神经网络垃圾笔记
Optimization Methods
- Batch Gradient Descent: GD
- Mini-Batch Gradient Descent
- Stochastic Gradient Descent: SGD
- Momentum: 动力
- Convergence: 收敛
Avoid Oscillate
- Momentum
- RMSProp
- Adam
- Exponentially Weighted Average
iteration与epoch
- iteration
- 迭代一次batch size就是一次iteration
- epoch
- 迭代一次整个训练集就是一次epoch
- 示例
- 假如训练集: 1000, batchSize=10, 迭代完1000个样本
- iteration=1000/10=100
- epoch=1
衡量指标
- MSE
- MAE(Mean Average Error): ({{1over{K}}sum_{k=1}^K|hat{y}-y|})
- PSNR
- SSIM
- AP(Average Precision)
- mAP(mean Average Precision)
- AP和mAP常用于多类别的目标检测中
- 知乎上https://www.zhihu.com/question/53405779
- Precision
- Recall
- FScore
英文
-
Ground Truth: 标准答案
-
color prior: 颜色先验
-
patch: 块
-
coarse: 粗的
-
depth map: 深度图(距离图)
-
estimate: 估计
-
Ambient illumination: 环境亮度
-
semantic: 语义
-
spatially: 空间
-
adjacent: 相邻的
-
feature extraction: 特征提取
-
accommodate: 适应
-
receptive: 接受
-
intermediate: 中间
-
extensive: 广泛的
-
qualitatively: 定性的
-
quantitatively: 定量的
-
breakdown: 分解
-
synthetic: 合成的
-
ablation study: 对比实验
-
occlude: 挡住
-
state-of-the-art: 达到当前世界领先水平
-
disparity: 差距
-
consecutive: 连续
-
criterion: 标准
-
visual perception: 视觉感受
-
undermine: 破坏
-
degrade: 降低
-
particle: 颗粒
-
optical: 光纤的
-
fidelity: 保真度
-
various extents: 各种程度的影响
-
concentrate: 堆积
-
transmission map: 透射图
-
maximum extent: 最大程度
-
surface albedo: 表面反照率
-
component: 分量
-
color tone: 色调
-
atmospheric veil: 大气幕
-
factorial: 因子的
-
disturbance: 干扰
-
coarse: 粗糙的
-
translation invariant: 平移不变性
-
color distortion: 颜色扭曲
-
haze thickness: 雾的厚度
-
fusion principle: 融合原理
-
quad-tree: 四叉树
-
light attenuation: 光衰减
-
lag: 滞后
-
penalize: 惩罚, 在paper中出现就是要考虑到损失计算中
-
fine-grained: 细粒度的
-
depth perception: 深度感知
-
amplification factor: 放大因子
-
detail enhancement: 细节增强
-
spatially varying: 空间变化
-
adaptive: 自适应的
-
deviation: 偏差
-
evaluation deviation: 偏差
-
retina: 视网膜
-
subjective brightness perceived: 主观视觉感知
-
anticipating: 预测
-
intention: 意图
-
power outlet: 插座
-
wrist: 腕
-
persistently: 持续地
-
trigger: 触发
-
PN(Policy Network)
-
jointly: 连带地
-
proactively: 主动地
-
facilitate: 方便, 促进, 帮助
-
accelerometer: 加速度计
-
trajectory: 轨迹
-
modalities: 模式
-
sacrificing: 牺牲
-
gist: 主旨
-
fuse: 融合
-
mechanism: 机制
-
transductive: 传导的
-
dominate: 控制
-
sub-optimal: 次优化
-
leverage: 优势
-
in an incremental manner: 渐进的方式
