对象的定义顺序和布局顺序是不一样的。我们在写代码的时候不用关心内存对齐问题,但是如果内存按照源代码定义顺序进行布局的话,由于cpu读取内存时是按寄存器(64位)大小单位载入的,如果载入的数据横跨两个64位,要操作该数据的话至少需要两次读取,加上组合移位,会产生效率问题,甚至会引发异常。比如在一些ARM处理器上,如果不按对齐要求访问数据, 会触发硬件异常。
在Class文件中,字段的定义是按照代码顺序排列的,虚拟机加载后会生成相应的数据结构,包含字段的名称,字段在对象中的偏移等。重新布局后,只要改变相应的偏移值即可。
获取到fields后,下面要在ClassFileParser::parseClassFile()函数中进行变量内存布局,如下:
FieldLayoutInfo info; layout_fields(class_loader, &fac, &parsed_annotations, &info, CHECK_NULL);
传入的fac是之前介绍的FieldAllocationCount类型的变量,里面已经保存了各个类型变量的数量。
1、静态变量的偏移量
代码如下:
int next_static_oop_offset;
int next_static_double_offset;
int next_static_word_offset;
int next_static_short_offset;
int next_static_byte_offset;
...
// Calculate the starting byte offsets
next_static_oop_offset = InstanceMirrorKlass::offset_of_static_fields();
next_static_double_offset = next_static_oop_offset + ( (fac->count[STATIC_OOP]) * heapOopSize );
if ( fac->count[STATIC_DOUBLE] &&
(
Universe::field_type_should_be_aligned(T_DOUBLE) || // 方法会返回true
Universe::field_type_should_be_aligned(T_LONG) // 方法会返回true
)
){
next_static_double_offset = align_size_up(next_static_double_offset, BytesPerLong);
}
next_static_word_offset = next_static_double_offset + ((fac->count[STATIC_DOUBLE]) * BytesPerLong);
next_static_short_offset = next_static_word_offset + ((fac->count[STATIC_WORD]) * BytesPerInt);
next_static_byte_offset = next_static_short_offset + ((fac->count[STATIC_SHORT]) * BytesPerShort);
静态变量存储在镜像类InstanceMirrorKlass中,调用offset_of_static_fields()方法获取_offset_of_static_fields属性,也就是存储静态字段的偏移量。
在计算next_static_double_offset时,因为首先布局的是oop,所以内存很可能不是按8字节对齐,需要调用align_size_up()方法对内存进行8字节对齐,后面就不需要对齐了,因为一定是自然对齐,8字节对齐肯定是4字节对齐的,4字节对齐肯定是2字节对齐的。
调用InstanceMirrorKlass::offset_of_static_fields()方法会获取到InstanceMirrorKlass类的_offset_of_static_fields属性的值,设置_offset_of_static_fields属性的方法如下:
static void init_offset_of_static_fields() {
// java.lang.Class类使用InstanceMirrorKlass对象来表示,而java.lang.Class对象通过Oop对象来表示,那么imk->size_helper()获取的就是
// Oop对象的大小,左移3位将字转换为字节
InstanceMirrorKlass* imk = InstanceMirrorKlass::cast(SystemDictionary::Class_klass());
_offset_of_static_fields = imk->size_helper() << LogHeapWordSize; // LogHeapWordSize=3
}
静态字段紧挨着存储在java.lang.Class对象本身占用的内存大小之后。
按照oop、double、word、short、byte的顺序计算各个静态变量的偏移量,next_static_xxx_offset指向的就是第一个xxx类型的静态变量在InstanceMirrorKlass中的偏移量。可以看到,在fac中统计各个类型变量的数量就是为了方便在这里计算偏移量。
2、非静态变量的偏移量
计算非静态字段起始偏移量,在ClassFileParser::layout_fields()函数中有如下代码调用:
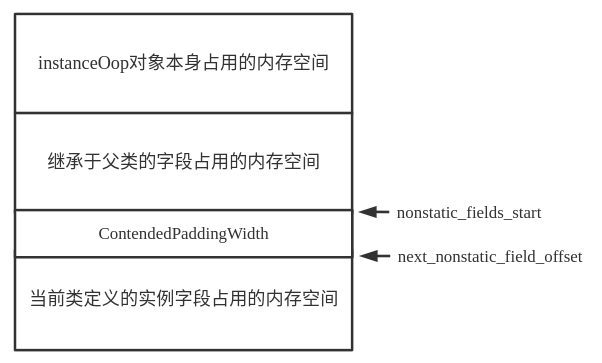
int nonstatic_field_size = _super_klass() == NULL ? 0 : _super_klass()->nonstatic_field_size(); ... int nonstatic_fields_start = instanceOopDesc::base_offset_in_bytes() + nonstatic_field_size * heapOopSize; next_nonstatic_field_offset = nonstatic_fields_start;
定义在instanceOop.hpp文件中的类instanceOopDesc中实现的base_offset_in_bytes()函数的实现如下:
// If compressed, the offset of the fields of the instance may not be aligned.
static int base_offset_in_bytes() {
// offset computation code breaks if UseCompressedClassPointers
// only is true
return ( UseCompressedOops && UseCompressedClassPointers ) ?
