XPath介绍
XPath是从XML基础规范上派生的技术,专门用于快速检索和查询XML文档,使用方便,功能强大,XPath也是XSLT技术的基础。
XPath是W3C国际标准组织定义的用于在单个XML文档中快速检索和定位XML文档节点的规范,它也是跨平台的,若一些软件支持XPath,则必然是支持标准的XPath语法。因此无论是JAVA还是C#都是支持相同语法的XPath。
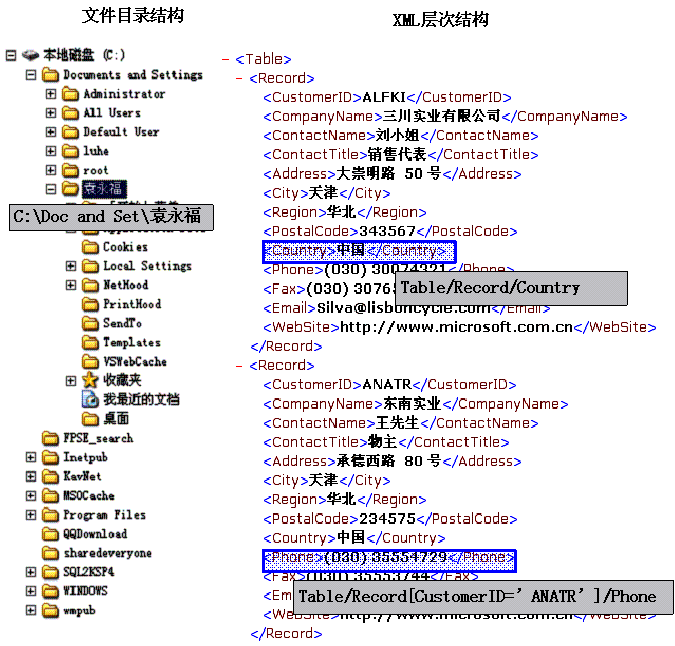
我们理解XPath时可以参考文件目录结构FilePath,在Windows资 源管理器左边的文件目录树状列表中,可以看到各种文件对象,包括磁盘根目录,各级文件目录等等,它们共同构成了一个树状结构,我们选择对象时既可以在这个 树状结构中一个个查找,也可以指定路径名来进行快速定位,文件系统的路径名采用斜杠号来分隔各个目录层次的目录名。比如在这个示意图中,我们选中的目录, 可以使用路径名”c:\documents and settings\袁永福”来快速定位。
而XML文档中也是这种树状层次结构,因此我们也可以套用这种文件路径名的概念到XML文档中,于是形成了XPath路径。我们处理XML文档时可以一层层查找所需的XML节点,也可以指定XPath路径字符串来快速定位XML节点。在XPath路径中,我们使用反斜杠符号来分隔各个层次的XML元素的名称。
在文件目录系统中,我们可以可以使用绝对路径名,也可以使用相对路径名,我们可以使用一个点号表示当前目录,使用两个点表示父目录。在XPath中我们也套用了类似的概念,我们从XML文档根节点出发而指定的XPath路径为绝对路径,从某个XML节点开始转到其它节点所经过的路径为相对路径,我们也使用一个点表示当前节点,也使用两个点来表示父节点。其实我们可以将绝对路径看成从根节点出发的相对路径。
在这个示意图中,第一个选中的节点可以使用XPath路径“Table/Record/Country”来快速定位。
在文件目录系统中,同一个目录下面不能有相同名称的对象,因此相对路径名和绝对路径名都能准确的定位到一个目录上,而在XML文档中,同一个XML节点下可以存在多个具有相同名称的子节点,因此XPath路径可能无法唯一的确定一个XML节点。此时XPath采用了内嵌条件判断语句的方法来解决这个问题。XPath路径字符串中可以使用一对方括号来包含一个逻辑表达式,在这个表达式中可以使用字符串判断,数学四则运算,逻辑判断和一些预定义函数,而且XPath路径中每个层次都能包含表格式,因此XPath的逻辑判断的功能是非常强大的。
在示意图中,我们使用XPath路径”Table/Record[CustomerID=’ANATR’]/Phone”来快速定位第二个节点,此处使用了一段方括弧包含了一个逻辑表达式。表示查找某个节点,该节点下的CustoemrID子节点的文本值等于 “ANATR”。
XPath是一种国际标准,但在微软的.NET框架当然支持这个国际标准。我们可以使用.NET类库中的System.Xml.Xsl.XslTransform类型来执行XSLT转换。这个类型除了支持标准的XPath外,还进行一些扩展,主要是能扩展使用开发者自己定义的函数。
使用XPath,我们可以很方便的搜索XML文档中的任何部分,因此具有很好的数据检索分析功能,近期业界兴起的半结构化文档技术大多就是以XPath为基础的。
由于XPath技术是相当强的,而且是国际标准,跨平台的,因此大家有时间好好学习使用它。对于XPath的详细语法可访问网站 http://www.w3.org/TR/xpath ,若大家安装了MSDN2003版,也可参考 MSDN Library/XML Web Services/XML核心/SDK 文档/MSXML4.0 SDK/XPath Reference。这些电子文档全是英文,大家也可以购买一些专门讲述XML技术的中文书籍看看。
XSLT介绍
XSLT是一种将XML文档转换为其他文本文档的语言,是建立在XML和XPath之上的国际标准,内容比较多,功能强大。
