)。相对长度单位。像素px是相对于显示器屏幕分辨率而言的。(引自CSS2.0手册)
em是相对长度单位。相对于当前对象内文本的字体尺寸。如当前对行内文本的字体尺寸未被人为设置,则相对于浏览器的默认字体尺寸。(引自CSS2.0手册)
任意浏览器的默认字体高都是16px。所有未经调整的浏览器都符合: 1em=16px。那么12px=0.75em,10px=0.625em。为了简化font-size的换算,需要在css中的body选择器中声明Font-size=62.5%,这就使em值变为 16px*62.5%=10px, 这样12px=1.2em, 10px=1em, 也就是说只需要将你的原来的px数值除以10,然后换上em作为单位就行了。
EM特点
-1. em的值并不是固定的;
-2. em会继承父级元素的字体大小。
所以我们在写CSS的时候,需要注意两点:
-1. body选择器中声明Font-size=62.5%;
-2. 将你的原来的px数值除以10,然后换上em作为单位;
-3. 重新计算那些被放大的字体的em数值。避免字体大小的重复声明。
也就是避免1.2 * 1.2= 1.44的现象。比如说你在#content中声明了字体大小为1.2em,那么在声明p的字体大小时就只能是1em,而不是1.2em, 因为此em非彼em,它因继承#content的字体高而变为了1em=12px。
REM特点
rem是CSS3新增的一个相对单位(root em,根em),这个单位引起了广泛关注。这个单位与em有什么区别呢?区别在于使用rem为元素设定字体大小时,仍然是相对大小,但相对的只是HTML根元素。这个单位可谓集相对大小和绝对大小的优点于一身,通过它既可以做到只修改根元素就成比例地调整所有字体大小,又可以避免字体大小逐层复合的连锁反应。目前,除了IE8及更早版本外,所有浏览器均已支持rem。对于不支持它的浏览器,应对方法也很简单,就是多写一个绝对单位的声明。这些浏览器会忽略用rem设定的字体大小。下面就是
一个例子:
p {font-size:14px; font-size:.875rem;}
注意:
选择使用什么字体单位主要由你的项目来决定,如果你的用户群都使用最新版的浏览器,那推荐使用rem,如果要考虑兼容性,那就使用px,或者两者同时使用。
CSS中link 和@import的区别参考博客
https://www.cnblogs.com/my--sunshine/p/6872224.html
8. 了解过flex吗?
参考文档 Flex布局教程
JavaScript篇
1. JavaScript 里有哪些数据类型,解释清楚原始数据类型和引用数据类型解释清楚 null 和 undefined,。讲一下 1 和 Number(1)的区别
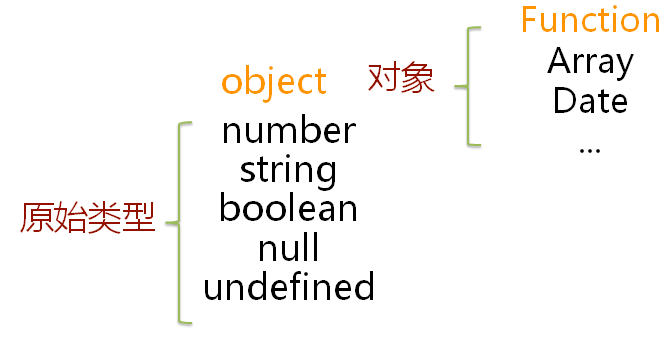
原始类型(基本类型):按值访问,可以操作保存在变量中实际的值。原始类型汇总中null和undefined比较特殊。
引用类型:引用类型的值是保存在内存中的对象。
undefeated和null:
Undefined类型
Undefined只有一个值,即特殊的undefined,使用var声明变量但未对其初始化时的值;
使用已声明但未初始化但变量,将得到“undefined”;使用未声明但变量,将会报错;
var message; //声明变量,但未初始化,默认值未undefined
alert(message); //弹出框将显示message但值,即“undefined
alert(age); //将产生错误
使用typeof操作符对已声明但未初始化的变量和尚未被声明的变量所返回的值均未“undefined”
var message;
alert(typeof message); //显示undefeated
alert(typeof age); //显示undefined
即使未初始化的变量会自动赋予undefined值,但仍然推荐显示但初始化变量,这样在使用typeof操作符返回“undefined”值时,就能知道被检测到的变量还未被声明,而不是尚未初始化;
Null类型
只有一个值,即特殊的null;
逻辑角度看,null值表示一个空对象指针,所以 “typeof null“ 返回的是“object”;
若定义的变量准备在将来用于保存对象,则推荐将该变量初始化为null,而不是其他值;
undefined值是派生自null值,所以“null == undefined“的值是true;
无论在什么情况下都没有必要吧一个变量显式的设置为undefined;只要意在保存对象的变量在还没有真正保存对象时都应该明确地设置为null值;
讲一下 1 和 Number(1)的区别
