装饰器:
- 定义:
- 原则:
- 实现装饰器知识储备:
推导以及铺垫,装饰器是怎么回事
1 #有十个函数,test1,test2都有自己要完成的功能 2 def test1(): 3 pass 4 5 6 def test2(): 7 pass 8 9 #如此调用 10 test1() 11 test2()
函数的代码已完成,But每个方法都要增加记录日志的功能,我们可以怎么做呢?
方法1、一行一行加代码
#乜有学函数之前,一行一行加代码 def test1(): pass print("logging...")#加一行 def test2(): pass print("logging...")#加一行too test1() test2()
方法2、定义一个方法,再调用,若有十个函数就调用十次代码,避免重复的代码。
def logger(): print("logging...") def test1(): pass logger()#这样调用 def test2(): pass logger()#这样调用 test1() test2()
但是如果,你的函数有100多个,且是已经在线上的,肿么办?你好要根据需求变化,新增一个功能。
如果按照方法2,逐个添加调用方法,虽然可以,但是修改了线上源码,修改程序源码,就会有风险发生。导致其他连锁未知反应,就不好了,导致线上的业务可能会崩掉,有风险,不能这么干。写好了程序不能动源码。
2、举例说明装饰器
写一个装饰器代码,体会一下什么叫装饰器
1 import time 2 3 def test1(): 4 time.sleep(3) #逻辑内容 5 print("in the test1") 6 7 8 test1() #调用函数
##########装饰器###########
1 import time 2 #写一个装饰器 3 def timer(func): 4 def warpper(*args,**kwargs): 5 start_time=time.time() 6 func() 7 stop_time=time.time() 8 print("the func run time is %s "%(stop_time-start_time)) 9 return warpper 10 11 @timer #这里调用,写在test1前面 12 def test1(): 13 time.sleep(3) 14 print("in the test1") 15 16 17 test1()
【运行结果】
in the test1
the func run time is 3.000171661376953
情况1、 以下方法,不定义bar(),调用时会报错
1 def foo(): 2 print("in the foo") 3 bar() 4 5 foo()
情况1图解

情况2、bar()的定义在方法foo()的调用之前
1 def bar(): 2 print("in the bar") 3 4 def foo(): 5 print("in the foo") 6 bar() 7 8 9 foo()
【运行结果】
in the foo
in the bar
情况2图解

情况3、bar()的定义在方法foo()的定义之后
1 def foo(): 2 print("in the foo") 3 bar() 4 5 #bar()的定义放在调用函数之前 6 def bar(): 7 print("in the bar") 8 9 foo()
【运行结果】
in the foo
in the bar
情况3图解,同上
情况4、bar()的定义在方法foo()的调用之后
1 def foo(): 2 print("in the foo") 3 bar() 4 5 foo() 6 7 def bar(): 8 print("in the bar")
【运行结果】
Traceback (most recent call last):
in the foo
File "D:/Python/s014/Day4/fuc.py", line 8, in <module>
foo()
File "D:/Python/s014/Day4/fuc.py", line 6, in foo
bar()
NameError: name 'bar' is not defined
3、什么是【函数即“变量”】
变量名,方法名是门牌号,对应到各自的值分配的内存地址上

1 x=1 2 y=x 3 4 def test(): 5 pass
在python解释器中,有一个概念叫做引用基数,那什么叫引用基数,就是比方说,x=1,y=x,它会先在内存当中把1这个值存放下来,这个x,y其实就是"1"的门牌号,也是对"1"的一次引用。python什么时候把这个1这个屋子清空呐?它会等到"1"所对应的门牌号都没有了,就会把"1"这里面的东西给清掉,这个也是python的内存回收机制,就是靠这种方式回收的。
【匿名函数】
#匿名函数 calt=lambda x:x*3 print(calt(3))
lambda x:x*3 是函数体但是没有名字,没有名字就代表能被回收掉,赋值给变量calt,就是给他一个门牌号
4、高阶函数
a、把一个函数名当做实参传给另外一个函数
b、返回值中包含函数名
写一个高阶函数
1 def bar(): 2 print("in the bar") 3 4 def test1(func): 5 print(func) 6 7 test1(bar)
【运行结果】打印了一个内存地址
<function bar at 0x0000000000B57048>
【直接加小括号可以运行吗】
1 def bar(): 2 print("in the bar") 3 4 def test1(func): 5 print(func) 6 func()#这样调用方法可以运行吗 7 8 9 test1(bar) #把 bar函数名当做实参传到test1中 10 11 【运行结果】 12 <function bar at 0x0000000001167048> 13 in the bar
不加小括号,就是一个内存映射的地址,加小括号,就是调用方法,可以运行。
方法一,增加部分功能,统计bar方法的运行时间
1 import time 2 3 def bar(): 4 time.sleep(3) 5 print("in the bar") 6 7 def test1(func): 8 start_time = time.time() 9 func() 10 stop_time = time.time() 11 print("the func run the is %s"%(stop_time-start_time)) 12 13 14 test1(bar) #把 bar函数名当做实参传到test1中,这里改变了调用bar()函数的方法 15
【运行结果】
in the bar
the func run the is 3.0
------------------------------------------------------------------------------
以上代码,test1相当于装饰器,给原来的方法增加了新功能,但是修改了调用方法。
原则应该是【在不修改原源代码的情况下,为其增加新的功能。】 bar()方法没有变
方法二,不修改调用方式的情况下的调用
1 import time 2 3 def bar(): 4 time.sleep(3) 5 print("in the bar") 6 7 def test2(func): 8 print(func) 9 return func #返回函数的内存地址 10 11 12 bar = test2(bar) #把test2(bar)赋给bar方法 13 bar() #没有bar函数改变调用方式
这样赋值,bar=test2(bar)
再调用bar()方法
5、函数嵌套
在一个函数的函数体内,用def 去声明一个函数,而不是去调用其他函数,称为嵌套函数。
函数嵌套的作用:
函数嵌套就是,在一个函数中声名另一个函数,而不是调用它
以下情况是不是嵌套函数呢?
1 #是不是嵌套函数呢 2 def bar(): 3 print("in the bar") 4 def foo(): 5 print("in the foo") 6 bar() #调用bar函数 7 8 foo()
当然不是,以上只适合函数调用而已,在方法内调用bar()函数,而没有声明定义
函数嵌套以及函数的调用
1 def foo(): 2 print("in the foo") 3 def bar():#在foo函数中定义一个函数bar——————函数嵌套 4 print("in the bar") 5 bar()#函数调用 6 foo()
6、函数的作用域
#局部作用域和全局作用域的访问顺序
x=0
def grandpa():-------------1
x=1
def dad():-------------2
x=2
def son():---------3
x=3
print(x)
son()
dad()
#调用grandpa
grandpa()
#输出
3
函数的作用域,从外往里,逐层查找
如果只声明,不调用,定义达到dad(),son()会是什么样的执行结果呢?
x=0 def grandpa(): x=1 def dad(): x=2 def son(): x=3 print(x) grandpa()
不调用相当于声明了一个变量 ,什么都没有做,不会有值产生dad(),son()
4-1.2、装饰器定义
1、首先装饰器实现的条件:高阶函数+嵌套函数 -->装饰器
1 import time 2 3 def timmer(func):---------------高阶函数 4 def deco():-----------------嵌套函数 5 start_time = time.time() 6 func() #run test1() 7 stop_time = time.time() 8 print("the func run time is %s"%(stop_time-start_time)) 9 return deco 10 11 @timmer # 相当于test1 = timmer(test1) 12 def test1(): 13 time.sleep(3) 14 print("in the test1") 15 16 test1()
【输出结果】
in the test1
the func run time is 3.0002999305725098
没有改变调用方式,没有修改函数源码
执行顺序:
step1、def timmer(func)直接跳过,因为只创建没有执行