-
whilst: 同时
-
adopt: 采用
-
simultaneously: 同时
-
probabilistic: 概率
-
similation: 模拟
-
key addressing: 键寻址
-
value reading: 值读取
-
posterior: 后验的
-
error prone: 容易出错
-
the model inference uncertainty: 模型推理不确定性
-
univocal: 单义
-
aspect ratios: 宽高比
-
assimilate: 相似的
-
derive: 获得
-
pseudo: 伪的
-
generalization performance: 总体性能
-
rationale: 基本原理
-
footprint: 空间量
-
memory footprint: 内存占用量
-
Augmenting: 增广
-
induce: 诱导
-
imagery: 画像
-
immature: 幼稚的
-
symbolic: 象征的
-
morphological: 形态的
-
dilate: 膨胀
-
erode: 腐蚀
-
univocal: 单义的
-
supervision signal: 监督信号, 就是损失函数
-
compactness: 紧密性
-
two key learning objectives: 两个关键的学习目标
-
deep features: 深度的特征, 其实就是神经网络最后一个隐藏层
-
close-set: 闭集合
-
subtle: 细微的
-
manifold: 流型的; 多样的
-
incorporated: 收录
-
proportions: 比例
-
anthropometric: 人体测量
-
invariant: 不变的
-
hierarchical: 层次的
-
irrelevant: 无关紧要的
-
dimensionality: 维数
-
planar: 平面的
-
underlying: 基本的
-
disregard: 不理会
-
impractical: 不切实际的
-
posterior probability: 后验概率, 也就是神经网络预测的标签的概率
-
likelihood: 可能性
-
variants: 变体
-
error propagation: 误差传播
-
feature vectors: 特征向量, 在CNN中一般指的是将feature maps转为fc的第一层得到的vector
-
transition: 过渡
-
on-the-fly: 即刻
-
class-agnostic: 类别无关
-
weight transfer: 参数迁移
-
MLP: 多层感知器(全连接层)
-
textual: 文本的
-
opt: optimizer
-
warp: 扭曲
-
order: 阶
-
discrepancy: 差异
-
adversary: 敌对
-
subsequent: 随后的
-
slight pixel perturbation: 轻微像素扰动
-
aggregate: 合计
-
model inference uncertainty: 在无监督学习(只要没有标签就行, 所以半监督也行)有这个概念, 神经网络输出的就是model inference uncertainty, 因为没有ground truth做参考
-
class feature representation: 特征聚类的中心
-
latent variable models: 潜在变量模型
-
纹理: 点, 边缘, 角
-
respective field: 感受野
-
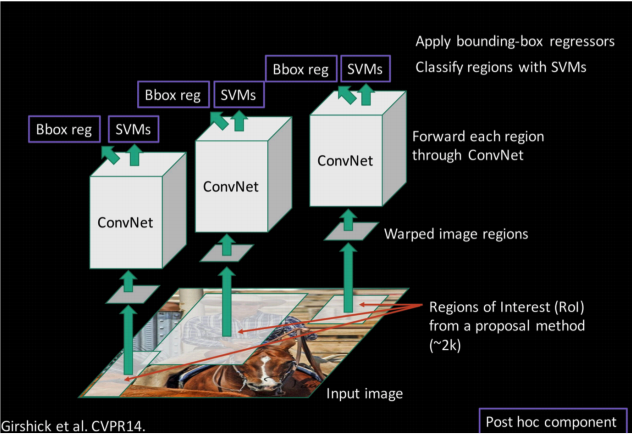
selective search: ss, 通过比较相邻区域的相似度来把相似的区域合并到一起,反复这个过程,最终就得到目标区域,这种方法相当耗时以至于提取proposal的过程比分类的过程还要慢。
-
前景: 感兴趣的物体
-
人类更倾向于根据物体的全局信息进行分类,而机器却对物体的局部信息敏感。
-
识别方式不同,使得AI擅于纹理识物,弱于轮廓; 对人类来说,整体形状是物体识别的首要条件,而通过整体形状识别图像似乎根本不在这些深度学习系统考虑范畴当中。
-
Copy
counterfeit 伪造的
latent 潜在的
interaction 相互作用
trivial 琐碎的,微不足道的(一般用否定形式) non-trivial意为重要的
bound 限制在
separate 分开的,单独的
prominent 重要的;著名的,突出的
scalar 标量
assign 确定
simultaneously 同时地
state of the art 当前最好的(炼丹侠们的目标)
prohibitive 禁止的
analogous 类似的
optimum/optimal 最佳的;最适宜的条件
proposition 计划;主张;提议
saturate 饱和,充满
objective 目标
differentiate 区分,分开;求微分
region 区域
theorem 定理
semantic 语义的;意义 (划重点!)