1是Number类型,是常量。
Number(1)是对1执行Number类包装,会对传入的参数去两侧空格,去掉引号,如果是纯数字,则返回纯数字,否则返回NaN
参考文档:
https://www.cnblogs.com/heluo/p/3237272.html
https://www.cnblogs.com/starof/p/6368048.html
2. 讲一下 prototype 是什么东西,原型链的理解,什么时候用 prototype
prototype是函数对象上面预设的对象属性
1.JS中所有的东西都是对象,每个对象都有prototype这个属性,这个属性是一个对象(object)
2.JS中所有的东西都由Object衍生而来, 即所有东西原型链的终点指向Object.prototype。如果还是再找不到,就返回null(Object.prototype.proto===null)
3.JS中构造函数和实例(对象)之间有微妙的关系,构造函数通过定义prototype来约定其实例的规格, 再通过 new 来构造出实例, 他们的作用就是生产对象。而构造函数(方法)本身又是方法(Function)的实例, 因此也可以查到它的__proto__(原型链)
Object / function F(){} 这样子的就是构造函数,一个是JS原生API提供的,一个是自定义的
new Object() / new F() 这样子的就是实例
实例就"只能"查看__proto__来得知自己是基于什么prototype被制造出来的,而"不能"再重新定义实例的prototype妄想创造出实例的实例了。
原型
是一个对象上面的原型,这个原型通常是它的构造器的prototype属性
原型链
function foo(){}; foo.prototype.z = 3; var obj = new foo();
通过new构造对象(实例)的特点是,obj的原型(prototype)指向了构造器的prototype属性,也就是foo.prototype,而foo.prototype则指向了原始的Object.prototype,Object.prototype也有原型,为null。这就是一整个原型链。
什么时候用 prototype
使用 prototype的好处是不会额外产生内存,所有实例化后的对象都会从原型上继承这个方法。也就是需要一个子类拥有父类的某些特性(同种特性可以覆盖),又可以添加自己的特性,而不会影响父类时候使用prototype。
Prototype通常用来解决一个问题:对象的创建比较耗费资源。比如,对象创建的时候需要访问数据库、需要读取外部文件、需要使用网络,这些都是比较耗费时间和内存的。如果可以用clone来解决,就方便多了。当需要创建很多 拥有相同属性的对象时候需要clone。
3. 函数里的this什么含义,什么情况下用
this是Javascript语言的一个关键字。它代表函数运行时,自动生成的一个内部对象,只能在函数内部使用。随着函数使用场合的不同,this的值会发生变化。但是有一个总的原则,那就是this指的是,调用函数的那个对象
情况一:纯粹的函数调用 这是函数的最通常用法,属于全局性调用,因此this就代表全局对象Global。 function test(){ this.x = 1; alert(this.x); } test(); // 1 为了证明this就是全局对象,我对代码做一些改变: var x = 1; function test(){ alert(this.x); } test(); // 1 运行结果还是1。再变一下: var x = 1; function test(){ this.x = 0; } test(); alert(x); //0 情况二:作为对象方法的调用 函数还可以作为某个对象的方法调用,这时this就指这个上级对象。 function test(){ alert(this.x); } var o = {}; o.x = 1; o.m = test; o.m(); // 1 情况三: 作为构造函数调用 所谓构造函数,就是通过这个函数生成一个新对象(object)。这时,this就指这个新对象。 function test(){ this.x = 1; } var o = new test(); alert(o.x); // 1 运行结果为1。为了表明这时this不是全局对象,对代码做一些改变: var x = 2; function test(){ this.x = 1; } var o = new test(); alert(x); //2 运行结果为2,表明全局变量x的值没变。 情况四: apply调用 apply()是函数对象的一个方法,它的作用是改变函数的调用对象,它的第一个参数就表示改变后的调用这个函数的对象。因此,this指的就是这第一个参数。 var x = 0; function test(){ alert(this.x); } var o={}; o.x = 1; o.m = test; o.m.apply(); //0 apply()的参数为空时,默认调用全局对象。因此,这时的运行结果为0,证明this指的是全局对象。 如果把最后一行代码修改为 o.m.apply(o); //1 运行结果就变成了1,证明了这时this代表的是对象o。