step2、@timmer,这是一步运行的操作。所以又回到timmer(func),相当于赋值操作test1 = timmer(test1),逐步执行timmer函数中的每一步,然后return.

step3、走到test1()函数调用处。然后,跳到def deco():执行里面的代码,此处说明test1()已经被换成了deco()的意思。

step4、func()此步执行test1()
2、如果函数带参数的情况,执行结果是怎样的呢?
1 import time 2 3 def timmer(func): #timmer(test1) func=test1 4 def deco(): 5 start_time = time.time() 6 func() #run test1() 7 stop_time = time.time() 8 print("the func run time is %s"%(stop_time-start_time)) 9 return deco 10 11 @timmer 12 def test2(name,age): 13 print("name:%s,age:%s"%(name,age)) 14 15 test2()
【运行结果——报错】
C:UsersAdministratorAppDataLocalProgramsPythonPython35python.exe D:/PythonStudy3.5/Code1/Day4/dic.py Traceback (most recent call last): File "D:/PythonStudy3.5/Code1/Day4/dic.py", line 15, in <module> test2() File "D:/PythonStudy3.5/Code1/Day4/dic.py", line 6, in deco func() #run test1() TypeError: test2() missing 2 required positional arguments: 'name' and 'age'
Process finished with exit code 1
报错的原因:
test2函数其实就是执行的deco函数,deco函数体内的func()其实就是执行test2函数,但是,test2需要传入name和age两个参数,所以报错。
1 import time 2 def timmer(func): #timmer(test1) func=test1 3 def deco(*args,**kwargs): #传入非固定参数 4 start_time = time.time() 5 func(*args,**kwargs) #传入非固定参数 6 stop_time = time.time() 7 print("the func run time is %s"%(stop_time-start_time)) 8 return deco 9 10 #不带参数 11 @timmer # 相当于test1 = timmer(test1) 12 def test1(): 13 time.sleep(3) 14 print("in the test1") 15 16 #带参数 17 @timmer 18 def test2(name,age): 19 print("name:%s,age:%s"%(name,age)) 20 #调用 21 test1() 22 test2("Cola",3)
【运行结果】
in the test1
the func run time is 3.0
name:Cola,age:3
the func run time is 0.0
def deco(*args,**kwargs): #传入非固定参数
不能确定传入几个参数,所以我们只能用非固定参数传参。
3、执行函数有返回值
1 import time 2 3 def timmer(func): #timmer(test1) func=test 4 def deco(*args,**kwargs): 5 print("定义一个 res 接收返回值") 6 res = func(*args,**kwargs) #这边传入函数结果赋给res 7 print("res 接收完毕,要return喽") 8 return res # 返回res 9 return deco 10 11 12 @timmer 13 def test1(): # test1 = timmer(test1) 14 print("in the test1") 15 return "from the test1" #执行函数test1有返回值 16 17 18 19 res = test1() 20 print("test1() run over ...") 21 print("res 是什么呢 ...") 22 print(res)
【运行结果】
定义一个 res 接收返回值
in the test1
res 接收完毕,要return喽
test1() run over ...
res 是什么呢 ...
from the test1
其实就是在内置函数中把传入参数的执行结果赋给res,然后再返回res变量。
4、带参数的装饰器
在你访问不通页面时,你用的验证的方式来源不同,这时你该怎么办?
step1给方法增加装饰器名字