segmentation 分割 semantic segmentation 语义分割
substantial 显著的,重要的 substantially 相当多地
counteract 抵消;抵制
augment 增加
manifold 流行(流行空间和流行学习,一种机器学习方法,简单理解就是数据在不同维度的一些 运算)
texture 结构,纹理
plausible 貌似合理的
alternatively 或者
alternative 可供替代的;n.选择
inherently 内在地,本质上地
external 外在的
state of art 最先进的
geometry 几何学
spark 启发
synthesis 合成;n.综合体,
compression 压缩
wavelet 小波
deviation 偏差;[数]偏差 Standard Deviation 标准差
texture 结构,纹理,质地
synthetic 合成的,人工的
assessment 评价
property 特性
intriguing 引起兴趣的
quantization数字化 quantitative 定量分析的
give rise to 造成,导致
convergence 聚合,收敛
exclude 排除
intuitive 凭直觉的
suppression 抑制,阻碍
coordinate 坐标;套装
retrieve 取回,检索
harness 利用
denote 表示;意味着
redundancy 多余,冗余
overlap 重叠的
take into account 考虑到
context 背景;环境;上下文 contextual 上下文的,背景的
pixel-wise 像素级别
generic 一般的
propagation 传播
prototype 原型
topological 拓扑的
dilation 膨胀 dilation convolution 空洞卷积
derive 得出,导出
dramatically 显著地
inverse 相反的;逆
underdetermined 证据不足的,待定的
hierarchical 分级的
junction 汇合处;枢纽站
Norm 范数
Fisher matrix 费雪矩阵
KL-divergence KL散度
metric 度量标准
curvature 曲率,曲度
First-order 一阶 order为 阶数 的意思
conjugate gradient 共轭梯度
episode 一个事件;(美剧中的剧集常用该词汇)
approximation 近似值
partition 划分
sparse 稀少的;稀疏的
decay 衰减;腐烂
redundant 被裁剪的;多余的
median 中等的;n.中位数
co-efficent 系数
fuse 融合
with respect to 至于;关于
manifold 多种多样的
adjacent 毗邻的,邻近的
ba cast to 被认为
blur 模糊
intractable 难对付的;倔强的
sidestep 回避;绕开
piece wise 分段的
analogous 相似的,可比拟的
adversarial 对抗的
overlap 重叠部分
modality 方式
distill 提取
cardiovascular 心血管的
anatomy 解剖学
promising 前景好的
hinder 阻碍,妨碍
manual 手工的
chamber 心室
annotation 注释
dense 浓密的,密集的
utility 实用的;实用程序;公共事业
interpolation 插补;插值
optional 可选择的
crop 修剪
incorporation 吸收;合并
ground truth alignments 标记数据集
silhouettes 轮廓
validation 认可
spatiotemporal 时空的
encapsulate 封装;概述
reside 属于;居住
bridge 弥补;跨越
exponentially 呈几何级数地 exponent 指数;
cornerstone 基础,垫脚石
interpolation 插入;插值
outline 提纲,梗概
residual 剩余的,残余的
explicitly 明确地;直接地
extremely 非常,极大地
model 模仿
utilize 利用
inferior 下级的;较差的
conceptually 概念上地
minor 较小的,轻微的
cascade 传递;层叠
accordance 依照 in accordance with 按照…规则
exploited 发挥;利用;开发
extent 范围;程度
threshold 门槛,阈值;下限;起征点
suppress 抑制;阻止
regime 政权,管理体制
stack 堆叠
evaluation 估计;评估(常用简写eval)
surveillance 监视
lately 最近
ensemble 合奏曲;团体
spread over 分布,散开
