有这么一张表:
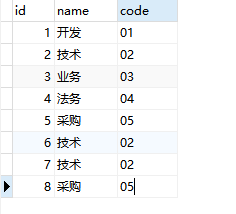
里面的技术重复了2次,采购重复了一次。
使用如下语句:
select * from test GROUP BY name HAVING COUNT(*) >1
效果如下:

可以看到返回的值与重复的次数不一样。
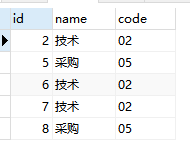
select * from test where name in(select name from test GROUP BY name HAVING COUNT(name) >1);
使用这个语句,可以把所有name一样的都返回。
效果如下:
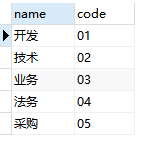
select distinct name,code from test where name=0
使用上面的代码,可以将name,code字段中重复的数据去除以后再返回,
效果如下:
select name,code from test where name=0 group by name
这个语句也是一样的效果
SELECT * FROM test WHERE name IN (SELECT `name` from test GROUP BY `name` HAVING COUNT(1)>1) AND id NOT in (SELECT min(id) from test GROUP BY `name` HAVING count(1)>1)
SELECT * from test where id not in (SELECT dt.minno from (SELECT MIN(id) as minno from test GROUP BY name)dt)
删除多余数据且只保留1条
delete from test where name in (SELECT t.name from (SELECT name from test GROUP BY name HAVING COUNT(1)>1)t) and id not in (SELECT dt.minno from (SELECT min(id) as minno from test GROUP BY name HAVING count(1)>1)dt)
DELETE FROM `test` WHERE id NOT IN(SELECT * FROM(SELECT id FROM `test` GROUP BY name)AS A)