step2 定义装饰器实现的方法

step3 调用

step4、给调用方法增加返回值

step5 调用方式的区分

step6、增加一层,传进来的参数,打印参数,调用方法

step7、增加判断条件


1 #本地验证 2 user,passwd = "user1","pwd123" 3 def auth(auth_type): #传递装饰器的参数 4 print("auth func:",auth_type) 5 def outer_wrapper(func): # 将被装饰的函数作为参数传递进来 6 def wrapper(*args,**kwargs): #将被装饰函数的参数传递进来 7 print("wrapper func args:",*args,**kwargs) 8 username = input("Username:").strip() 9 password = input("Password:").strip() 10 if auth_type == "local": 11 if user == username and passwd == password: 12 print("�33[32mUser has passed authentication�33[0m") 13 res = func(*args,**kwargs) 14 print("--after authentication") 15 return res 16 else: 17 exit("Invalid username or password") 18 elif auth_type == "ldap": 19 pass 20 return wrapper 21 return outer_wrapper 22 23 def index(): 24 print("welcome to index page") 25 26 @auth(auth_type="local") #带参数装饰器 27 def home(): 28 print("welcome to home page") 29 return "from home" 30 31 @auth(auth_type="ldap") #带参数装饰器 32 def bbs(): 33 print("welcome to bbs page") 34 35 index() 36 home() 37 bbs()
重上面的例子可以看出,执行步骤:
1.outer_wrapper = auth(auth_type="local")
2.home = outer_wrapper(home)
3.home()
所以这个函数的作用分别是:
1.auth(auth_type) 传递装饰器的参数
2.outer_wrapper(func) 把函数当做实参传递进来
3. wrapper(*args,**kwargs) 真正执行装饰的函数
4-2、生成器
在使用一组数据时,通常情况下会定义一个列表,然后循环里面的元素,但是,如果你只需要使用列表中的1-2个元素,其他的元素用不到,这样就会造成资源的浪费,这样不能很好的合理的利用我们机器的资源,那我们如何合理高效的利用这些利用这些资源,并且提高我们程序的运行速度呢?下面我们就来讲讲我们今天最关键的知识点,生成器。
4-2.1、列表生成式
看列表[0,1,2,3,4,5,6,7,8,9],需求是把列表中的每个元素加1,怎么做呢?
1 a = [0,1,2,3,4,5,6,7,8,9] 2 for index,i in enumerate(a): 3 a[index] += 1 4 print(a) 5 6 #输出 7 [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
更简便的方法?
1 [ i*2 for i in range(10)] 2 [0, 2, 4, 6, 8, 10, 12, 14, 16, 18]

i 的值 ,取出来赋给i*2 , 以上这种就叫列表生成
4-2.2、生成器
可以通过列表生成式,直接去创建一个列表。受到内存的限制,列表的容量是有限的。如果我们在创建一个包含100万个元素的列表,甚至更多,不仅占用了大量的内存空间,而且如果我们仅仅需要访问前面几个元素时,那后面很大一部分的占用的空间都白白浪费掉了。这个并不是我们所希望看到的。
所以我们就诞生了一个新的名词叫生成器:generator。下面我们就来说说这个生成器的作用。
生成器的作用:列表的元素按某种算法推算出来,我们在后续的循环中不断推算出后续的元素,在python中,这种一边循环一边计算的机制,称之为生成器(generator)。
1 m=[i*2 for i in range(10)] 2 print(m) 3 #输出 [0, 2, 4, 6, 8, 10, 12, 14, 16, 18] #生成一个list 4 n = (i*2 for i in range(10)) 5 print(n) 6 #输出 <generator object <genexpr> at 0x00000000033A4FC0> #生成一个generator
如果需要访问生成器n中的值,python2是通过next()方法去获得generator的下一个返回值,python3是通过__next__()去获得generator的下一个返回值:
1 #python 3的访问方式用__next__() 2 >>> n.__next__() 3 0 4 >>> n.__next__() 5 2 6 >>> n.__next__() 7 4 8 >>> n.__next__() 9 6 10 >>> n.__next__() 11 8 12 >>> n.__next__() #没有元素时,则会抛出抛出StopIteration的错误 13 Traceback (most recent call last): 14 File "<pyshell#4>", line 1, in <module> 15 n.__next__() 16 StopIteration 17 18 19 #python2的访问方式用next() 20 >>> n.next() #可以用n.next() 21 0 22 >>> next(n) #也可以用next(n) 23 2 24 >>> n.next() 25 4 26 >>> n.next() 27 6 28 >>> n.next() 29 8 30 >>> n.next() #没有元素时,则会抛出抛出StopIteration的错误 31 32 Traceback (most recent call last): 33 File "<pyshell#4>", line 1, in <module> 34 n.next() 35 StopIteration
小结:①generator保存的是算法,每次调用next方法时,就会计算下一个元素的值,直到计算到最后一个元素,如果没有更多元素,则会抛出StopIteration的错误。
②generator只记住当前位置,它访问不到当前位置元素之前和之后的元素,之前的数据都没有了,只能往后访问元素,不能访问元素之前的元素。
4-2.3、用for循环去访问generator中的元素
用next方法去一个一个访问,不切实际,正确的方法是使用for循环去访问,因为generator也是可迭代对象,代码如下:
res = (i*2 for i in range(3)) #创建一个生成器 res #<generator object <genexpr> at 0x0000000003155C50> for i in res: #迭代生成器中的元素 print(i)
创建一个生成器以后,基本不会用next方法去访问,而是通过for循环来迭代它,并且更不用关心StopIteration错误。
4-2.4、函数实现生成器
上面推算比较简单,但是推算的算法比较复杂,用类似列表生成式的for循环无法实现,那怎么办呢?比如下面一个例子,用列表生成式无法实现。
- 斐波那契数列
实现原理:除第一个和第二个数外,任意一个数都可由前两个数相加得到:1, 1, 2, 3, 5, 8, 13, 21, 34, ...,代码如下:
def fib(max): n,a,b = 0,0,1 while n < max: print(b) a , b = b ,a+b n = n+1 return "----done---"
很明显斐波拉契数列用列表生成式写不出来,但是,用函数把它打印出来却很容易。
这边需要注意的是赋值语句:
a , b = b ,a+b
相当于
t = (b, a + b) # t是一个tuple a = t[0] b = t[1]
n is_______ 0 a is_______ 0 b is_______ 1 1 n is_______ 1 a is_______ 1 b is_______ 1 1 n is_______ 2 a is_______ 1 b is_______ 2 2 n is_______ 3 a is_______ 2 b is_______ 3 3 n is_______ 4 a is_______ 3 b is_______ 5 5
根据这种逻辑推算非常类似一个生成器(generator)。但是怎么把一个函数转换成一个生成器呢?
- 用yield函数转换为生成器(generator)
def fib(max):
n,a,b = 0,0,1
while n < max:
yield b #用yield替换print,把fib函数转化成一个生成器
a , b = b ,a+b
n = n+1
return "----done---"
以上就是生成器(generator)另外一种定义方法。如果一个函数中包含yield关键字,那么这个函数就不是一个普通的函数,而是一个生成器(generator)。
1 f = fib(5) 2 print(f) 3 4 #输出 5 <generator object fib at 0x0000000000D1B4C0>
这边有两个难理解地方:
①函数是顺序执行的,遇到return语句或者最后一行函数语句就返回
②变成generator的函数,在每次调用next()的时候执行,遇到yield语句返回,再次执行时从上次返回的yield语句处继续执行。
①访问元素:
1 f = fib(5) 2 print(f.__next__()) 3 print(f.__next__()) 4 print(f.__next__()) 5 print("我在干别的事情") 6 print(f.__next__()) 7 print(f.__next__())#访问的是最后一个元素 8 print(f.__next__()) #没有多余的元素 9 10 #输出 11 1 12 1 13 2 14 -----我在干别的事情----- 15 3 16 5 17 Traceback (most recent call last): 18 File "D:/PycharmProjects/pyhomework/day4/生成器/fib.py", line 20, in <module> 19 print(f.__next__()) 20 StopIteration: ----done---
从上面的例子可以看出来:
①我访问生成器中的元素,不用是连续的,我可以中间去执行其他程序,向想什么时候执行,可以再回头去执行。
②return在这边作用就是当发生异常时,会打印ruturn后面的值。
②for循环访问
f = fib(5) for i in f: print(i) #输出 1 1 2 3 5
③捕获这个StopIteration这个异常
f = fib(5) while True: try: x = f.__next__() print("f:",x) except StopIteration as e: #当try中的程序执行错误了,才会执行except下面的代码 print("Generator return value:",e.value) break #执行结果 f: 1 f: 1 f: 2 f: 3 f: 5 Generator return value: ----done---
关于程序的执行顺序是这样的




