本次作业要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3363
Hadoop综合大作业 要求:
1.将爬虫大作业产生的csv文件上传到HDFS
2.对CSV文件进行预处理生成无标题文本文件
首先建立一个用于运行本案例的目录bigdatacase

给hadoop赋予对bigdatacase的各种操作权限

进入bigdatacase创建一个dataset目录用于保存数据集

爬虫大作业产生的csv文件从共享文件中拷贝到当前保存数据集dataset目录下

在本地查看数据集
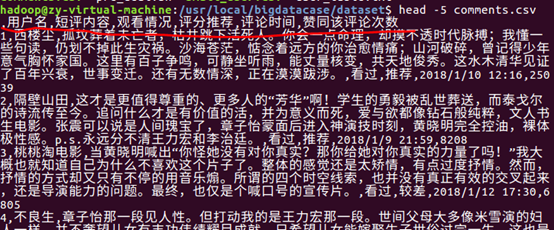
预处理:
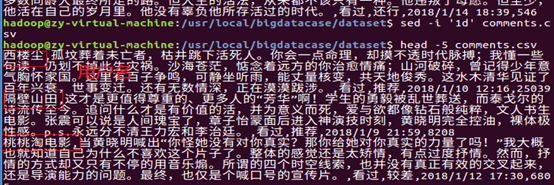
①序号列在此没有意义,从共享文件中删掉然后重新导入到该目录下处理,得出最终的预处理数据
② 使用awk脚本(com_pre_deal.sh)稍作处理,分隔开每一列
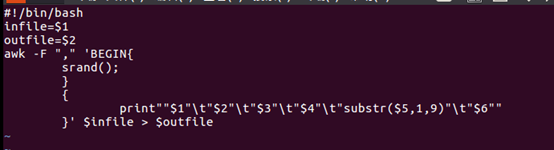
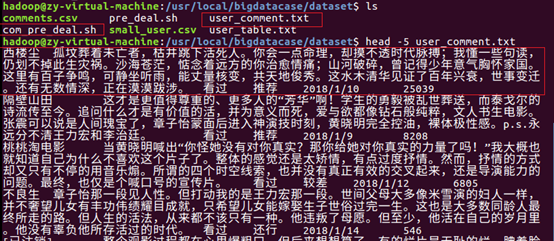
执行com_pre_deal.sh脚本文件,来对comments.csv进行数据预处理

查看生成的user_comment.txt,可以看到每个用户评价的各字段(用户名、短评内容、观看情况、评分推荐、评论时间、赞同该评论次数、)都是以Tab键距离隔开,预处理完成。
启动hdfs
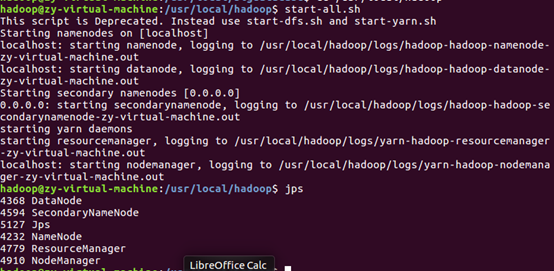
在hdfs上建立/bigdatacase/dataset文件夹

把user_comment.txt上传到HDFS中,并查看前10条记录
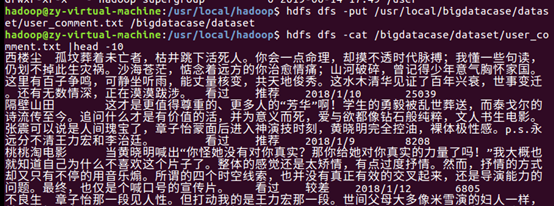
3.把hdfs中的文本文件最终导入到数据仓库Hive中
4.在Hive中查看并分析数据
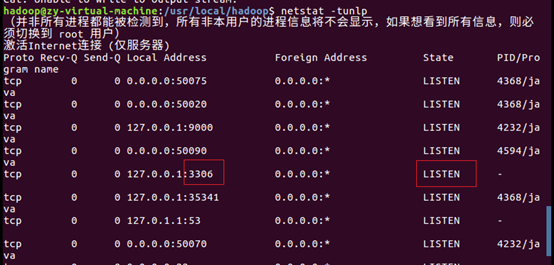
使用netstat -tunlp 查看端口 :3306 LISION确定已经启动了MySql数据库(否则使用$service mysql start启动)
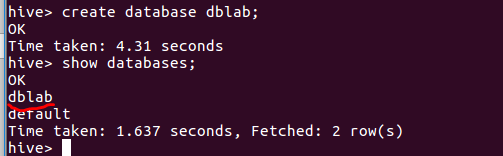
启动Hive,并创建一个数据库dblab
创建外部表,把HDFS中的“/bigdatacase/dataset”目录下的数据(注意要删除之前练习时的数据user_table.txt,只剩下目标数据,否则会把数据叠加在一起!)加载到了数据仓库Hive中


在Hive中查看数据
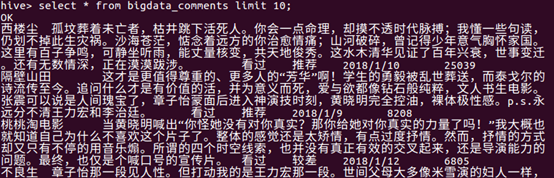
5.用Hive对爬虫大作业产生的进行数据分析,写一篇博客描述你的分析过程和分析结果。(10条以上的查询分析)
①查询统计总数据量
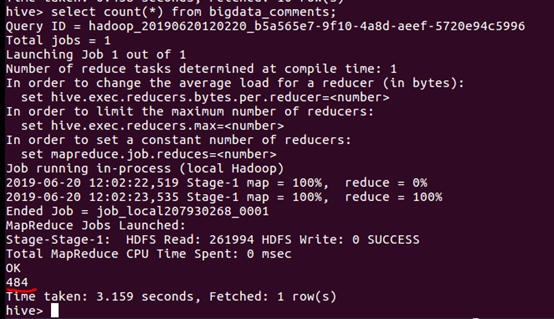
②用聚合函数count()加上distinct,查出主键user_name不重复的数据有多少条

