设计一个缓存系统,必须要考虑以下几点
1、访问频率高、读多写少、数据一致性要求低的数据才适合做缓存
2、缓存穿透
3、缓存击穿
4、缓存雪崩
一、缓存穿透
缓存穿透是指查询一个一定不存在的数据,由于缓存是不命中时被动写入的,出入容错的考虑,在从DB中查询不到相应的数据的时候,则不会将此数据写入缓存中。这将会导致每次查询这个数据都会去查DB数据库,这样就失去了缓存的意义。从一定的安全上讲,假如有人将这个不存在的key频繁的攻击数据库,就会导致数据库压力过大而挂掉。
解决方案:这里介绍常见的两种方案
1、采用布隆过滤器。
即将可能存在的数据hash到一个足够大的bitmap中,一个一定不存在的数据则会被bitmap拦截掉,这样就一定程度上防止了对底层数据库的查询压力。
2、如果从DB数据库中查询的数据返回为空,也将其缓存,但它的实效时间会设置的比较短,一般不超过5分钟。
二、缓存击穿
缓存击穿是指在高并发下,多个线程同时查询同一个数据,如果这个数据在缓存中不存在(一般是因为key失效),则这些线程就会全部去请求DB,对数据库造成了极大的压力,这样就失去了缓存的意义。有句话说的很好,数据库是人,缓存是防弹衣,线程则子弹。本来防弹衣的目的就是为了防止子弹直接打到人身上,但是当防弹衣失效的时候,子弹就会直接打到人身上去了。
解决方案:
1、后台定义job定时去刷新缓存。比如一个key的失效时间是30分钟,则job每隔29分钟去定时刷新缓存。
这种方案比较容易理解,但会增加系统复杂度。比较适合那些 key 相对固定,cache 粒度较大的业务,key 比较分散的则不太适合,实现起来也比较复杂。
2、检查更新
将缓存key的过期时间(绝对时间)一起保存到缓存中(可以拼接,可以添加新字段,可以采用单独的key保存..不管用什么方式,只要两者建立好关联关系就行).在每次执行get操作后,都将get出来的缓存过期时间与当前系统时间做一个对比,如果缓存过期时间-当前系统时间<=1分钟(自定义的一个值),则主动更新缓存.这样就能保证缓存中的数据始终是最新的(和方案1一样,让数据不过期.)
这种方案在特殊情况下也会有问题。假设缓存过期时间是12:00,而 11:59 到 12:00这 1 分钟时间里恰好没有 get 请求过来,又恰好请求都在 11:30 分的时,这样就比较惨了。
3、使用互斥锁
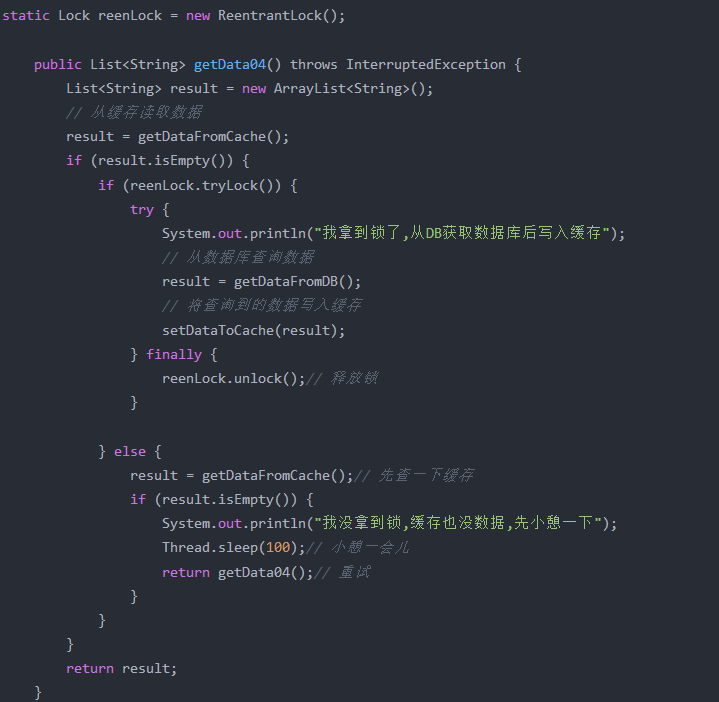
4、使用分布式锁
三、缓存雪崩
缓存雪崩是指我们将key的失效时间都设置成了相同的值,所以在某一时刻,这些key值将会全部失效,假如在这个时候有大量请求过来,就会因为查不到缓存数据而去查询数据库,导致数据库压力过大而雪崩。
解决方案:
缓存失效时的雪崩效应对底层系统的冲击非常可怕。大多数系统设计者考虑用加锁或者队列的方式保证缓存的单线 程(进程)写,从而避免失效时大量的并发请求落到底层存储系统上。这里分享一个简单方案就时讲缓存失效时间分散开,比如我们可以在原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
参考:
https://blog.csdn.net/sanyaoxu_2/article/details/79472465
https://blog.csdn.net/zeb_perfect/article/details/54135506