4. apply和 call 什么含义,什么区别?什么时候用。
call和apply都用于函数调用,和使用函数名直接调用不同,call和apply可以指定一个额外的参数作为函数体内的this对象。
由于call和apply可以改变函数体内的this指向,因此通常被用来将一个对象原型上的方法应用到另一个对象上。
参考文档:
https://www.cnblogs.com/nzbin/articles/9027036.html
5. 数组和对象有哪些原生方法,列举一下,分别是什么含义,比如连接两个数组用哪个方法,删除数组的指定项和重新组装数组(操作数据的重点)。
数组
- 若 a 小于 b,在排序后的数组中 a 应该出现在 b 之前,则返回一个小于 0 的值。
- 若 a 等于 b,则返回 0。
- 若 a 大于 b,则返回一个大于 0 的值。
1 var arr = [1, 2, 3]; 2 arr.concat(4, 5); // return [1, 2, 3, 4, 5] 3 arr.concat([4, 5]); // return [1, 2, 3, 4, 5] 4 arr.concat([4, 5], [6, 7]); // return [1, 2, 3, 4, 5, 6, 7] 5 arr.concat(4, [5, [6, 7]]); // return [1, 2, 3, 4, 5, [6, 7]]
1 [1, 2, 3].join(); // return "1,2,3"
1 [1, 2].forEach(function(value, index, array) {
2 console.log(value, index, array);
3 });
4 // return
5 // 1 0 [1, 2]
6 // 2 1 [1, 2]

1 try {
2 [1,2,3].forEach(function(val) {
3 console.log(val);
4 throw(e)
5 });
6 } catch(e) {
7 console.log(e);
8 }
1 [1, 2, 3].map(function(num) { // return [2, 3, 4]
2 return num + 1;
3 });
1 [1, 2, 3].filter(function(num) { // return [1]
2 return num < 2;
3 });
1 [1, 2, 3]. every(function(num) { // return false
2 return num > 1;
3 });
4 [1, 2, 3]. some(function(num) { // return true
5 return num > 2;
6 });
1 [1, 2, 3]. reduce(function(x, y) { // return 106
2 return x + y;
3 }, 100);
6. 怎样避免全局变量污染?ES5严格模式的作用,ES6箭头函数和ES5普通函数一样吗?
怎样避免全局变量污染?
方法一:只创建一个全局变量。
MYAPP.stooge = { "first-name": "Joe", "last-name": "Howard" };
方法二:使用闭包
//创建函数,返回一个特权对象 var f3 = function() { var age = 18; return { name: "啊哈", age: age, gender: "男" } }(); //获取变量 f3.name = "啊哈";
对于闭包,还有一个方法,就是使用匿名自执行函数,其实这货就是个如假包换的闭包,所有代码写在其中,在它内部声明的变量全部都是局部变量,一般用来写完全独立的脚本,比如jQuery,插件等。。。
(function() { //我在一个匿名自执行函数中 //some code here... })()
方法三:0全局变量
这个方法直接杜绝了全局变量,那就是不在全局声明变量(包括隐式声明全局变量);
ES5严格模式的作用,ES6箭头函数和ES5普通函数一样吗?