③查询前10赞同该评论的评论内容
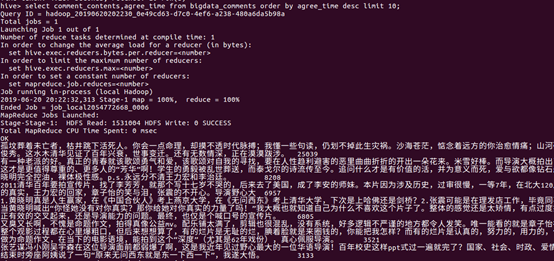
④查询后10赞同该评论的评论内容
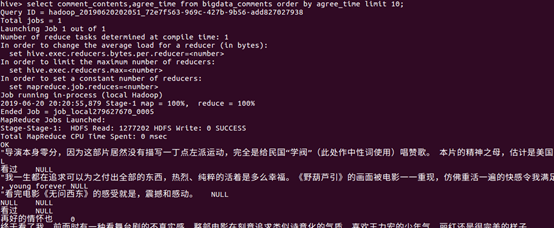
⑤查询统计前10高评评论时间;
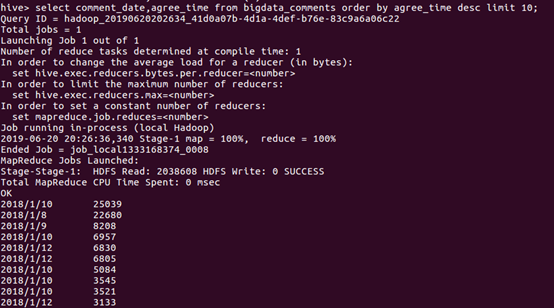
⑥统计高评价(”力荐”)的数量
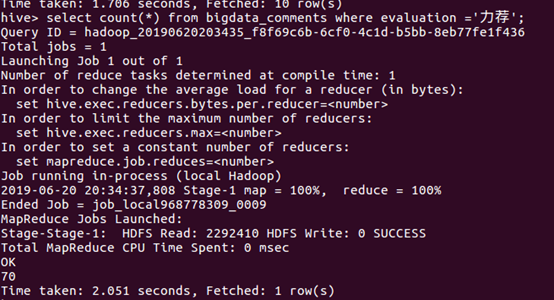
⑦统计”推荐”的数量
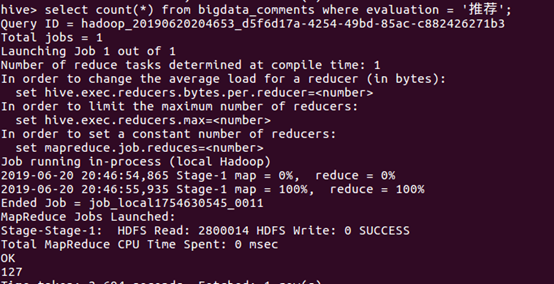
⑧统计“还行”的数量
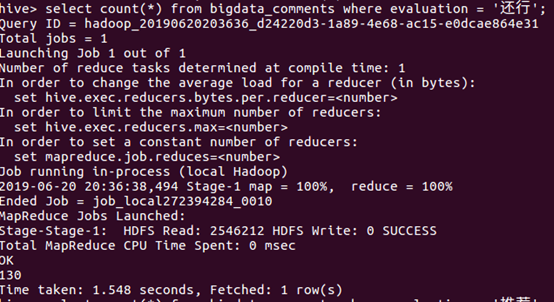
⑨统计“较差”的数量
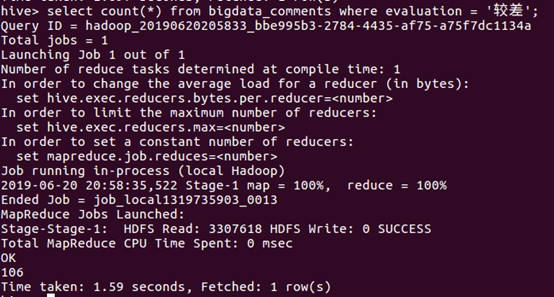
⑩统计“很差”的数量
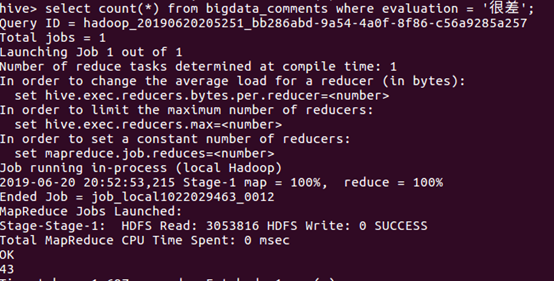
总结:
所爬取的数据都是用户观看过后的评论,用have进行了数据分析,从影评数据总量、用户名为主键不重复数(有些用户名是[已注销]状态,会被忽略)、查看前十高评内容、低评内容、评论时间、评分推荐各种情况加以分析得出《无问西东》电影还是很值的一看的,包含着浓浓的家国情怀和成长过程对自我的认识也起到了一定的帮助;不足:由于IP被封,爬取到的数据比较少只有大概500条,所以分析的结果可能不是很客观,算是一种抽样检查,