一:分析过程:fidder + chrome开发者工具
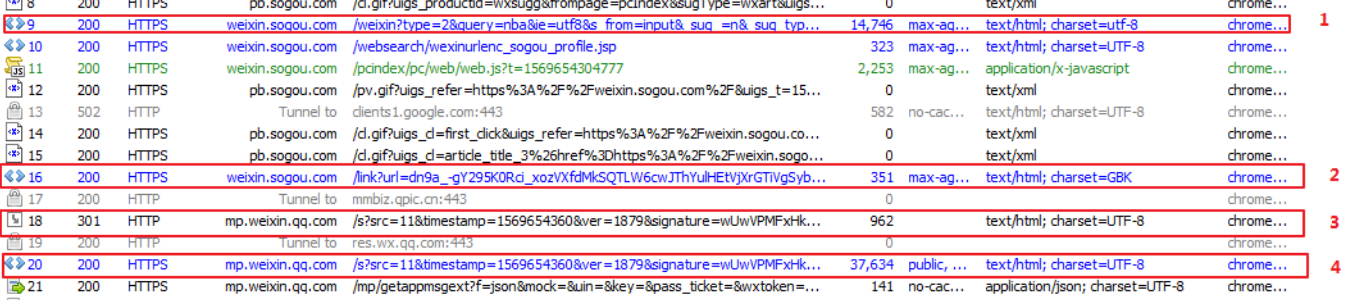
1:输入nba跳转的页面,每页显示10条相关公众号的信息
2:分析网站得到每条标题的详情页链接地址在:

3,请求上图中的url,会返回一段js代码,js代码的作用是,构造一个的新的url,并对新的url进行了请求。
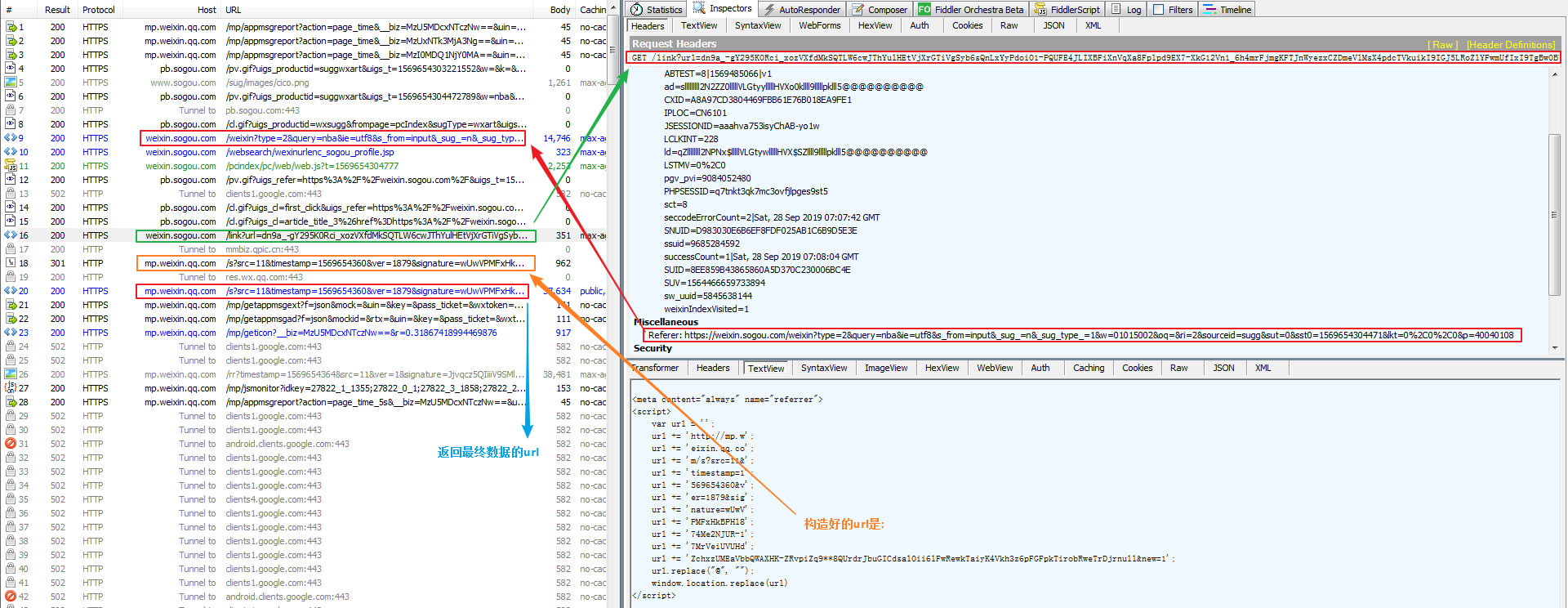
认真分析一下这段js代码,除了更换请求的url,还做了些什么。
<meta content="always" name="referrer"> <script> var url = ''; url += 'http://mp.w'; url += 'eixin.qq.co'; url += 'm/s?src=11&'; url += 'timestamp=1'; url += '569657625&v'; url += 'er=1879&sig'; url += 'nature=EtbL'; 每一个title的signature都不一样。 url += 'qcBn3zLfhrG'; url += '-3E1bon8g8i'; url += 'tE*ZzQ-9aDa'; url += 'myXb5jH7M2ioQfn7GbekEK2cn2BCeNQZa1Pl70JDLMChQZBD-kJ-jwz-xf0M*VB4Hmak7IYa7qMsYp8wevg4x5VNGLt&new=1'; url.replace("@", ""); window.location.replace(url) </script>
# 人为操作频繁都直接封ip?