1、消除javascript语法的一些不合理、不严谨之处,减少一些怪异行为;
2、消除代码运行的一些不安全性,促进代码运行的安全;
3、提高编译器效率,增加运行速度;
4、为未来新版本的javascript做好铺垫
1)函数体内的this对象,就是定义时所在的对象,而不是使用时所在的对象。
(2)不可以当作构造函数,也就是说,不可以使用new命令,否则会抛出一个错误。
(3)不可以使用arguments对象,该对象在函数体内不存在。如果要用,可以用 rest 参数代替。
this对象的指向是可变的,但是在箭头函数中,它是固定的。
7. JS 模块包装格式都用过哪些,CommonJS、AMD、CMD。定义一个JS 模块代码,最精简的格式是怎样。
https://www.jianshu.com/p/bd4585b737d7
8. JS 怎么实现一个类。怎么实例化这个类。
严格的说,JavaScript 是基于对象的编程语言,而不是面向对象的编程语言。
在面向对象的编程语言中(如Java、C++、C#、PHP等),声明一个类使用 class 关键字。
例如:public class Person{}
但是在JavaScript中,没有声明类的关键字,也没有办法对类的访问权限进行控制。
JavaScript使用函数来定义类。
语法:
function className(){
// 具体操作
}
说明:this关键字是指当前的对象。
创建对象(类的实例化)
创建对象的过程也是类实例化的过程。
在JavaScript中,创建对象(即类的实例化)使用 new 关键字。
语法:
new className();
面向对象编程的基本概念
面向对象编程(Object Oriented Programming,OOP,面向对象程序设计) 的主要思想是把构成问题的各个事务分解成各个对象,建立对象的目的不是为了完成一个步骤,而是为了描叙一个事物在整个解决问题的步骤中的行为。
面向过程就是分析出解决问题所需要的步骤,然后用函数逐步实现,再依次调用就可以了。
面向对象与面向过程是两种不同的编程思想,没有哪一种方式绝对完美,需要根据程具体项目来定。比如,开发一个小的软件或网页,工程量小,短时间内就可完成,完全可以采用面向过程的开发方式,使用面向对象,反而会增加代码量,减缓运行效率。
面向过程的编程语言(如C语言)不能创建类和对象,不能用面向对象的方式来开发程序;面向对象的编程语言(如Java、C++、PHP)保留了面向过程的关键字和语句,可以采用面向过程的方式来开发程序。
类的继承
一个类可以继承另一个类的特征,如同儿子继承父亲的DNA、性格和财产等,与现实生活中的继承类似。
9. 理解闭包吗?请讲一讲闭包在实际开发中的作用;闭包建议频繁使用吗?
闭包:就是一个获取并访问某个作用域,可在外访问或者自身内部访问。
最大的两个作用
-
读取函数内部变量
-
让变量值始终保持在内存里
function f1(){ var n=999; nAdd=function(){n+=1} function f2(){ alert(n); } return f2; } var result=f1(); result(); // 999 nAdd(); result(); // 1000
result实际上就是闭包f2函数。它一共运行了两次,第一次的值是999,第二次的值是1000。这证明了,函数f1中的局部变量n一直保存在内存中,并没有在f1调用后被自动清除。
为什么会这样呢?原因就在于f1是f2的父函数,而f2被赋给了一个全局变量,这导致f2始终在内存中,而f2的存在依赖于f1,因此f1也始终在内存中,不会在调用结束后,被垃圾回收机制(garbage collection)回收。
这段代码中另一个值得注意的地方,就是"nAdd=function(){n+=1}"这一行,首先在nAdd前面没有使用var关键字,因此nAdd是一个全局变量,而不是局部变量。其次,nAdd的值是一个匿名函数(anonymous function),而这个匿名函数本身也是一个闭包,所以nAdd相当于是一个setter,可以在函数外部对函数内部的局部变量进行操作
-
管理私有变量和私有方法,将对变量(状态)的变化封装在安全的环境中
-
将代码封装成一个闭包形式,等待时机成熟的时候再使用,比如实现柯里化和反柯里化
-
需要注意的:
-
由于闭包内的部分资源无法自动释放,容易造成内存泄露 解决方法是,在退出函数之前,将不使用的局部变量全部删除。
-
闭包会在父函数外部,改变父函数内部变量的值。所以,如果你把父函数当作对象(object)使用,把闭包当作它的公用方法(Public Method),把内部变量当作它的私有属性(private value),这时一定要小心,不要随便改变父函数内部变量的值。
-
建议不要深度的使用闭包,那样的代码非常难以维护以及理解。
10.说一下了解的js 设计模式,解释一下单例、工厂、观察者。
需要了解的几个设计模式:
https://www.jianshu.com/p/c09cc339c85c