convergence 汇聚,相交
factor 因素;因子
propose 提出
termed 被称为
in comparison to 与....相比
engineered 设计谋划的
chunk 大量的部分
replicated 复制的
keep track of 记录;保持联系
aforementioned 上述的
minor 较小的,轻微的
favorably 正面地;很好地
impractical 不现实的
scenario 设想的情况
methodology 方法
correspond to 相当于
rectified 修复
moderate 一般的;温和的;适当的
facilitate 促进,帮助;加快
aggregated 总的
scalable 可扩展的;大小可变的
besides 而且;此外
principally 主要的
pronounced 明显的,显著的
typically 典型的;一般的
sole 仅有的,唯一的
novel 新的,与众不同的
be prone to 易于…;有…倾向
complementary 互补的;辅助性的
incrementally 增长地
attribute to 归因于
effectiveness 有效性
is equivalent to 等同于
bandwidth 带宽
alleviate 缓解,减轻
ambiguity 模棱两可,不明之处
scheme 策略;方案
breathtaking 惊人的;非常激动人心的
cavern 大山洞;挖空
drift 漂流,流动
circularly 圆地;循环地
denote 表示;意味着
diagonalize 对角化
ridge 屋脊
consider 考虑到
objective 目标;客观的
resemblance 相似处
criteria/criterion 标准
holistic 全面的,整体的
perceptual 感觉上的
be subject to 受支配;易遭受
appealing 有吸引力的
paradigm 范例,范式
variants 变体;不同版本
pedestrian 行人(自动联想到行人重识别)
mitigate 缓和
relatively 相对地
valid 合理的;符合逻辑的
address 处理
early 之前的
spread over 分散,传开
procedure 程序
is tuned to 被调整为
shallow 浅的;微弱的
decompose 分解
contiguous 毗邻的,邻近的;共同的
adjacent 毗连的,邻近的
sound 完整的
manner 方式
observe 观察;注意到;遵守
is comparable to 比得上
hypothesis 假说,假设
counterpart 对应物;相当的人
clarity 清晰;明确性
convention 惯例,公约
literature 文献
split 分开的
qualitative 性质的
exhibit 表现出
animation 动画片;动画制作技术
retain 保留,保持;记住
leverage 对...施加影响
contradict 与…矛盾;反驳
distract 转移注意力
impair 削弱;降低
surpass 超过
prioritization 优先考虑,优先顺序
slightly 略微
credit 声誉;信用
preference 偏爱
pulmonary 肺的(自动联想到医学图像)
sensitively 谨慎周到地;善解人意地
nodule 瘤 (自动联想到医学图像)
proceeding 进展;继续
clinically 客观地; 临床方式地
ensemble 全体,整体
considerably 相当多地
deploy 部署;有效利用
plane 平面
rich 丰富的
advent 出现,到来
foreground 前景 background 背景
isolation 隔离;孤立
purge 清除
mechanism 机制;途径;机械装置
readily 乐意地;容易地
collaboration 合作;合作成果
trade-off 权衡,做取舍(论文常见)
conservative 传统的;保守的
computationally 计算上地
exclusive 独有的;独家报道
recover 追回;恢复
geometric 几何的
approach 接近;处理
dilemma 困境,进退两难
stabilize 使稳定
halve 减半
symmetric 对称的
be proportional to 与...成比例
middle 中间的
namely 即
polarized 偏振的;两极分化的
concatenate 把…联系起来;串联(这是一个非常重要的词汇,也是一种数组操作的名称,注意与pixelwise-add区别)
utterance 表达;说话
contrive 策划;设计,发明
deterministic 确定的
slides (PPT)幻灯片;滑落,下跌
variance 分歧,不同
