BeautifulSoup基础实战
安装:pip install beautifulsoup4
常用指令:
from bs4 import BeautifulSoup as bs
import urllib.request
data=urllib.request.urlopen("https://www.cnblogs.com/mcq1999/").read().decode("utf-8","ignore")
bs1=bs(data)
print(bs1.prettify()) #格式化输出
print(bs1.title) #获取标签title,bs对象.标签名
print(bs1.title.string) #获取标签title的文字
print(bs1.title.name) #获取标签名,如title
print(bs1.a.attrs) #获取属性列表 键值对
print(bs1.a['name']) #获取某个属性对应的值
print(bs1.find_all('a')) #提取所有某个节点的内容,传参是标签名
print('---------------------------------')
print(bs1.find_all(['a','ul']))
k1=bs1.ul.contents #提取当前节点的所有子节点,返回一个列表
k2=bs1.ul.children #返回一个生成器
allulc=[i for i in k2]
PhantomJS基础实战
效率不高,但可以解决很多反爬问题,本质是一个无界面的浏览器,通过命令行(或python)操纵。通常难点部分通过PhantomJS写,然后将数据交给urllib或scrapy进行后续处理。
目前已PhantomJS和selenium分手,以后再学。
分布式爬虫之docker基础
镜像:不可以改变内容
容器:可以改变内容,相当于虚拟机,默认情况下彼此封闭
优点:轻部署、省成本、部署迁移方便
安装:yum -y install docker
启动和关闭:
systemctl start docker
systemctl stop docker
启动时如果出现
可以参考下面这篇博客,我的就这样成功了,其他的方法都没用
https://blog.csdn.net/w1316022737/article/details/83692701
最好再修改一下docker的镜像源,不然运行的很慢:
https://blog.csdn.net/julien71/article/details/79760919
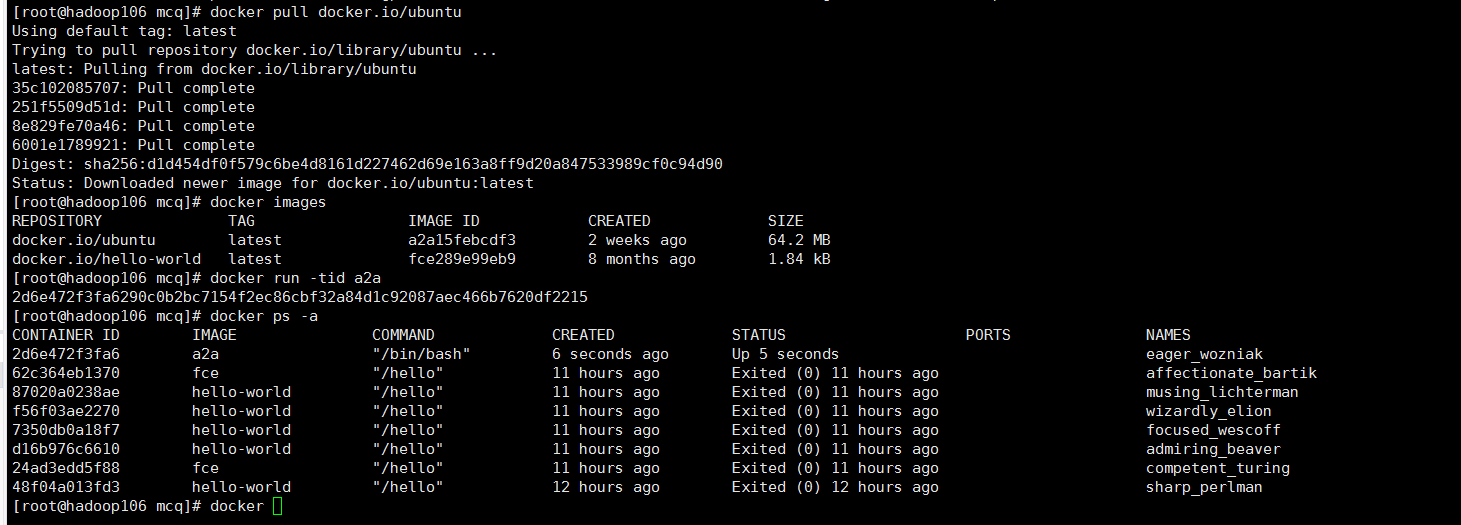
查看已有镜像:docker images
下载镜像:docker pull
创建容器:docker run -tid
查看容器:docker ps -a
进入容器:docker attach
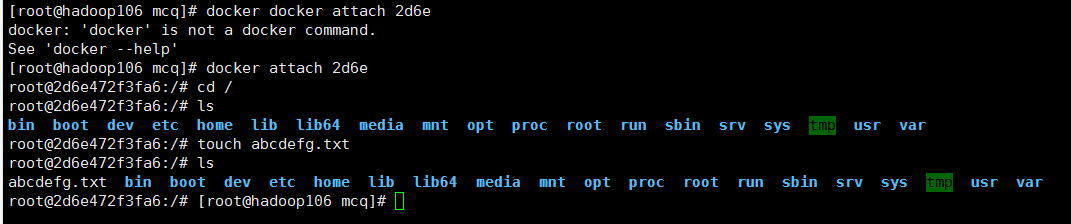
退出容器:一般不用exit,因为会停止容器。我们用ctrl+p+q即可。
在容器里的操作不会影响本机,相当于在虚拟机里再开了个虚拟机
启动容器:docker start …
封装容器成镜像:docker commit 2d6 mytest:v1

基于镜像给容器起名字: docker run -tid --name testabc a2a (基于a2a这个镜像创建一个名为testabs的容器)
docker run -tid --name h1 mytest:v1
docker run -tid --name h2 --link h1 mytest:v1 (将容器h2链接到h1,即让h2和h1通信)
这里我用ubuntu的镜像发现ping、yum等等命令都没有,所以改用了centos的镜像。
[root@hadoop106 mcq]# docker attach fe3
[root@fe3489945006 /]# cat /etc/hosts
127.0.0.1 localhost
::1 localhost ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
172.17.0.6 c1 4c3dab0e013c
172.17.0.7 fe3489945006
[root@fe3489945006 /]# ping 172.17.0.6
将docker镜像封装为文件:docker save -o /mytest.tar c3e8