执行yield b,函数就中断跳出函数外面,
每次next()之后都回到函数上次中断的位置yield b
yield 保存了函数的中断状态
4-2.5、生成器并行计算
典型的生产者消费者模型
def consumer(name): print("%s 准备吃包子啦!"%name) while True: baozi = yield #yield没有返回值就是空 print("包子[%s]来了,被[%s]吃了"%(baozi,name)) c = consumer("kaka")#变成一个生成器了 c.__next__()#一定要next方法才行
【运行结果】
kaka 准备吃包子啦!
如果多加一个next()方法
c = consumer("kaka")#变成一个生成器了 c.__next__()#一定要next方法才行 c.__next__()
【执行结果】
kaka 准备吃包子啦!
包子[None]来了,被[kaka]吃了
1、send()方法
1 ef consumer(name): 2 print("%s 准备吃包子啦!"%name) 3 4 while True: 5 baozi = yield #yield没有返回值就是空 6 7 print("包子[%s]来了,被[%s]吃了"%(baozi,name)) 8 9 c = consumer("kaka")#变成一个生成器了 10 c.__next__() #__next__方法调用yield,不传值 11 b1 = "芹菜馅" 12 c.send(b1) #send方法调用yield,同时给yield传一个值 13 b2 = "韭菜馅" 14 c.send(b2)
【执行结果】
kaka 准备吃包子啦!
包子[芹菜馅]来了,被[kaka]吃了
包子[韭菜馅]来了,被[kaka]吃了
1、send()方法从上面可以看出send()和__next__()方法的区别:
__next__()只是调用这个yield,也可以说成是唤醒yield,但是不不会给yield传值。
send()调用这个yield或者说唤醒yield同时,也活给yield传一个值。
使用send()函数之前必须使用__next__(),因为先要中断,当第二次调用时,才可传值。
因为如果不执行一个__next__()方法,只是把函数变成一个生成器,你只有__next__()一下,才能走到第一个yield,然后就返回了,调用下一个send()传值时,才会发包子。
1 # __author__ = 'huojia' 2 import time 3 4 def consumer(name): 5 print("%s 准备吃包子啦!"%name) 6 7 while True: 8 baozi = yield #yield没有返回值就是空 9 10 print("包子[%s]来了,被[%s]吃了"%(baozi,name)) 11 12 def producer(name): 13 c = consumer("A") 14 c2 = consumer("B") 15 c.__next__() 16 c2.__next__() 17 print("老子准备吃包子啦!") 18 for i in range(10): 19 time.sleep(1) 20 print("做了一个包子,分两半") 21 c.send(i) 22 c2.send(i) 23 24 25 producer("kaka")
【运行结果】
A 准备吃包子啦!
B 准备吃包子啦!
老子准备吃包子啦!
做了一个包子,分两半
包子[0]来了,被[A]吃了
包子[0]来了,被[B]吃了
做了一个包子,分两半
包子[1]来了,被[A]吃了
包子[1]来了,被[B]吃了
做了一个包子,分两半
包子[2]来了,被[A]吃了
包子[2]来了,被[B]吃了
做了一个包子,分两半
包子[3]来了,被[A]吃了
包子[3]来了,被[B]吃了
做了一个包子,分两半
包子[4]来了,被[A]吃了
包子[4]来了,被[B]吃了
做了一个包子,分两半
包子[5]来了,被[A]吃了
包子[5]来了,被[B]吃了
做了一个包子,分两半
包子[6]来了,被[A]吃了
包子[6]来了,被[B]吃了
做了一个包子,分两半
包子[7]来了,被[A]吃了
包子[7]来了,被[B]吃了
做了一个包子,分两半
包子[8]来了,被[A]吃了
包子[8]来了,被[B]吃了
做了一个包子,分两半
包子[9]来了,被[A]吃了
包子[9]来了,被[B]吃了
单线程下实现并行效果。
4-3 迭代器
4-3.1、什么是可迭代对象
1、for循环数据类型
- 集合数据类型,如:list、tuple、dict、set、str、bytes(字节)等。
- 生成器(generator),包括生成器和带yield的生成器函数。
2、可迭代对象
可迭代对象(Iterable):直接用于for循环遍历数据的对象,统称为可迭代对象。简单的理解就是可循环对象。
3、用isinstance()方法判断一个对象是否是Iterable对象