paradigm 范式,样例
prefix 前缀
go straight down 沿着...往前走
comment 意见;注解;评论
in excess of 超过,多于
propagate 繁衍,增殖;扩散,扩大
extension 延期;扩展
checkboard 棋盘(图像中有一种棋盘格效应)
vertically 竖直地,垂直地
aggressively 挑衅地;激烈地(表示程度大)
stall 拖延;货摊
accessibility 可达性
lateral 侧面的;横向的(在FPN那篇论文中提到lateral connection就是指侧面的连接)
unilaterally 单边地,单方面地
unleash 宣泄;接触…束缚
divergence 分歧;区别
spectral 谱的(常见有光谱,频谱)
simultaneous 同时发生的 simultaneously 同时地
equilibrium 均衡
pitfall 陷阱;隐藏的困难
proxy 代理人,代替物;代理服务器
distill 提取;蒸馏 Knowledge Distillation(知识蒸馏)
preceding 前面的,在先的(用于描述前面层的网络)
bypass 旁道,支路;绕过,避开
presume 推测;认为,认定
compelling 非常强烈的;强迫的,不可抗拒的
nominal 名义上的;微不足道的
bring together 联合;使相识
boarder 寄宿生,高校的学生;登船(机)的人
fellow 研究员;同事,同伴(常见的有 IEEE fellow)
commitment 承诺;委任;(对工作或活动)献身
coarse 粗糙的
consecutive 连续的,连贯的
immense 巨大的
inferior 不好的;低劣的,下等的
variability 变化性,易变;变率
preliminary 初步的;预赛的
sidestep 回避,躲开
accommodate 为…提供住宿;容纳;为...提供便利(这也是一个雅思重点词汇)
to date 迄今,到目前为止
modality 方式
duality 二元性
tweak 扭,拽;轻微调整
reproduce 复制,模仿;再现
dummy 仿制品;笨蛋,蠢货;假的
ordinal 序数;比较
layout 布局,安排,设计(界面的排版就成为layout)
mutate 变异;突变,变化
alias 别名
elevation 高处,海拔
heterogeneous 各种各样的;成分混杂的
in-place 原状(在一些函数接口中常见,是指在原对象或原址中操作,无需返回)
metadata 元数据
transaction 交易,业务;学报,会议记录(TPAMI, TIP中的"T";一些操作中transaction done就是指你交代的业务执行完了)
perspective 观点;视角
stampede 蜂拥
arguably 可论证地
ridge 屋脊,山脊
occlusion 堵塞;闭塞
daunting 畏惧的,令人却步的
seamless 无缝的;无漏洞的
protocal 会议纪要;协议(例如;Http protocal)
symmetric 对称的
contract 收缩;签订合同
scarce 稀有的,稀少的;不足的
discrete 分离的
terminology 术语;专门名词
deformable 可变形的(Deformable Conv可变性卷积)
mentor 导师,顾问
discretize 使离散
pane 面板;窗格
stale 不新鲜的,厌倦的
错误传播(error propagation)
-
一个门高为(0.88mpm0.02m), 门把手高(0.5mpm0.01m), 那么门顶部到门把手距离怎么表示? 应该是在0.88-0.5=0.35左右, 那么误差呢?, 使用公式$$error uncertainity=sqrt{({0.02}2+{0.01}2)}$$
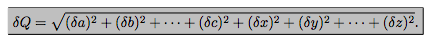
-
以上是加法, 如果为减法
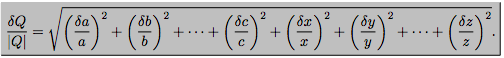
图像金字塔, 高斯金字塔, DoG(Difference of Gaussian)金字塔
-
图像金字塔是一种以多分辨率来解释图像的结构
- 原图在金字塔的底部, 往上尺寸缩小, 图像的分辨率降低
- 步骤
- 利用高斯滤波平滑图像
- 对平滑之后的图像进行采样(去掉偶数行和偶数列)
-
高斯金字塔
- 高斯金字塔并不是一个金字塔, 而是有很多组金字塔构成
- 步骤
- 先将原图像扩大一倍之后作为高斯金字塔的第1组第1层
- 进行平滑得到第2层
- 修改平滑系数, 对第2层平滑得到第3层
- 一次类推到第5层
- 第1组第3个进行下采样得到第2组的第1层, 再重复之前的步骤
-
DoG金字塔(差分金字塔)
-
在高斯金字塔的基础上构建起来的, 生成高斯金字塔的目的就是为了构建DOG金字塔
-
-
