MapRdeuce&Yarn的工作机制
那天在集群中跑一个MapReduce的程序时,在机器上jps了一下发现了每台机器中有好多个YarnChild。困惑什么时YarnChild,当程序跑完后就没有了,神奇。后来百度了下,又问问了别的大佬。原来是这样
什么是YarnChild:
答:MrAppmaster运行程序时向resouce manager 请求的maptask/reduceTask。也是运行程序的容器。其实它就是一个运行程序的进程。
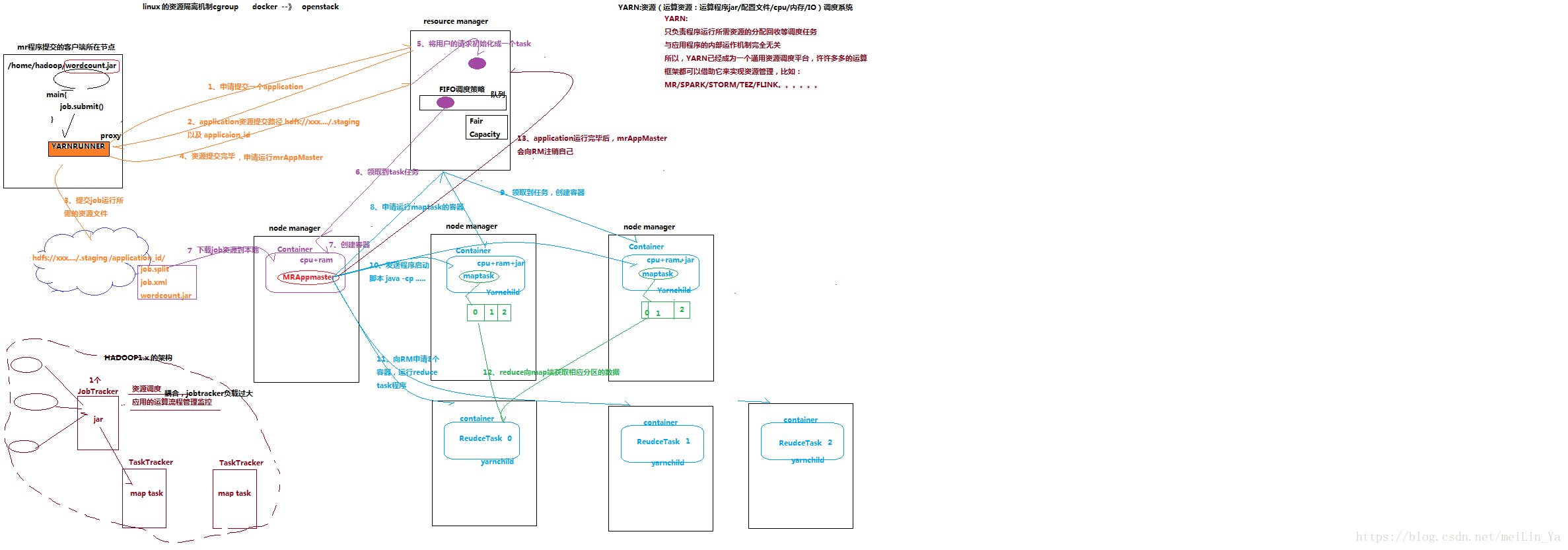
图解说下:
hadoop1版本的MapRdeuce&Yarn的工作机制
1.客户端发来request。JobTracker接受request。
2.JobTracker将客户端发来的request任务分配给TaskTracker
3.然后TaskTracker生成maptask运行程序
4.JobTracker不仅要负责资源调度,还要负责监控应运运算流程。
缺点:耦合的高,当JobTracker死掉时,所有的客户端的请求任务都会死掉,而hadoop2则避免了这个问题,它中的对象多,但都各司其职,耦合的低,运行效率快。
hadoop2版本的MapRdeuce&Yarn的工作机制
1.客户端发出请求,YARNRUNNER接受,生成一个代理对象,向resource manager请求一个application
2.resource manager返回application的提交路径和application_id(这里使用id是应为可能有多个任务用id来区别)
3.YARNRUNNER向hdfs提交job运行所需要的文件(application,job.split,job,.xml,job.jar)
4.向resource manager 报告提交完成,申请一个mrAppMaster
5.将用户的请求初始化成一个task,将task放到队列中,等待node manager来领取task任务。(这其中使用了调度策略,节约资源,如:Fair Capacity等等)
6.node manager领取到任务,
7.生成一个Container,然后在hdfs中下载运行资源。
8.向resource manager申请运行maptask的容器(带着任务,split,运行资源.的元数据..)
9.其他的node manager领取到resouce manager的任务,创建容器,此时的Container则是YarnChild,也是maptask,然后maptask在hdfs下载所要运行的资源。
10.MrAppMaster发送程序脚本运行jar,当maptask中的程序运行完成后,maptask的资源被resource manager回收了,但跑完的资源在node manager中。
11.当maptask运行完成后MRAppmaster又向resorce manager申请 reduce task(至于它申请多少个是由它有多少个map task决定的),然后根据忙于不忙node manager领取任务.创建container,
12.redcuetask 向map获取相应分区的数据资源,运行文件。
13.application运行完毕后MrAppmaster会向resource manager注销自己
总结:Yarn:资源调度系统(jar/xml/cpu/IO)
负责程序运行所需资源的分配回收等任务调度,于程序运行内部即使完全无关,所以yarn只是一个寺院调度平台,mapreudce 则是一个运行技术框架,那别的运算框架也可以使用yarn,如:spark/storm/flink....