前期准备:
1.默认已经搭建好了hadoop环境(我的hadoop版本是2.5.0)
2.这里我用的Hbase是0.98.6,spark是1.3.0
一、搭建Hbase
1、上传Hbase安装包,将/opt/software下的hbase安装包解压到/opt/app目录下
2、进入hbase目录下,修改配置文件
1>修改hbase-env.sh文件
将export JAVA_HOME = 你的Java安装路径,我的路径是/opt/app/jdk1.7.0_79
所以改完后是 export JAVA_HOME=/opt/app/jdk1.7.0_79
2>修改hbase-site.xml文件,改成以下内容
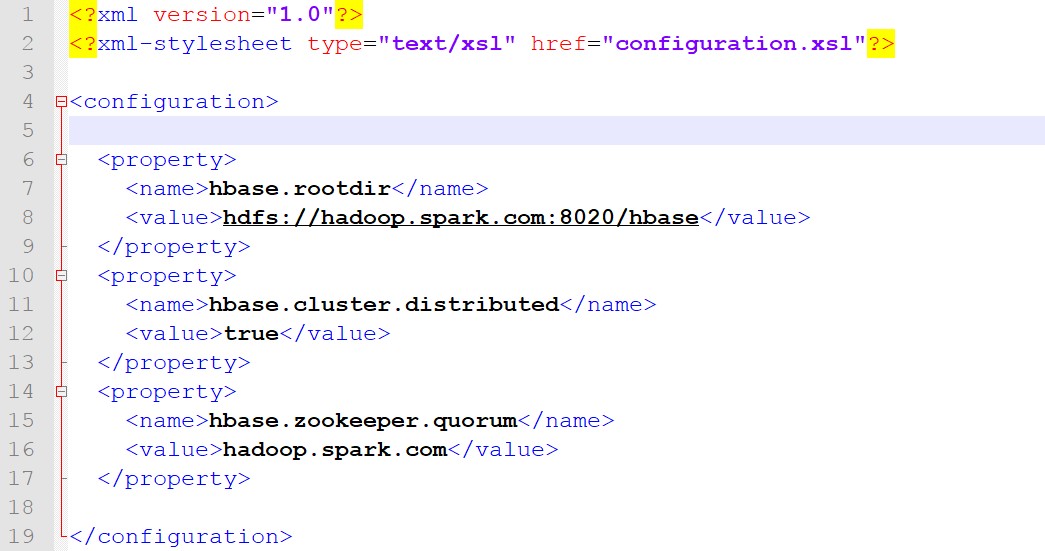
说明:
这里hadoop.spark.com是我的主机名,如果大家没有配置ip地址映射的话,这里就应该是你ip地址
这里hbase.zookeeper.quorum的值是zookeeper所在的机器,我这里是伪分布式,所以还是我的主机名
3>修改regionservers文件
将localhost 替换成 你的主机名(已经配置ip地址映射)或者ip地址
至此,Hbase环境搭建完成
二、搭建Spark
1.首先安装scala(也可以不安装scala)
1>上传scala安装包,将/opt/software/下的scala安装包解压到/opt/app/目录下
2>配置scala环境变量
切换到root用户下,编辑/etc/profile文件,在文件末尾加上环境路径
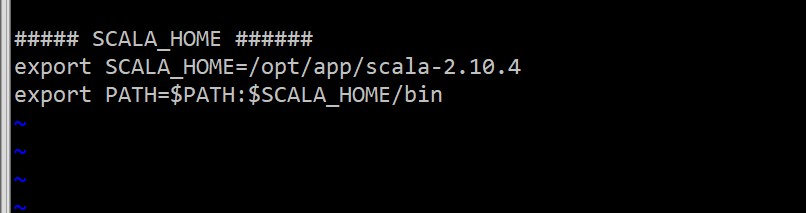
3>重启/etc/profile文件后者重启系统
source /etc/profile 或者 reboot
4>检查scala安装
scala -version
2、安装Spark
1>上传scala安装包,并将/opt/software目录下的scala安装包解压到/opt/app/目录下
2>上传spark安装包,并将/opt/software目录下的spark安装包解压到/opt/app/目录下
3>进入Spark目录下,修改配置文件
-
-
- 将slaves.template文件重命名为slaves,并将里面的内容改成你的主机名或者你的ip地址
- 将log4j.properties.template文件重命名为log4j.properties,里面的内容不做任何修改,这个文件是记录日志的
- 将spark-env.template文件重命名为spark-env,修改成以下:
-
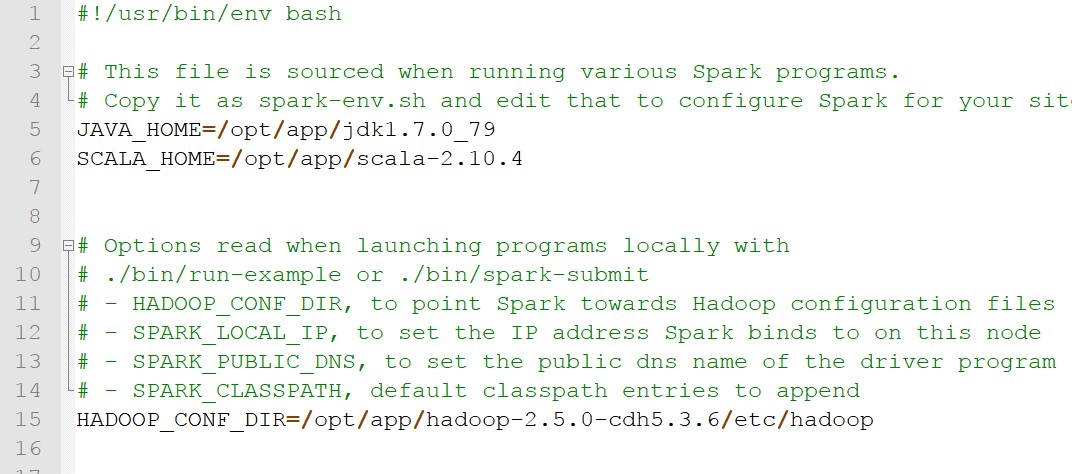
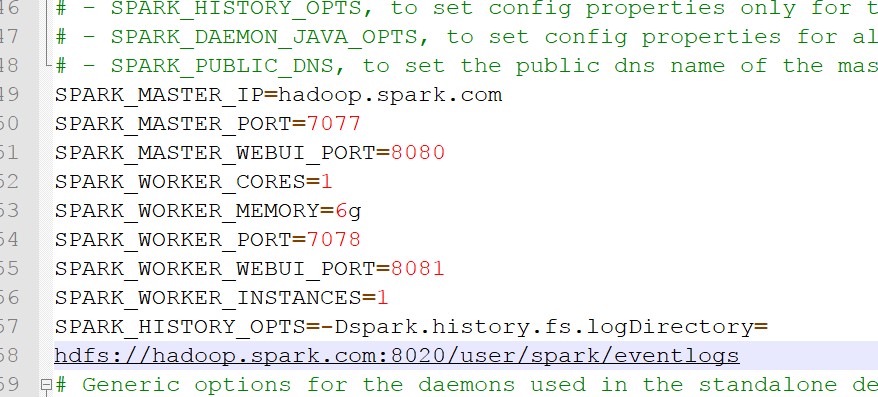
注意:这里SPARK_HISTORY_OPTS=......,要一行写完,我这里是为了演示,所以分两行写
-
-
- 将spark-default.conf.template文件重命名为spark-default.conf,修改完成后内容如下