对于编程人员来说,XSLT可以看作以前序遍历的方式专门处理XML树状结构的标记语言。以前编程根据XML文档输出纯文本数据时需要写代码以前序遍历方式的方式遍历XML文档对象组成的树状结构,对于每一个特定名称或特定层次的XML节点而输出不同的内容,这个过程比较复杂,代码量大,需用进行很多的状态判断。而XSLT则使用一种简洁明了的标记语言实现了相同的逻辑。因此XSLT从程序逻辑的角度看类似支持递归的编程语言,而且是专门处理XML文档的。
XSLT转换过程会涉及到三个文本文档,一个是要处理的原始XML文档,第二个就是XSLT样式表文档,该文档包含了XSLT代码,XSLT代码本身就是XML格式,但使用了XML的名称空间。第三个就是XSLT处理输出的文本文档,注意,此处输出的是纯文本文档,这个文档具体是什么格式完全靠XSLT代码来决定,可以是另外一个XML文档,HTML文档,SQL语句字符串或者其他任意格式的字符串数据等等,XSLT转换只能输出纯文本文档,此外就没有限制输出文档的具体格式。
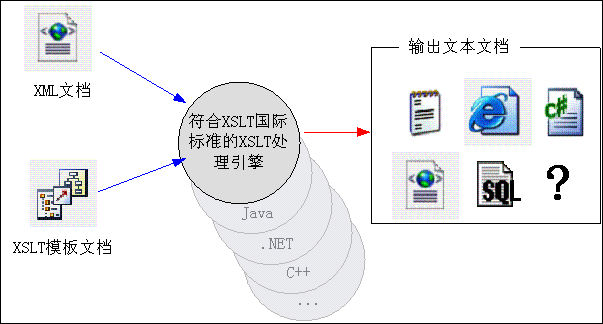
XSLT范例
下面使用一个XSLT范例来说明XSLT处理过程。
在这个示意图中有三个图片,第一个是原始的包含数据的XML文档,第二个是XSLT样式表文档的内容,第三个就是转换结果。XSLT代码如下
| <xsl:stylesheetversion='1.0'xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <xsl:outputmethod='xml'/> <xsl:templatematch='/'> <html> <body> <tableborder='1'> <xsl:for-eachselect="Table/Record"> <tr> <xsl:for-eachselect="*"> <td> <xsl:value-ofselect="."/> </td> </xsl:for-each> </tr> </xsl:for-each> </table> </body> </html> </xsl:template> </xsl:stylesheet> |
数据XML文档是一个很简单的XML文档,此处不加说明了。重点说说XSLT样式表文档,可以看到XSLT样式表文档本身一个XML文档。它采用XML的树状结构来描述递归处理过程,也比较好理解。
在样式表文档中,根元素为 xsl:stylesheet ,里面定义了一个名为xsl的名称空间,这个根节点及其属性值都是固定的。
xsl:output 元素是可选的,它的method属性用于指定输出文档的格式,可以设置为xml,html或text值。此处使用xml输出样式,说明输出的文档是XML格式的,XSLT转换会尽量生成XML文档,但不作保证,因此仍然有可能生成不合格的XML文档。
xsl:template 用于定义一个XSLT模板,模板类似编程语言中的函数,可实现XSLT代码的重用。模板可以使用name属性定义名称,也可以使用match属性定义匹配的XPath路径,这个模板使用了match属性来匹配XML文档本身。
然后是 html 元素,由于html元素没有使用xsl的前缀,因此不属于xslt代码,因此将原样输出,跟着后面的body,table元素也是一样的。
xsl:for-each 元素类似C#中的foreach 语法结果,表示循环遍历元素,它使用select属性指定一个XPath相对路径,XSLT使用这个相对路径查询所有要遍历的XML节点,此时当前节点就是XML文档本身,因此XSLT处理器会调用XmlDocument的SelectNodes 函数来获得要遍历的XML节点,函数的参数就是Table/Record。于是我们开始循环遍历所有的Record元素了。
在循环遍历Record元素时,对每一个Record元素都要输出xsl:for-each的子节点,首先是 tr 元素,这不是XSLT元素,因此原样输出。这里还套嵌定义了另外一个for-each元素,于是我们又开始了一个新的循环遍历了,新的循环指定的相对XPath路径是一个星号,表示匹配所有名称的子元素,这类似DOS命令Dir中使用星号匹配所有文件。此处表示循环遍历Record元素下面所有的字段元素。