1 >>> from collections import Iterable 2 >>> isinstance([],Iterable) #列表 3 True 4 >>> isinstance((),Iterable) #元组 5 True 6 >>> isinstance({},Iterable) #字典 7 True 8 >>> isinstance('abc',Iterable) #字符串 9 True 10 >>> isinstance(100,Iterable) #整型 11 False
注:生成器不但可以作用于for循环,还可以被__next__()函数不断调用,并且返回下一个值,直到最后抛出StopIteration错误表示无法继续返回下一个值而抛出的异常。
4-3.2、迭代器
迭代器(Iterator):可以用__next__()函数调用并不断的返回下一个值的对象称为迭代器。
1、用isinstance()方法判断一个对象是否是Iterator对象
1 >>> from collections import Iterator 2 >>> isinstance((i*2 for i in range(5)),Iterator) #生成器 3 True 4 >>> isinstance([],Iterator) #列表 5 False 6 >>> isinstance({},Iterator) #字典 7 False 8 >>> isinstance('abc',Iterator) #字符串 9 False
通过上面的例子可以看出,生成器都是IteratorIterableIterator对象。
2、iter()函数
功能:把list、dict、str等Iterable对象变成Iterator对象。
1 >>> from collections import Iterator 2 >>> isinstance(iter([]),Iterator) 3 True 4 >>> isinstance(iter({}),Iterator) 5 True
1 >>> a 2 [1, 2, 3] 3 >>> iter(a) 4 <listiterator object at 0x02833A50> 5 >>> b=iter(a) 6 >>> b.next() 7 1 8 >>> b.next() 9 2 10 >>> b.next() 11 3 12 >>> b.next() 13 Traceback (most recent call last): 14 File "<stdin>", line 1, in <module> 15 StopIteration
3、为什么list、dict、str等数据类型不是Iterator?
这是因为python的Iterator对象表示的是一个数据流,Iterator对象可以被__next__()函数调用并不断返回下一个数据,直到没有数据时抛出StopIteration错误。可以把这个数据流看做是一个有序序列,但我们却不能提前知道序列的长度,只能不断通过__next__()函数实现按需计算下一个数据,所以Iterator的计算是惰性的,只有在需要返回下一个数据时才会计算。
注:Iterator甚至可以表示一个无限大的数据流,例如:全体自然数。而使用list是永远不可能存储全体自然数的。
4、rang()方法
在python2.7和python3的range()方法实现的原理是不一样的,下面我们就来用代码看看,代码如下:
1 >>> range(5) #python2.7 2 [0, 1, 2, 3, 4] 3 >>> xrange(5) #python2.7 4 xrange(5) 5 >>> range(5) #python3.5 6 range(0, 5)
5、总结
- 凡是可以作用于for循环的对象都是Iterable类型。
- 凡是作用于__next__()函数的对象都是Iterator类型,它们表示一个惰性计算的序列。
- 集合数据类型,例如:list、dict、str等,是Iterable但是不是Iterator
- 集合数据类型可以通过iter()函数获得一个Iterator对象。
4-4 内置函数
4-4-1、内置函数列表