上图中同一组, 每一层之间做差分
-
-
尺度空间
- 尺度空间描述的就是图像在不同尺度下的描述
-
尺度空间与金字塔多分辨率
- 尺度空间是由不同高斯核平滑卷积得到的, 在所有尺度上有相同的分辨率
- 金字塔多分辨率每一层分辨率都减少, 模仿的是物体由近到远的过程(类似下采样), 一个物体离我们越远, 我们越只能看到他们的轮廓信息, 细节就会丢失; 而如果比较近的话, 更能容易获得细节信息
-
求纹理(特征点)
- 特征点: 点, 角, 边缘信息等变化剧烈的区域
- 对图像进行不同程度的高斯模糊, 平滑的区域变化不大, 纹理的变化大
正则化
- L1
-
[L_{min}=({{1}over{m}}sum_{i=1}^{m}{(x_iomega^T+b-y)}^2)+C||omega|| ]
-
- L2
-
[L_{min}=({{1}over{m}}sum_{i=1}^{m}{(x_iomega^T+b-y)}^2)+C{||omega||}^2 ]
-
- 为什么正则化可以防止过拟合, 因为正则化让原本loss的项加上了一个变量之后变大了, 如果优化了这个情况下的loss, 那么在是对此新的loss进行过拟合而已, 最后去掉正则化项, 模型就不会过拟合了
感受野
- 计算公式: $$l_k=l_{k-1}+(f_k-1)prod_{i=1}^{k-1}s_i$$, 其中(k)是第几层, (f)表示卷积核的尺寸, (s)表示步长
解决网络输入尺度不同
-
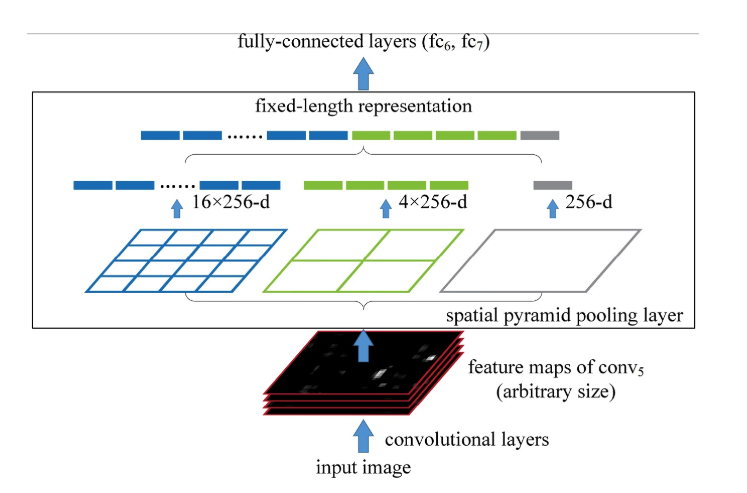
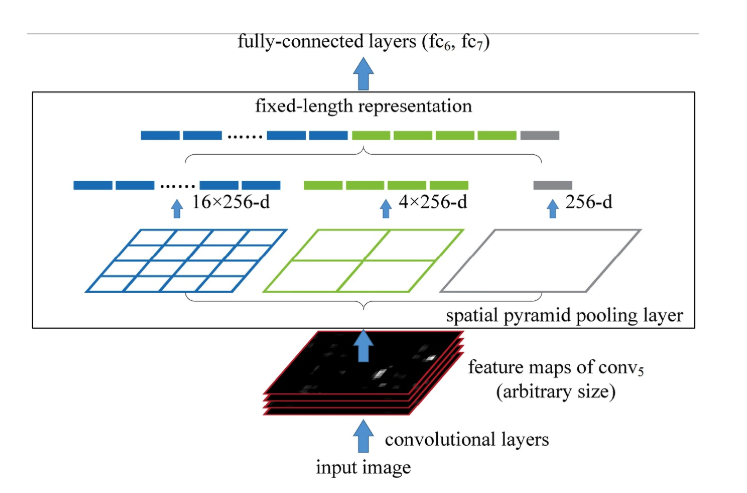
SPP池化https://juejin.im/entry/5aaa12cb6fb9a028c42ded13, https://oidiotlin.com/sppnet-tutorial/
- 在卷积之后, 在卷积层和全连接层之间添加另一个SPP池化层将卷积层输出的尺寸满足FC的输入要求
- 其实就是根据FC的尺寸计算出要达到FC的尺寸要求需要的pool的尺寸, 步长和padding等信息
- 下面给出代码(公式在forward中)
class SPPLayer(nn.Module): def __init__(self, sides): """ Parameters ---------- sides : array-like A list of side lengths """ super(SPPLayer, self).__init__() self.sides = sides def forward(self, x): out = None for side in self.sides: ksize = tuple(map(lambda v: math.ceil(v / side), x.size()[2:])) strides = tuple(map(lambda v: math.floor(v / side), x.size()[2:])) paddings = (math.floor(ksize[0] * side - x.size()[2]), math.floor(ksize[1] * side - x.size()[3])) output = nn.MaxPool2d(ksize, strides, paddings)(x) if out is None: out = output.view(-1) else: out = t.cat([out, output.view(-1)]) return out- SPPNet结构

卷积
- PS中的滤镜其实就是各种各样的卷积核
什么是维度
-
在一个空间中(不管是1D, 2D, 3D, 4D), 我们要确定该空间中的一个点需要的坐标数量就是该空间的维度(dementionality)
-
举个例子, 在一个美国的classroom中, 如果要完完整整地识别一个学生, 我们需要他的first name, middle name, last name, 所以这个教室一个三维的空间
-
维度越高数据越复杂, 人理解起来也越困难, 但是如果可以对数据进行降维的话, 可以变得比较简单, 比如, 在一个classroom中, 只需要first name就可以确定一个学生
-
数据降维
- 线性(PCA)
- 非线性(Manifold(可以理解为非线性版本的PCA))
- 有LEE, ISOMAP等算法
-
ISOMAP算法的主要流程, 主要由KNN, Dijkstra, MDS(多维缩放算法)算法组成
-
结果图
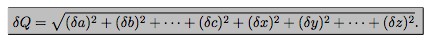
-
- 有LEE, ISOMAP等算法
-
对数据降维的补充
- 比如我们现在有48x48的人脸数据集2000个, 那么每张图片的特征数量为2304个, 如果我们希望将一张图片表示为一个点的话, 我们需要2304个维度才行, 这个太复杂了, 这个时候可以先尝试PCA降维, 如果效果不好, 再使用流型降维, 比如将图像降到3维, 也就是说现在我们可以用3个坐标来表示一个点了