对每一个字段元素,首先输出td 元素,然后处理xsl:value-of 元素,xsl:value-of 表示输出指定相对路径的节点的值,这里指定的XPath是一个点号,表示当前节点本身,由于当前节点是XML元素,因此也就输出元素的文本内容,相当于输出XmlElement的InnerText 属性值。
![]()
为了让大家更清楚的了解XSLT执行过程,我写了一段C#代码来模拟实现这个XSLT转换过程,代码在演示程序的 codexslt.aspx 中。代码如下
| // 此处代码动态构造 xml 文档对象结构来输出XML文档 System.Xml.XmlDocument XmlDoc = new System.Xml.XmlDocument(); -------------- 查询数据库,填充XmlDoc -------------------------- // 保存输出结果的缓冲区 System.IO.StringWriter myResult = new System.IO.StringWriter(); myResult.WriteLine("<html>"); myResult.WriteLine(" <body>"); myResult.WriteLine(" <table border='1'>"); // 模拟 <xsl:for-each select="Table/Record"> foreach( System.Xml.XmlNode node in XmlDoc.SelectNodes("Table/Record")) { myResult.WriteLine(" <tr>"); // 模拟 <xsl:for-each select="*"> foreach( System.Xml.XmlNode node2 in node.SelectNodes("*")) { myResult.Write(" <td>"); // 模拟 <xsl:value-of select="." /> myResult.Write( node2.InnerText ); myResult.WriteLine("</td>"); } myResult.WriteLine(" </tr>"); } myResult.WriteLine(" </table>"); myResult.WriteLine(" </body>"); myResult.WriteLine("</html>"); myResult.Close(); |
代码很简单,这里我就不详细说明了。
这里只是展示了一个非常简单的XSLT转换过程,XSLT和XPath语法不少,但花点时间是可以记下来的,编写XSLT模板是很有技巧性的。一般的我们要设计XSLT模板,首先获得要转换的XML文档样本以及所需转换结果的样本,这两个样本可能相差非常大,所有的差别都需要依靠XSLT转换模板来弥补,此时XSLT模板的编写不只是XSLT元素和函数的堆砌,而是需要同时兼顾输入和输出,还需要使用面向过程的编程思想。有时还需要编程对XSLT转换器进行扩展。
XML/XSLT在WEB开发中的应用
XML/XSLT技术在WEB开发中可以发挥很大的应用,可以为WEB开发提供一种新的HTML页面生成方式。
一般的在WEB开发中使用XML/XSLT技术主要有两种模式,一个是在服务器端执行XSLT转换,另一个是在客户端执行XSLT转换。
在服务器端执行XSLT转换时,应用系统的业务模块生成包含要显示的数据的XML文档,然后调用事先写好的XSLT模板文档,执行XSLT转换,转换结果一般是HTML文档,当然也可以是其他类型的文本文档,此时客户端就可以将生成的HTML文档直接作为页面响发送到客户端浏览器中。客户端浏览器接受HTML文档并显示出来。在这个过程中,服务器端生成的XML文档,XSLT转换生成的HTML文档都是临时生成的文档,都可以存留在内存中,用完即可清除掉,不需要写到磁盘文件中。
在客户端执行XSLT转换时,应用系统的业务模块生成包含要显示的数据的XML文档,加上XSLT转换信息标记,直接发送到客户端浏览器,客户端浏览器获得这个XML文档,根据其中的XSLT转换信息标记,从服务器上下载指定名称的XSLT文档。然后调用自己的XSLT转换器进行转换,在内存中生成了HTML文档并显示出来。此时显示的HTML页面不会出现在浏览器的缓冲文件夹中,也看不到HTML源代码,只能看到XML的源代码。