// 1) 单例: 任意对象都是单例,无须特别处理 var obj = {name: 'michaelqin', age: 30}; // 2) 工厂: 就是同样形式参数返回不同的实例 function Person() { this.name = 'Person1'; } function Animal() { this.name = 'Animal1'; } function Factory() {} Factory.prototype.getInstance = function(className) { return eval('new ' + className + '()'); } var factory = new Factory(); var obj1 = factory.getInstance('Person'); var obj2 = factory.getInstance('Animal'); console.log(obj1.name); // Person1 console.log(obj2.name); // Animal1 //3) 代理: 就是新建个类调用老类的接口,包一下 function Person() { } Person.prototype.sayName = function() { console.log('michaelqin'); } Person.prototype.sayAge = function() { console.log(30); } function PersonProxy() { this.person = new Person(); var that = this; this.callMethod = function(functionName) { console.log('before proxy:', functionName); that.person[functionName](); // 代理 console.log('after proxy:', functionName); } } var pp = new PersonProxy(); pp.callMethod('sayName'); // 代理调用Person的方法sayName() pp.callMethod('sayAge'); // 代理调用Person的方法sayAge() //4) 观察者: 就是事件模式,比如按钮的onclick这样的应用. function Publisher() { this.listeners = []; } Publisher.prototype = { 'addListener': function(listener) { this.listeners.push(listener); }, 'removeListener': function(listener) { delete this.listeners[listener]; }, 'notify': function(obj) { for(var i = 0; i < this.listeners.length; i++) { var listener = this.listeners[i]; if (typeof listener !== 'undefined') { listener.process(obj); } } } }; // 发布者 function Subscriber() { } Subscriber.prototype = { 'process': function(obj) { console.log(obj); } }; // 订阅者 var publisher = new Publisher(); publisher.addListener(new Subscriber()); publisher.addListener(new Subscriber()); publisher.notify({name: 'michaelqin', ageo: 30}); // 发布一个对象到所有订阅者 publisher.notify('2 subscribers will both perform process'); // 发布一个字符串到所有订阅者
11.ajax 跨域有哪些方法,jsonp 的原理是什么,如果页面编码和被请求的资源编码不一致如何处理?
跨域:
浏览器对于javascript的同源策略的限制,例如a.cn下面的js不能调用b.cn中的js,对象或数据(因为a.cn和b.cn是不同域),所以跨域就出现了.
上面提到的,同域的概念又是什么呢??? 简单的解释就是相同域名,端口相同,协议相同
同源策略:
请求的url地址,必须与浏览器上的url地址处于同域上,也就是域名,端口,协议相同.
跨域及几种跨域方式:https://www.cnblogs.com/chenshishuo/p/4919224.html
jsonp原理:https://blog.csdn.net/hansexploration/article/details/80314948
如果页面编码和被请求的资源编码不一致如何处理?
描述:
js编码和页面编码不一致,导致提示变量未定义的解决方法 (2011-06-30 10:27:02)转载▼
标签: js跨域 变量未定义 js编码 it 分类: JS
今天在测试项目的时候,由于是和其他站合作的,引用合作方的js文件,
有个js函数调用,调用时会使用包含合作方js里的变量,
可是竟然不兼容ie6、ie7、360等主流浏览器。那必须得解决是吧。
原本以为是跨域问题,如果是跨域问题,也应该提示没权限,可是没提示。
提示的是某某变量未定义,我就百度了。 没找到我想要的答案,
灵机一动想到是不是编码问题 。于是在js后加了 charset="utf-8" 这个 。
发现还真好了。 。 绕了好些圈子 。 这次记下了。避免下次再遇到类似的状况。
比如:http://www.yyy.com/a.html 中嵌入了一个http://www.xxx.com/test.js
a.html 的编码是gbk或gb2312的。 而引入的js编码为utf-8的 ,那就需要在引入的时候
<script src="http://www.xxx.com/test.js" charset="utf-8"></script>
同理,如果你的页面是utf-8的,引入的js是gbk的,那么就需要加上charset="gbk".