损失函数(关于损失函数一般在关于细粒度分类中涉及到)
-
sigmoid cross entropy loss
-
[label imes -log(sigmoid(logits)) + (1 - label) imes -log(sigmoid(1 - logits)) ]
-
-
softmax cross entropy loss
-
[-sum_{k=1}^{m}label imes{log(softmax(logits))} ]
-
-
KL divergence loss
- cross entropy和KL-divergence作为目标函数效果是一样的,从数学上来说相差一个常数
-
center loss
-
[sum_{i=1}^{m}{||x_{j}^{i}-c_{j}||}^2 ]
-
-
MSE
-
ASE
-
Focal Loss(FL)
- Sigmoid 和 Softmax Loss 的改进版
- (FL(p)=-alpha(1-p)^{gamma}p imes log(q))
- 其中 (alpha) 负责调解正样本与负样本的平衡, (gamma) 用于调解简单样本与困难样本的平衡, (gamma) 取 2, (alpha) 在 0-1 之间
-
分布指标(新指标)
- x和坐标分别是最后一层隐藏层的输出(假设有两个节点, x和y分别为activation value)
- 图中的颜色为分类的结果
熵(p为true, q为prediction)
-
熵衡量的是不确定性, 事件发生的概率越小, 不确定性越大, 信息量越大
-
Entropy
- 衡量一个分布的不确定性
-
[sum_i^{n}-p_i{ imes}log(p_i) ]
-
KL Divergence
- 衡量两个分布的差异
-
[sum_{i}^np_ilog({{p_i}over{q_i}}) ]
-
Cross-Entropy
- 在分类问题的神经网络中, 它的输出就是一个概率分布(经过softmax激活之后), 我们给出的ont-hot的ground truth也是一个分布, 使用Cross-Entropy来衡量两个分布的差异, 学习的目的就是让差异最小化
- Cross-Entropy是真实分布的Entropy和两个分布的KL Divergence的和
-
[-sum_{i}^np_ilog(q_i) ]
应用方向
- 年龄估计
- 安全领域, web网站同时估计访问者的年龄约束访问
- 驾驶领域, 驾驶者是小孩子发出警报
并行
- 深度学习中的并行主要由两种方式
-
模型并行
- 将model拆分放到多个计算机上, 使用模型并行主要是为了解决model参数太多一台计算机内存放不下的问题
-
数据并行
- 每台计算机都部署同一个网络模型, 但是数据是分不同批次的, 当数据量很大时很有用, 但是应为模型是整个部署到一台计算机上的, 所以对于参数多的模型, 内存有很大的限制
-
图片示例
-
人体姿态识别
- 大致分为两种类别, 一种是 Top-Down Framework, 另外一种是 Bottom-Up Framework
- Top-Down Framework
- 对图片先进行行人检测, 得到边界框, 在对边界框中的行人进行关键点定位, 将关键点连接起来, 但是容易受到人体检测框影响
- Bottom-Up Framework
- 对整张图片先进行关键点定位, 再将得到的关键点部位拼接成行人的姿态
- Ground Truth 的标签一般会转换为 heatmap 的格式, 采用 gaussian kernel 进行转换
- OpenPose 方法
- 每一个 heatmap( 论文中使用 S 表示 ) 有 k 个 channel, 每个 channel 负责一个 part, 每一个 channel 和输入的图片大小一致, 对于第 j 个 part, 在 (S_j) 里面肯定有最大值的地方, 那么这个像素点就认为是第 j 个 part 的位置
- 除了置信度损失, 还有一个亲和力损失, 也就是两个 part 之前的方向信息, 用于之后的连接
Hard Negative Mining
- 假设在一个分类任务中, 该分类器对某一个物体的分类能力能查, 也就是 predict 和 ground truth 相差很大, 对应的 loss 也很大, 为了让网络能够更好的区分这个类别, 把这个难样本添加到负样本中进行训练, 但是这样也会有一个问题, 渐渐地会导致样本失衡。
- 别人的补充: Hard example往往是前景和背景区域的过渡部分,因为这些样本很难区分,所以叫做Hard Example。
- 训练过程
- 我们先用初始的正负样本(一般是正样本+与正样本同规模的负样本的一个子集)训练分类器, 然后再用训练出的分类器对样本进行分类, 把其中负样本中错误分类的那些样本(hard negative)放入负样本集合, 再继续训练分类器, 如此反复, 直到达到停止条件(比如分类器性能不再提升).