4-4-2、内置函数详情
1、abs(x)
功能:取数的绝对值
1 >>> abs(-1) #取-1的绝对值 2 1
2、all(iterable)
功能:如果这个可迭代的元素都为真,则返回真(非0的就为真,负数也是为真)
1 >>> all([0,1,3]) #有0,说明为假 2 False 3 >>> all([1,-5,6]) #负数也是为真 4 True
3、any(iterable)
功能:可迭代的元素中,有一个为真,则返回真,空列表返回假。
1 >>> any([0,1,2]) #有一个为真,则为真 2 True 3 >>> any([]) #空列表为假 4 False
4、ascii(object)
功能:把内存对象变成一个可打印的字符串格式
>>> ascii([1,2,3,4]) '[1, 2, 3, 4]'
5、bin(x)
功能:把一个整数转换成二进制
1 1 >>> bin(300) #把300转换成二进制 2 2 '0b100101100' 3 3 >>> bin(1) 4 4 '0b1'
6、bool([x])
功能:返回一个布尔值,空列表为假,不为空为真
1 >>> bool([]) #空列表 2 False 3 >>> bool([1,2]) #不为空列表 4 True 5 >>> bool([0]) 6 True
7、bytearray[source[, encoding[, errors]]]
功能:字节数组,并且可以修改二进制的字节
1 >>> b = bytearray("abcd",encoding="utf-8") #声明一个字节数组 2 >>> b[0] #打印第一个元素的ascii值,也就是'a'对应的ascii值 3 97 4 >>> b[0] = 100 #修改时,只能赋值对应字符的ascii值 5 >>> b 6 bytearray(b'dbcd') #发现字节数组值被修改
8、bytes([source[, encoding[, errors]]])
功能:把字符串转换成字节
1 >>> b = bytes("abcd",encoding="utf-8") #声明字节 2 >>> b 3 b'abcd' 4 >>> b[0] #访问到'a'字符对应的ASCII值 5 97 6 >>> b[0]=100 #不可以修改里面的值,不然会报错 7 Traceback (most recent call last): 8 File "<input>", line 1, in <module> 9 TypeError: 'bytes' object does not support item assignment
9、callable(object)
功能:判断一个对象是否可以被调用,只有在后面有括号的,表示可以调用,比如:函数,类。
1 >>> callable([]) #列表后面不加括号 2 False 3 >>> def sayhi():pass #定义一个函数 4 >>> callable(sayhi) #函数调用,后面需要加括号 5 True
10、chr(i)
功能:通过ascii的值,找到对应的字符
>>> chr(97) 'a'
11、ord(c)
功能:根据字符,找到对应的ascii值
>>> ord('a') 97
12、classmethod(function)
功能:类方法,这个到后续谈到类的时候再说。
13、compile(source, filename, mode, flags=0, dont_inherit=False, optimize=-1)
功能:用于把代码编译的一个过程,这个基本用不到
1 >>> code = """1+3/2*6""" 2 >>> py_object = compile(code,'','eval') #把代码转换为字符串 3 >>> eval(py_object) #执行 4 10.0
14、complex([real[, imag]])
功能:返回一个复数,我们几乎用不到。
>>> complex('1+2j') (1+2j)
15、delattr(object, name)
功能:类那边使用的,先不care。
16、dict(**kwarg)、dict(mapping, **kwarg)、dict(iterable, **kwarg)
功能:返回一个字典
1 >>> dict() #定义一个字典 2 {} 3 >>> dict(name='kaka',age=18) #传入非固定关键字参数 4 {'name': 'kaka', 'age': 18} 5 >>> dict([('name','kaka'),('age',18)]) #传入一个列表 6 {'name': 'kaka', 'age': 18} 7 >>> dict([['name','kaka'],['age',18]]) #传入一个列表 8 {'name': 'kaka', 'age': 18}
17、dir([object])
功能:看一个对象有哪些方法
>>> name = [] >>> dir(name) #显示name下的所有的方法 ['__add__', '__class__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__iadd__', '__imul__', '__init__', '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__rmul__', '__setattr__', '__setitem__', '__sizeof__', '__str__', '__subclasshook__', 'append', 'clear', 'copy', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort']
18、divmod(a,b)
功能:并使用整数除法返回一个由它们的商和余数组成的数对,获得一个元组,元组第一个元素是商,第二个元素是余数。
>>> divmod(5,2) (2, 1) #2是商,1是余数
19、enumerate(iterable,start=0)
功能:获取一个列表,列表中的每个元素都是一个元组,元组的第一个数是iterable的索引,第二个数是iterable的元素。
1 >>> seasons = ['Spring', 'Summer', 'Fall', 'Winter'] 2 >>> list(enumerate(seasons)) 3 [(0, 'Spring'), (1, 'Summer'), (2, 'Fall'), (3, 'Winter')] 4 >>> list(enumerate(seasons, start=1)) 5 [(1, 'Spring'), (2, 'Summer'), (3, 'Fall'), (4, 'Winter')]
20、eval(expression, globals=None, locals=None)
功能:把字典类型的字符串变成字典,把一个整数类型的字符变成int类型,或者加减乘除这种简单转换成表达式。
>>> eval('1') #字符类型转换成int类型
1
>>> eval("1+3/2*6") #字符串转换为表达式
10.0
21、exec(object[, globals[, locals]])
功能:有语句的和复杂的语句的字符串转换成表达式
code = '''
def timmer(func): #timmer(test1) func=test1
def deco(*args,**kwargs):
res = func(*args,**kwargs) #run test1()
return res
return deco
@timmer
def test1():
print("in the test1")
return "from the test1"
res = test1()
print(res)
'''
exec(code)
#输出
in the test1
from the test1
匿名函数
def sayhi(n):
print(n)
sayhi(3)
如果整个方法,我只调用这一次,其他地方不会再调用。没有必要单独写一个函数。这种情况下写一个用完就释放的函数。
print(lambda n:print(n)(5))
模仿上面一模一样的功能
def sayhi(n):
print(n)
sayhi(3)
calc=lambda n:print(n)
calc(5)
更复杂的for循环,是不能模仿并处理的,智商不够,判断也不能写,只能做三元运算。
calc=lambda n:3 if n < 4 else n print(calc(5))
3、json和pickle序列化
写入文件中的数据,只能是字符串,但是如果要想把内存的数据对象(字典,列表,bytes类型)存到硬盘上(转成字符串)去怎么办,下面就来说说序列化:json & pickle,解决了不同平台之间的数据交换。
3-1序列化——low版
什么是序列化呢?
把内存的数据对象变成字符串,这个过程叫序列化
info = {
'name':"huojia",
"age":22
}
f=open("test.txt","w")
f.write(info)
f.close()
看运行结果报错,
Traceback (most recent call last):
File "D:/PythonStudy3.5/Code1/test/tesstjson.py", line 10, in <module>
f.write(info)
TypeError: write() argument must be str, not dict
错误提示:必须存一个字符串,不能存一个字典。
那么,用强制转换,把它变成字符串,存进去,行不行呢?
info = {
'name':"huojia",
"age":22
}
f=open("test.txt","w")
f.write(str(info))
f.close()
运行成功,打开文件看看,存进去了
3-2 反序列化——low版
反序列化就是,从文件加载回来
使用另外一段代码
f=open("test.txt","r")
data=f.read()
f.close()
print(data)
运行结果,没有问题
{'age': 22, 'name': 'huojia'}
但是读取的内容不是一个字典,而是一个字符串类型
那么用字典的方式取值要怎么做呢?
f=open("test.txt","r")
data=eval(f.read())
f.close()
print(data["age"])
运行成功了
22
以上的序列化和反序列化的方式都,太low了
3-3序列化 ——json版
1、dumps序列化和loads反序列化
dumps()序列化
import json #导入json模块
import json #导入json模块
info = {
'name':"huojia",
"age":22
}
f=open("test.txt","w")
print(json.dumps(info))
f.close()
打印出来,变成字符串了。
{"age": 22, "name": "huojia"}
执行write方法。直接写入文件
import json #导入json模块
info = {
'name':"huojia",
"age":22
}
f=open("test.txt","w")
f.write(json.dumps(info))
f.close()
另外一个文件,反序列化的时候
import json #导入json模块
info = {
'name':"huojia",
"age":22
}
f=open("test.txt","r")
data=json.loads(f.read())
print(data["age"])
f.close()
运行结果
22
序列化和反序列化的过程,实现了从内存将数据写入磁盘,再从磁盘读取到内存中的整个过程,和虚拟机挂起又恢复的过程相似
2、dump序列化和load反序列化
dump()序列化
import json
info = {
'name':"kaka",
"age":22
}
with open("test.txt","w") as f: #文件以写的方式打开
json.dump(info,f) #第1个参数是内存的数据对象 ,第2个参数是文件句柄
#text.txt文件中的内容
{"name": "kaka", "age": 22}
load()反序列化
import json
with open("test.txt","r") as f: #以读的方式打开文件
data = json.load(f) #输入文件对象
print(data.get("age"))
#输出
22
3、序列化函数
import json
def sayhi(name): #函数
print("name:",name)
info = {
'name':"kaka",
"age":22,
"func":sayhi #引用sayhi函数名
}
with open("test.txt","w") as f:
json.dump(info,f) #序列化info数据对象
#输出
File "D:PythonPython35libjsonencoder.py", line 403, in _iterencode_dict
yield from chunks
File "D:PythonPython35libjsonencoder.py", line 436, in _iterencode
o = _default(o)
File "D:PythonPython35libjsonencoder.py", line 179, in default
raise TypeError(repr(o) + " is not JSON serializable")
TypeError: <function sayhi at 0x00000000006DD510> is not JSON serializable #不支持jsom序列化
json只支持简单的数据类型,不支持复杂的数据类型,
所有语言都支持json,主要的功能是不同语言之间的数据交互
若有一天,python和java进行数据交互,要用一种都认识的格式。
为什么只支持简单的,python的类和java的类完全不一样,类,函数的数据类型还要转换就太复杂了,不干这事,所以只支持这种简单的。
xml也用来逐渐在被json取代。
小结:
- dumps和loads是成对使用的,dump和load是成对使用的。
- dumps和loads由于序列化的是内容,所以后面要加s,但是dump和load序列化的内容是对象,所以单数。
- json只能处理简单的数据类型,例如:字典、列表、字符串等,不能处理函数等复杂的数据类型。
- json是所有语言通用的,所有语言都支持json,如果我们需要python跟其他语言进行数据交互,那么就用json格式。
3-4、序列化——pickle
3-4-1、dumps序列化和loads反序列化
1、dumps()序列化
Import pickle
info = {
'name':"kaka",
"age":22,
}
with open("test.txt","wb") as f: #以二进制的形式写入
data = pickle.dumps(info) #序列化成字符串
f.write(data) #写入test.txt 文件中
#输出到test.txt文件中的内容
� }q (X ageqKX nameqX
kakaq u.
2、loads()反序列化
import pickle
with open("test.txt","rb") as f: #以二进制的模式读
data = pickle.loads(f.read()) #反序列化操作
print(data.get("age"))
#输出
22
3-4-2、复杂类型的序列化和反序列化
1、dump()序列化
import pickle
info = {
'name':"kaka",
"age":22,
}
with open("test.txt","wb") as f:
pickle.dump(info,f) #序列化
#输出
� }q (X ageqKX nameqX
kakaq u.
dump有两个参数,dump(内存对象,文件)
2、lo
ad()反序列化
import pickle
with open("test.txt","rb") as f:
data = pickle.load(f) #反序列化成内存对象
print(data.get("age"))
#输出
22