由于XSLT转换是国际标准,在服务器端的转换结果和在客户端的转换结果是一样的。因此两种模式下浏览器中显示的页面内容是一样的。

在传统的WEB开发中,我们都是直接使用业务系统拼凑出HTML字符串来生成要显示的HTML页面。虽然在ASP.NET中大量使用Web控件来简化开发,但web控件内部还是拼凑HTML字符串的。使用程序代码来拼凑HTML字符串会影响程序代码的可读性,很容易使得程序代码杂乱无章,而且生成的HTML可读性差。
若使用XML/XSLT技术则可以有效的改善这种情况,由于XML文档格式检查非常严格,因此这就使得程序代码生成XML文档过程准确,不得出现错误,在这个环境下迫使程序员注意保持程序代码质量。而且生成的XML文档不只用于生成HTML页面,还能方便的向其他程序模块提供数据,并可充当WebService。
考察WEB应用中生成的HTML代码,可以发现,大量的HTML页面中用于实现页面各种动态效果和页面格式的HTML代码多于直接显示数据的HTML代码,而且HTML代码普遍重复。这使得HTML页面代码臃肿,文件大,这会使得客户端浏览器下载页面缓慢。当采用XML/XSLT技术并在客户端执行XSLT转换时,由于服务器端发送的XML文档非常简洁,只包含纯粹的数据,并没有其他冗余的代码,因此文档小,下载快。与之配套的XSLT模板也是经过分析处理的,代码重复少,因此XSLT文件也小,这样客户端浏览器以前要下载一个很大的HTML文档,而现在只要下载两个较小的文档,这缩短了浏览器下载数据的时间。
除了改善数据传输过程,浏览器自己执行XSLT转换,这样能将一部分的工作量从服务器端转移到客户端,此时服务器端只要快速生成包含数据的XML文档即完成工作。由于XSLT是广泛采用的国际标准,此时WEB系统能可靠的使用客户端的运算能力,从而减少服务器端运算压力,而利用客户端长期闲置的运算能力。
虽然XML/XSLT技术具有很大的优势,但在实际开发中仍然存在不小的问题,其中最大的问题就是编制XSLT模板文件成本高。我们在开发WEB系统中使用了很多开发工具,包括VS.NET的WEB窗体设计器,美工人员使用的FrontPage,Dreamwave等等,都是用于生成HTML文档的,而HTML文档要求不严格,很多内容还不符合XML规范,因此需要使用各种方法将这些HTML文档转换为标准的XML文档,然后还需要分析页面结构,将这些XML文档加工成XSLT文档。在目前的技术条件下,这个过程成本比较大,使得XML/XSLT技术难于推广和普及。在此建议大家多多思考,如何低成本的将HTML文档转换为XSLT文档。
而且XML/XSLT技术调试比较困难,对开发者要求很高,这也加大了这个技术的应用成本。而且目前的web系统中大量使用的WEB控件没有考虑到XML/XSLT技术,这也阻碍了这种新技术的应用。
使用C#执行XSLT转换
在演示程序中,其中有些代码就是使用C#来执行XSLT转换的。
record.aspx
演示程序中record.aspx演示了在服务器端执行XSLT转换,打开这个页面的C#代码中,在Page_Load函数中,首先是查询数据库并生成一个包含数据的XML文档。然后我们使用了一个名为xsl的页面参数,这个参数就指定了使用XSLT模板文件。若用户指定了该参数,我们开始执行XSLT转换。
首先是创建一个XslTransform对象,调用它的Load函数来加载用户指定的XSLT模板文件,然后调用它的Transform函数,这个函数有四个参数,第一个就是包含数据的XML文档对象,第二个是XSLT转换参数的列表,此处未用,第三个就使输出转换结果的流对象,我们就使用页面输出流,最后一个是XML文档解析对象,此处未用。