----------------------百度上搜到一个答案,不知道是否正确?---------------
参考文档:http://www.codes51.com/itwd/1198587.html
开源工具
1. 是否了解开源的架构工具 bower、npm、yeoman、gulp、webpack,有无用过,有无写过,一个 npm 的包里的 package.json 具备的必要的字段都有哪些(名称、版本号,依赖)
npm是什么:https://blog.csdn.net/qq_37696120/article/details/80507178
gulp是工具链,可以配合各种插件做js压缩,css压缩,less编译等工作
webpack是文件打包工具,可以把项目的各种js文、css文件等打包合并成一个或多个文件
bower是包管理器,用来管理你项目里的那些外部依赖的。
2. Git常用命令
https://www.cnblogs.com/allanli/p/git_commands.html
计算机网络基础
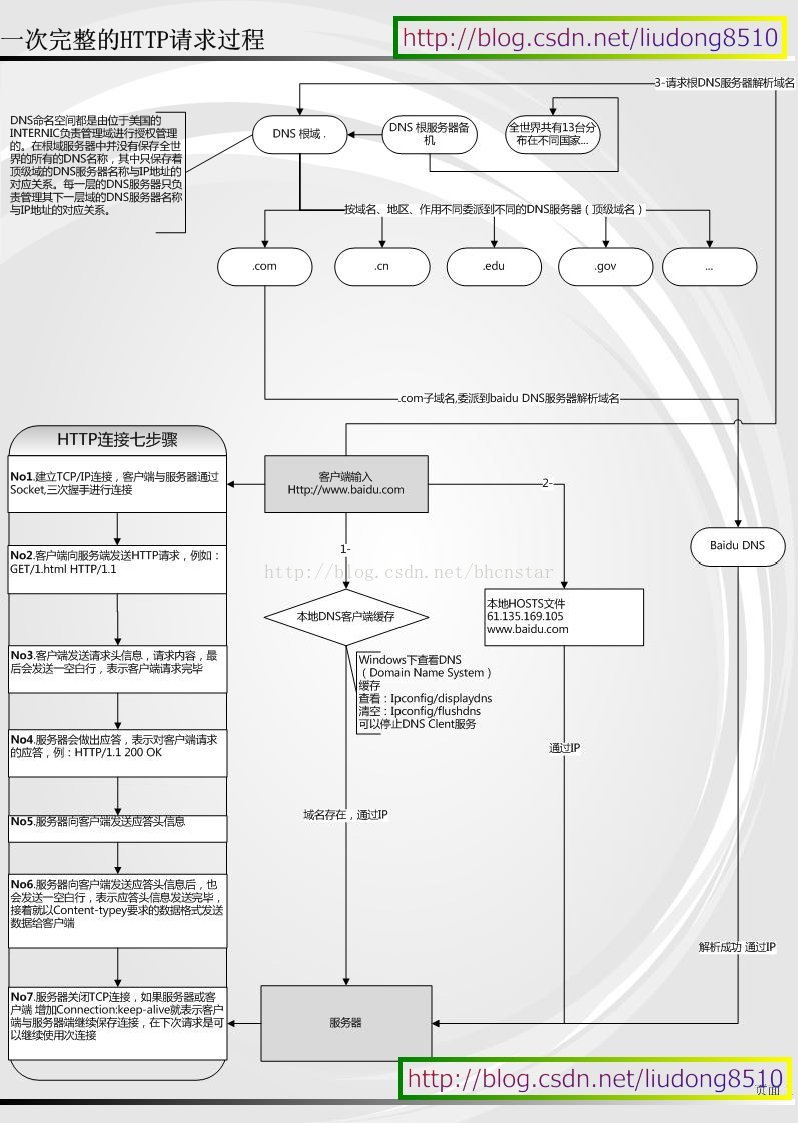
1. 说一下HTTP 协议头字段说上来几个,是否尽可能详细的掌握HTTP协议。一次完整的HTTP事务是怎样的一个过程?
HTTP协议详细总结:https://www.cnblogs.com/zrtqsk/p/3746891.htm
2.cookies 是干嘛的,服务器和浏览器之间的 cookies 是怎么传的,httponly 的 cookies 和可读写的 cookie 有什么区别,有无长度限制?请描述一下cookies,sessionStorage和localStorage的区别?
cookies 是干嘛的?
网页是没有记忆的.一个用户浏览同一个网站的不同的网页将会被网站视为完全新的访问者.当我们浏览同一个网站的不同网页时,会话cookie使得我们正在访问的网站能不用重复要求我们提供已经给过的信息.
cookie允许我们在访问多网页的网站时无需重复验证身份(如登录).
最常见的例子是电商网站的购物车, 当你访问一个类目页面,选择一些商品,cookie会记住你的选择,因此当你下单时购物车会有相应的商品.
如果没有cookie,当你下单时,新的页面将不能记住你之前的选择,购物车也将是空的.
当然你可以调整你的浏览器的cookie设置.
持久型cookie是干嘛的?
当你未来访问网站时持久cookie帮助网站记得你的信息.
这可以使得我们更快,更方便的访问网站,比如,我们可以不用再次登录.
除了登录外,持久cookie使得其他的一些网站特性成为可能,如:语言选择,主题选择,菜单设定等.
服务器和浏览器之间的 cookies 是怎么传的?