从上面的结果观察,json和pickle好像也没什么区别?
json只能序列化简单的数据类型,
pickle可以序列化python中所有的数据类型,包括函数、类等,下面我们就来看看,如何序列化函数的。
pickle序列化的是字节,而json序列化的是字符,这个要注意一下。
可不可以多dump几次呢?
import json #导入json模块
info = {
'name':"huojia",
"age":22
}
f=open("test.txt","w")
f.write(json.dumps(info))
info["age"]="23"
f.write(json.dumps(info))
f.close()
【查看文件】
相当于存了两次,存了两个字典进去。
{"age": 22, "name": "huojia"}{"age": "23", "name": "huojia"}
反序列化,load一次可以不的
import json #导入json模块
info = {
'name':"huojia",
"age":22
}
f=open("test.txt","r")
data=json.load(f)
print(data)
f.close()
不可以load多次。要报错的
Traceback (most recent call last):
File "D:/PythonStudy3.5/Code1/test/tesstjson.py", line 11, in <module>
data=json.load(f)
File "C:UsersAdministratorAppDataLocalProgramsPythonPython35libjson\__init__.py", line 268, in load
parse_constant=parse_constant, object_pairs_hook=object_pairs_hook, **kw)
File "C:UsersAdministratorAppDataLocalProgramsPythonPython35libjson\__init__.py", line 319, in loads
return _default_decoder.decode(s)
File "C:UsersAdministratorAppDataLocalProgramsPythonPython35libjsondecoder.py", line 342, in decode
raise JSONDecodeError("Extra data", s, end)
json.decoder.JSONDecodeError: Extra data: line 1 column 30 (char 29)
永远记住,你写的程序,只dump一次,只load一次。若还用原来的文件,就把原来的冲掉。想要不同的状态就dump成几个不同的文件
3、序列化函数
①序列化
import pickle
def sayhi(name): #函数
print("hello:",name)
info = {
'name':"kaka",
"age":22,
"func":sayhi #"func"对应的值sayhi,是函数名
}
with open("test.txt","wb") as f:
data = pickle.dumps(info)
f.write(data)
#输出test.txt
� }q (X funcqc__main__
sayhi
qX ageq KX nameq X
kakaqu.
②反序列化
import pickle
#在反序列化中必须写上此函数,不然会报错,
因为在加载的时候,函数没有加载到内存
def sayhi(name):
print("hello:",name)
with open("test.txt","rb") as f:
data = pickle.loads(f.read())
print(data.get("age"))
data.get("func")("kaka") #执行函数sayhi
#输出
22
hello: kaka #输出的函数体中的逻辑也是可以变的,这边我就不做演示了
【小结】
l json值支持简单的数据类型,pickle支持所有的数据类型。
l pickle只能支持python本身的序列化和反序列化,不能用作和其他语言做数据交互,而json可以。
l pickle序列化的是整个的数据对象,所以反序列化函数时,函数体中的逻辑变了,是跟着新的函数体走的。
l pickle和json在3.0中只能dump一次和load一次,在2.7里面可以dump多次,load多次,anyway,以后只记住,只需要dump一次,load一次就可以了。
4、软件目录结构规范
4-1为什么要设计好目录结构?
"设计项目目录结构",就和"代码编码风格"一样,属于个人风格问题。对于这种风格上的规范,一直都存在两种态度:
1.一类同学认为,这种个人风格问题"无关紧要"。理由是能让程序work就好,风格问题根本不是问题。
2.另一类同学认为,规范化能更好的控制程序结构,让程序具有更高的可读性。
我是比较偏向于后者的,因为我是前一类同学思想行为下的直接受害者。我曾经维护过一个非常不好读的项目,其实现的逻辑并不复杂,但是却耗费了我非常长的时间去理解它想表达的意思。从此我个人对于提高项目可读性、可维护性的要求就很高了。"项目目录结构"其实也是属于"可读性和可维护性"的范畴,我们设计一个层次清晰的目录结构,就是为了达到以下两点:
1.可读性高: 不熟悉这个项目的代码的人,一眼就能看懂目录结构,知道程序启动脚本是哪个,测试目录在哪儿,配置文件在哪儿等等。从而非常快速的了解这个项目。
2.可维护性高: 定义好组织规则后,维护者就能很明确地知道,新增的哪个文件和代码应该放在什么目录之下。这个好处是,随着时间的推移,代码/配置的规模增加,项目结构不会混乱,仍然能够组织良好。
保持一个层次清晰的目录结构是有必要的。更何况组织一个良好的工程目录,其实是一件很简单的事儿。
4-2目录组织方式
关于如何组织一个较好的Python工程目录结构,已经有一些得到了共识的目录结构。在Stackoverflow的这个问题上,能看到大家对Python目录结构的讨论。
这里面说的已经很好了,我也不打算重新造轮子列举各种不同的方式,这里面我说一下我的理解和体会。
假设你的项目名为foo, 我比较建议的最方便快捷目录结构这样就足够了:
Foo/|-- bin/| |-- foo #可执行文件||-- foo/ #主程序目录,主要逻辑存放在这里| |-- tests/ #存测试用例代码| | |-- __init__.py| | |-- test_main.py| || |-- __init__.py #有这个文件就叫包,没有就叫目录,是一个空文件| |-- main.py #程序主入口||-- docs/ #文档| |-- conf.py| |-- abc.rst||-- setup.py #安装部署的文档|-- requirements.txt #依赖关系|-- README 4-2-1简单解释一下:
l bin/: 存放项目的一些可执行文件,当然你可以起名script/之类的也行。
l foo/: 存放项目的所有源代码。(1) 源代码中的所有模块、包都应该放在此目录。不要置于顶层目录。(2) 其子目录tests/存放单元测试代码; (3) 程序的入口最好命名为main.py。
l 程序启动时,从bin/foo(启动入口)调用foo/main(主入口)
l conf/: 存放项目的一些配置文件。
l logs/: 存放项目执行的日志信息。
l docs/: 存放一些文档。
l setup.py: 安装、部署、打包的脚本。
l requirements.txt: 存放软件依赖的外部Python包列表。
l README: 项目说明文件。
除此之外,有一些方案给出了更加多的内容。比如LICENSE.txt,ChangeLog.txt文件等,我没有列在这里,因为这些东西主要是项目开源的时候需要用到。如果你想写一个开源软件,目录该如何组织。
4-2-2 README
这个我觉得是每个项目都应该有的一个文件,目的是能简要描述该项目的信息,让读者快速了解这个项目。
它需要说明以下几个事项:
l 软件定位,软件的基本功能。
l 运行代码的方法: 安装环境、启动命令等。
l 简要的使用说明。
l 代码目录结构说明,更详细点可以说明软件的基本原理。
l 常见问题说明。
我觉得有以上几点是比较好的一个README。在软件开发初期,由于开发过程中以上内容可能不明确或者发生变化,并不是一定要在一开始就将所有信息都补全。但是在项目完结的时候,是需要撰写这样的一个文档的。
可以参考Redis源码中Readme的写法,这里面简洁但是清晰的描述了Redis功能和源码结构。
4-3跨目录调用文件