-
至此,spark环境搭建成功了
三、搭建SparkStreaming
1.安装netcat服务器
先检查本地系统有没有安装nc,默认是没有安装的,查看命令:rpm -qa | grep nc,然后将nc-1.84-22.el6.x86_64.rpm安装包上传到/opt/software/目录下,
进入/opt/software/目录下,执行rpm -ivh nc-1.84-22.el6.x86_64.rpm 进行安装,也可以联网,yum install -y nc进行安装
2.测试sparkstreaming
在一个窗口中启动netcat服务器,命令:nc -lk 9999
在另一个窗口中运行Demo,命令:bin/run-example streaming.NetworkWordCount 主机名 9999
然后在netcat服务器的那个窗口中输入单词,注意单词之间用空格隔开,然后注意观察在另一个窗口中能不能进行单词统计
3.与kafka集成
1>安装zookzookeeper
解压zookeeper,将配置文件zoo.si...cfh重命名为zoo.cfg,然后将里面的dataDir目录指定一下,我这里指定是:/opt/app/zookeeper-3.4.5-cdh5.3.6/data/zkData
2>安装kafka
解压kafka,并把kafka里面libs目录下的zookeeper.....jar删除,然后将zookeeper下的zookeeper....jar拷贝到里面
修改配置文件server.properties,将里面的host.name,log.dirs,zookeeper.connect,三处进行指定
修改配置文件producer.properties,将里面的metadata.broker,进行指定
3>测试kafka
a.启动zookeeper,命令:bin/zkServer.sh start
b.启动kafka集群,命令:nohup bin/kafka-server-start.sh config/server.properties &
c.创建topic,命令:bin/kafka-topics.sh --create --zookeeper hadoop.spark.com:2181 --replication-factor 1 --partitions 1 --topic test
d.查看已有的topic,命令:bin/kafka-topics.sh --list --zookeeper hadoop.spark.com:2181
e.生产数据,命令:bin/kafka-console-producer.sh --broker-list hadoop.spark.com:9092 --topic test
f.消费数据,命令:bin/kafka-console-consumer.sh --zookeeper hadoop.spark.com:2181 --topic test --from-beginning