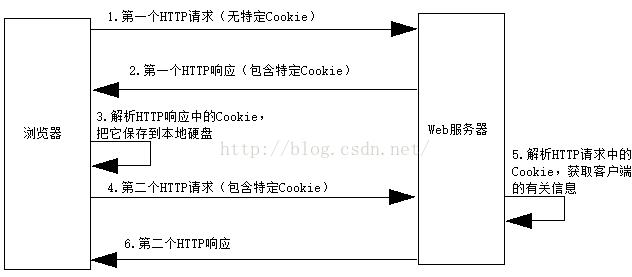
请描述一下cookies,sessionStorage和localStorage的区别?
1.存储大小
- cookie数据大小不能超过4k。
- sessionStorage和localStorage 虽然也有存储大小的限制,但比cookie大得多,可以达到5M或更大。
2.有效时间
- localStorage 存储持久数据,浏览器关闭后数据不丢失除非主动删除数据;
- sessionStorage 数据在当前浏览器窗口关闭后自动删除。
- cookie 设置的cookie过期时间之前一直有效,即使窗口或浏览器关闭
3. 数据与服务器之间的交互方式
- cookie的数据会自动的传递到服务器,服务器端也可以写cookie到客户端
- sessionStorage和localStorage不会自动把数据发给服务器,仅在本地保存。
整个过程大致如下: 1. 输入URL,浏览器根据域名寻找IP地址 2. 浏览器发送一个HTTP请求给服务器,如果服务器返回以301之类的重定向,浏览器根据相应头中的location再次发送请求 3. 服务器接受请求,处理请求生成html代码,返回给浏览器,这时的html页面代码可能是经过压缩的 4. 浏览器接收服务器响应结果,如果有压缩则首先进行解压处理 5. 浏览器开始显示HTML 6. 浏览器发送请求,以获取嵌入在HTML中的对象。在浏览器显示HTML时,它会注意到需要获取其他地址内容的标签。这时,浏览器会发送一个获取请求来重新获得这些文件——包括CSS/JS/图片等资源,这些资源的地址都要经历一个和HTML读取类似的过程。所以浏览器会在DNS中查找这些域名,发送请求,重定向等等… 那么,一个页面,究竟是如何从我们输入一个网址到最后完整的呈现在我们面前的呢?还需要了解一下浏览器是如何渲染的:
浏览器渲染引擎在获取到内容后的基本流程: 1. 解析HTML 2. 构建DOM树 3. DOM树与CSS样式进行附着构造呈现树 4. 布局 5. 绘制 上述这个过程是逐步完成的,为了更好的用户体验,渲染引擎将会尽可能早的将内容呈现到屏幕上,并不会等到所有的html都解析完成之后再去构建和布局render树。它是解析完一部分内容就显示一部分内容,同时,可能还在通过网络下载其余内容。
4.是否了解Web注入攻击,说下原理,最常见的两种攻击(XSS 和 CSRF)了解到什么程度。
了解:https://www.cnblogs.com/Echoer/p/4781664.html
5.是否了解公钥加密和私钥加密。如何确保表单提交里的密码字段不被泄露。验证码是干嘛的,是为了解决什么安全问题。
公钥和私钥区别:https://www.cnblogs.com/moonfans/p/3939335.html
验证码是干嘛的,是为了解决什么安全问题:
防止恶意注册和暴力破解,所谓恶意注册和暴力破解都是用软件进行的。 人工注册再快,也需要一项一项输入资料,速度很慢,对服务器基本没有影响。如果没有验证码可以使用软件注册的话,可以同时运行成千上万个线程,一次能注册成千上万个用户,让服务器的数据库很快变得臃肿不堪,运行效率下降。 如果一个无聊的人或竞争对手对某网站怀有敌意,那么这种方法很容易就能让对方瘫痪。
6.编码常识:文件编码、URL 编码、Unicode编码 什么含义。一个gbk编码的页面如何正确引
url编码
url编码是一种浏览器用来打包表单输入的格式,URL编码遵循下列规则: 每对name/value由&;符分开;每对来自表单的name/value由=符分开。如果用户没有输入值给这个name,那么这个name还是出现,只是无值。任何特殊的字符(就是那些不是简单的七位ASCII,如汉字)将以百分符%用十六进制编码,当然也包括象 =,&;,和 % 这些特殊的字符。其实url编码就是一个字符ascii码的十六进制。不过稍微有些变动,需要在前面加上“%”。比如“”,它的ascii码是92,92的十六进制是5c,所以“”的url编码就是%5c。那么汉字的url编码呢?很简单,看例子:“胡”的ascii码是-17670,十六进制是BAFA,url编码是“%BA%FA”。
escape(),encodeURI() 和 encodeURIComponent() 编码函数是JavaScript编程中非常常用的几个函数。
Unicode编码 : https://blog.csdn.net/hezh1994/article/details/78899683
文件编码: https://www.cnblogs.com/me115/p/3880146.html#h23
前端框架
1.对 MVC、MVVM的理解?