| string strXSLRef = this.Request.QueryString["xsl"] ; if( strXSLRef != null && strXSLRef.Length > 0 ) { // 根据页面参数指定的XSLT样式表名称执行XSLT转换 strXSLRef = this.Server.MapPath( strXSLRef ); System.Xml.Xsl.XslTransform transform = new System.Xml.Xsl.XslTransform(); transform.Load( strXSLRef ); transform.Transform( XmlDoc , null , this.Response.Output , null ); } |
可以看到在C#中执行XSLT转换是非常简单的,只要创建一个XslTransform对象,使用Load函数加载XSLT模板,使用Transform函数来执行XSLT转换即可。
recordxml.aspx
演示程序中的recordxml.aspx演示了在客户端执行XSLT转换,打开这个页面的C#代码,在Page_Load函数中,可以看到是查询数据库并使用XmlTextWriter输出包含数据的XML文档。其中有这么一段代码,首先判断一个名为xsl的页面参数是否存在,若存在则调用xmlwriter的WriteProcessingInstruction方法输出一段名为 xml-stylesheet的XML指令,这个指令的 href 属性值就使页面参数指定的XSLT模板文件名。
| // 输出XSLT样式表信息头 string strXSLRef = this.Request.QueryString["xsl"] ; if( strXSLRef != null && strXSLRef.Length > 0 ) { xmlwriter.WriteProcessingInstruction( "xml-stylesheet" , "type='text/xsl' href='" + strXSLRef + "'"); } |
客户端浏览器解析下载的XML文档,若遇到这个这段XML指令根据其中的href属性下载XSLT模板文件,然后执行XSLT转换,将生成的转化结果再作为HTML文档显示出来。
在这个页面中,服务器端只负责输出数据XML文档,并提供XSLT模板文件下载,而XSLT转换就给客户端浏览器处理,这样就能减少服务器端的工作量并利用客户端的运算能力。
注意这里的xml-stylesheet指令只对浏览器有效,一般其他的程序处理XML文档时会忽略掉这个XML指令。即使我们在服务器端使用XslTransform对象执行XSLT转换,这个XML指令也是毫无作用的,就像不存在一样。
使用C#执行XPath查询
演示程序中的recordxpath.aspx就演示了使用C#执行XPath查询。打开这个页面的界面设计,可以看到其界面是比较简单地,其中一个单行文本框用于输入XPath字符串,一个大的多行文本框用于显示查询结果,还有一个按钮用于点击执行操作。页面代码主要在这个按钮的点击事件处理中。
双击这个按钮,可以看到该按钮的点击事件处理代码。在该处理中,首先调用CreateRecordXMLDocument函数来获得包含数据的XML文档对象,生成XML文档的过程可以参考record.aspx的说明。
程序生成包含数据的XML文档后,在从单行的文本输入框获得用户输入的XPath字符串,若用户输入的内容,则对XML文档的根节点调用SelectNodes方法,执行XPath查询,SelectNodes函数返回一个XmlNodeList列表,该列表中的元素类型是XmlNode。我们遍历这个列表,对其中每一个XML节点对象获得它的XML字符串,然后进行输出。
若用户没有输入XPath字符串,则直接输出XML文档根节点的内容。
在这里我们定义了GetXMLString 函数,这个函数主要是返回指定的XML节点对象的带缩进的XML字符串。用于取代Xml节点的OuterXml属性。
小结
在本课程中,我们了解了XPath,XML/XSLT的基础知识。并演示使用C#使用XPath和XML/XSLT技术。
XML及其派生的技术都是很重要的国际标准技术,对现代WEB开发具有很大的影响力,XML技术是一种优质的软件开发技术,因此大家要花点时间好好学习,熟练掌握XML及其派生技术将大大提高大家的软件开发能力。