这样调用这怎找到相应的文件呢,跨目录的操作,直接import找不到。
我们要从一个目录下,找到另外一个目录下的文件。
py文件中只认识和他同级的和他儿子。父级目录不认识。
父亲是谁都不知道,想找父亲级的兄弟,下面的子文件就好像异想天开了。
怎么办呢?先找到他爹
让环境变量知道,但是不能加绝对路径,换机器就不认识了,只能加相对路径。
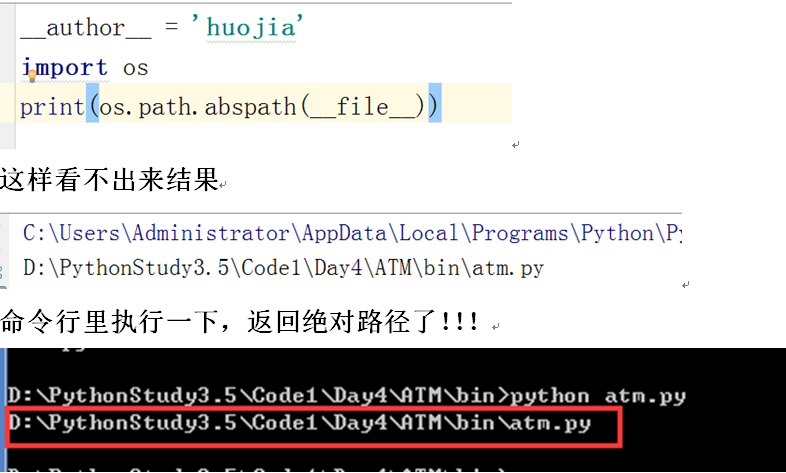
1、先找到本文件的路径是什么

得到的返回结果是绝对路径吗?No
命令行里运行出来的就是相对路径,这个是pycharm的问题

这样运行,就是相对路径了。
2、绝对路径获,动态的添加到环境变量里。
3、要找的是父级目录

4、还得往上一级,
还得往上一级,才能找到bin同级目录,才能正常使用import
再dir一次
os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
重复了好多遍,但是已经实现了。
5、添加环境变量

再导入跨目录的包,就不会报错了。
6、导入调用的方法