RetinaNet
- 创新点就是使用了 Focal Loss
- 网络结构为 ResNet + PRN + Faster R-CNN
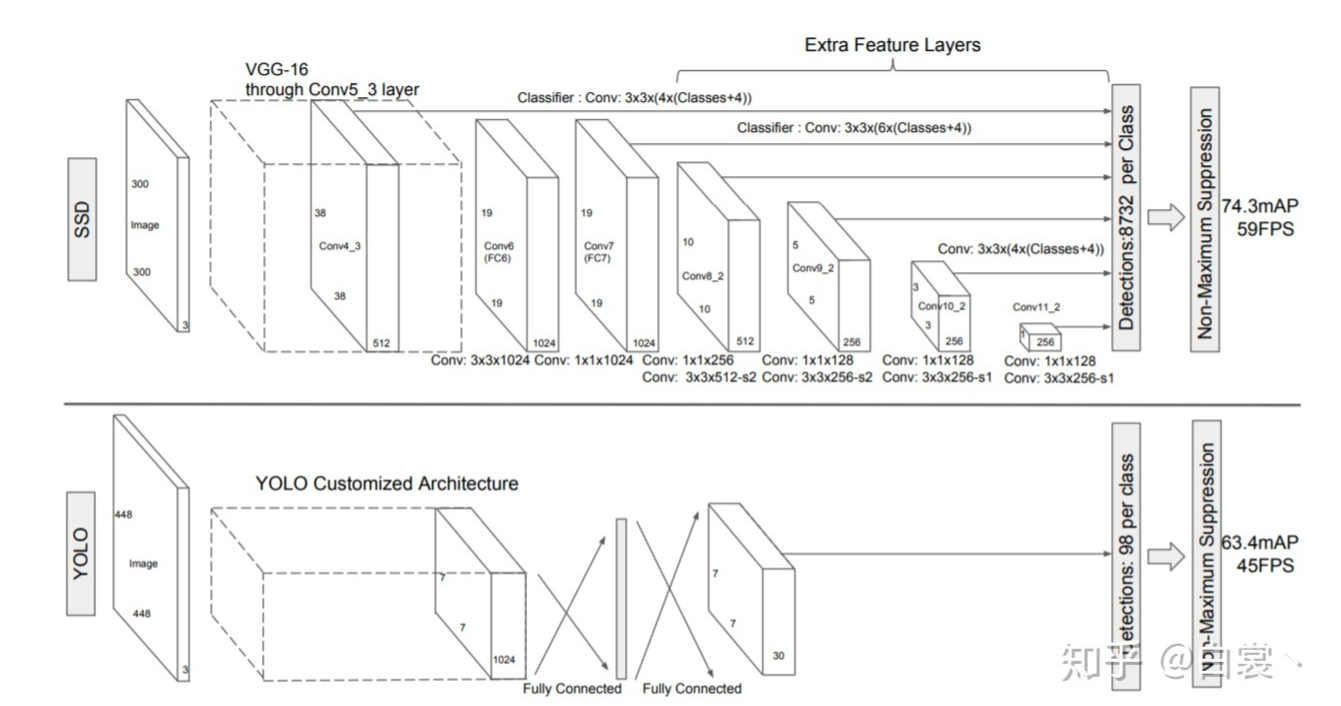
SSD
- 和 YOLO 算法一样, 对小物体检测效果不好
- 在不断卷积的过程中, feature map 会越来越小, 提取到的语义特征也会越来越抽象和高级, 但是经过下采样之后损失了很多的位置信息等, 对大物体没有太大的影响, 因为物体大, 对应的 bbox 也就大, 出现一点偏差不会对结果产生太大的影响, 但是对于小物体则完全不同, 物体小, 对应的 bbox 也就小, 如果 bbox 出现了误差, bbox 发生了一点的偏移, 就可能导致物体飞到了 bbox 的外面。
- 特点
- 使用了特征金字塔
- 借鉴了 Faster R-CNN 的 anchors(Faster R-CNN 是 9 个, 这里是 4 个)
- 框回归的损失函数和 Faster R-CNN 很像, 学习的是 anchor 到 gt 的偏移量
- YOLO 只使用了最后一层进行预测(也就是没有使用特征金字塔), 采用的是全连接的方式, 而 SSD 使用了特征金字塔, 有 6 个卷积层进行预测, 同时将全连接层替换成了全卷积层, 大大减少了参数, 提高了速度。
- 流程图
其他
- 深层网络容易响应语义特, 浅层网络容易响应图像特征, 也就是浅层网络包含了更多的几何信息, 包括物体的边缘, 线条, 位置信息等, 所以不适合定位; 深层网络因为得到的feature map太小, 虽然可以很好的捕捉语义特征, 但是丢失了几何特征, 而浅层网络, 包含了较多的几何特征, 但是语义特征不多, 不利于图像的分类
- 如果两个像素的值很像相近, 则他们的信息量对很低, 因为不能提供很多的信息, 但是如果两个像素的值相差比较大的话, 则包含的信息量会比较高
- DarkNet 出现的光晕问题, 是因为滑动 patch 中去最小值, 因为 patch 的移动的不确定性导致边缘在变化导致出现光晕现象