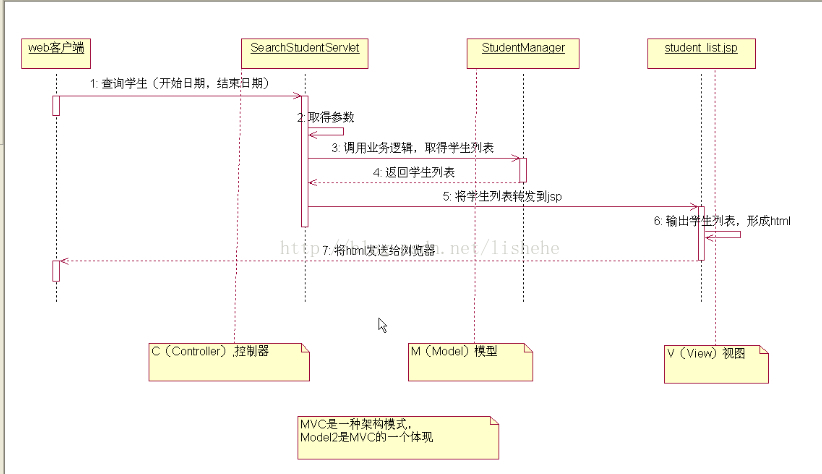
MVC是一种架构模式,M表示Model,V表示视图View,C表示控制器Controller:
- Model负责存储、定义、操作数据、从网络中获取数据(Struts中Service和Form);
- View用来展示给用户,并且和用户进行交互;
- Controller是Model和View的协调者,Controller把Model中的数据拿过来给View使用。Controller可以直接与Model和View进行通信,而View不能与Controller直接通信。,当有数据更新时,Model也要与Controller进行通信,这个时候就要用Notification和KVO,这个方式就像发广播一样,Model发信号,Controller设置接收监听信号,当有数据更新是就发信号给Controller,Model和View不能直接通信,这样违背MVC设计原则。View与Controller通信需要利用代理协议的方式,Controller可以直接根据Model决定View的展示。View如果接受响应事件则通过delegate,target-action,block等方式告诉Controller的状态变化。Controller进行业务的处理,然后再控制View的展示。 那这样Model和View就是相互独立的。View只负责页面的展示,Model只是数据的存储,那么也就达到了解耦和重用的目的。
实例解析 UML图:大家熟悉MVC的调用流程逻辑
2.vue、angularjs等相对于 jQuery在开发上有什么优点?
- Vue比jQuery减少了DOM操作
- Vue使用
双向绑定来处理表单问题,在使用多表单的页面可以更方便快捷的处理表单问题 - 众所周知jQuery的选择器是十分
损耗浏览器资源的,而Vue 2.0使用虚拟DOM则避开了这一缺点 组件化的开发模式可以使常用的模块独立起来,可以复用
3.前后分离的思想了解吗?
前后端先定义接口,比如约定只用json数据进行互相通信。
但是前台的页面跳转,可能就是用前台框架路由的概念去跳转,跳转后去 ajax请求后台 获得新页面需要的json数据。
单写前台时 应该有模拟静态数据的工具,支持只用前台用静态数据 去开发一套页面。然后后台开发好之后,把和后台对接的接口数据 数据
- 最大的好处就是前端JS可以做很大部分的数据处理工作,对服务器的压力减小到
- 后台错误不会直接反映到前台,错误接秒较为友好
- 由于后台是很难去探知前台页面的分布情况,而这又是JS的强项,而JS又是无法独立和服务器进行通讯的。所以单单用后台去控制整体页面,又或者只靠JS完成效果,都会难度加大,前后台各尽其职可以最大程度的减少开发难度。
可参考:https://blog.csdn.net/moonpure/article/details/79770404
4.你上一个项目都用到了那些方法优化js的性能?
5.Vue的生命周期?
6.说一下你对vue和vuex的使用方法,vue的组件复用机制?