klass_gap_offset_in_bytes() : // 开启指针压缩后计算出来的值为12
sizeof(instanceOopDesc); // 在64位上计算出来为16
}
因为非静态变量存储在instanceOopDesc中,并且父类变量存储在前,所以nonstatic_fields_start变量表示的就是当前类定义的实例字段所要存储的起始偏移量位置。
子类会将父类中定义的所有非静态字段(包括private修饰的非静态字段)全部复制,以实现字段继承。所以上面在计算子类非静态字段的起始偏移量时,会将父类可被继承的字段占用的内存也考虑在内。如下图所示。

下面在计算非静态字段的偏移量时还需要考虑有@Contended注解的类和字段。对于类上的@Contended注解,需要在字段之前填充ContendedPaddingWidth字节,对于有@Contended注解的变量来说,需要单独考虑布局。相关实例变量的数量需要分别进行计算,如下代码所示。
// 在类上加@Contended注解的说明可参考:https://www.icode9.com/content-1-375023.html
bool is_contended_class = parsed_annotations->is_contended();
// Class is contended, pad before all the fields
if (is_contended_class) {
next_nonstatic_field_offset += ContendedPaddingWidth; // ContendedPaddingWidth=128
}
// Compute the non-contended fields count.
// The packing code below relies on these counts to determine if some field
// can be squeezed into the alignment gap. Contended fields are obviously exempt from that.
unsigned int nonstatic_double_count = fac->count[NONSTATIC_DOUBLE] - fac_contended.count[NONSTATIC_DOUBLE];
unsigned int nonstatic_word_count = fac->count[NONSTATIC_WORD] - fac_contended.count[NONSTATIC_WORD];
unsigned int nonstatic_short_count = fac->count[NONSTATIC_SHORT] - fac_contended.count[NONSTATIC_SHORT];
unsigned int nonstatic_byte_count = fac->count[NONSTATIC_BYTE] - fac_contended.count[NONSTATIC_BYTE];
unsigned int nonstatic_oop_count = fac->count[NONSTATIC_OOP] - fac_contended.count[NONSTATIC_OOP];
// Total non-static fields count, including every contended field
unsigned int nonstatic_fields_count = fac->count[NONSTATIC_DOUBLE] +
fac->count[NONSTATIC_WORD] +
fac->count[NONSTATIC_SHORT] +
fac->count[NONSTATIC_BYTE] +
fac->count[NONSTATIC_OOP];
这里涉及到了对有@Contended注解的实例变量的处理,为了避免伪共享的问题,可能需要在2个变量的存储布局之间填充一些数据或空白。这个问题在前一篇已经介绍过,这里不再介绍。
如果类上有@Contended注解,最终的相关变量更新后指向如下:
在HotSpot中,对象布局有三种模式,如下:
- allocation_style=0,字段排列顺序为oops、longs/doubles、ints、shorts/chars、bytes,最后是填充字段,以满足对齐要求;
- allocation_style=1,字段排列顺序为longs/doubles、ints、shorts/chars、bytes、oops,最后是填充字段,以满足对齐要求;
- allocation_style=2,JVM在布局时会尽量使父类oops和子类oops挨在一起。
另外,由于填充会形成空隙,比如使用压缩指针时,头占12字节,后面如果是long类型变量的话,long的对齐要求是8字节,中间会有4个字节的空隙,为了提高内存利用率, 可以把int/short/byte等相对内存占用比较小的对象塞进去,与此同时JVM提供了-XX:+/-CompactFields命令控制该特性,默认开启。
bool compact_fields = CompactFields; // 默认值为true
int allocation_style = FieldsAllocationStyle; // 默认的布局为1
// ...
// Rearrange fields for a given allocation style
if( allocation_style == 0 ) {
// Fields order: oops, longs/doubles, ints, shorts/chars, bytes, padded fields
next_nonstatic_oop_offset = next_nonstatic_field_offset; // 首先布局oop类型的变量
next_nonstatic_double_offset = next_nonstatic_oop_offset + (nonstatic_oop_count * heapOopSize);
}
else if( allocation_style == 1 ) {
// Fields order: longs/doubles, ints, shorts/chars, bytes, oops, padded fields
next_nonstatic_double_offset = next_nonstatic_field_offset; // 首先布局long/double类型的变量
}
else if( allocation_style == 2 ) {
// Fields allocation: oops fields in super and sub classes are together.
if(
nonstatic_field_size > 0 && // nonstatic_field_size指的是父类的非静态变量占用的大小
_super_klass() != NULL &&
_super_klass->nonstatic_oop_map_size() > 0
){
unsigned int map_count = _super_klass->nonstatic_oop_map_count();
OopMapBlock* first_map = _super_klass->start_of_nonstatic_oop_maps();
OopMapBlock* last_map = first_map + map_count - 1;
int next_offset = last_map->offset() + (last_map->count() * heapOopSize);
if (next_offset == next_nonstatic_field_offset) {
allocation_style = 0; // allocate oops first
next_nonstatic_oop_offset = next_nonstatic_field_offset;
next_nonstatic_double_offset = next_nonstatic_oop_offset + (nonstatic_oop_count * heapOopSize);
}
}
if( allocation_style == 2 ) {
allocation_style = 1; // allocate oops last
next_nonstatic_double_offset = next_nonstatic_field_offset;
}
}
else {
ShouldNotReachHere();
}
对于allocation_style属性的值为0与为1时的逻辑非常好理解,当为2时,如果父类有OopMapBlock,那么_super_klass->nonstatic_oop_map_size()大于0,并且父类将oop布局在末尾时,此时可使用allocation_style=0来布局,这样子类会首先将自己的oop布局在开始,正好和父类的oop连在一起,有利于GC扫描处理引用。剩下的其它情况都是按allocation_style属性的值为1来布局的,也就是oop在末尾。后面在介绍了OopMapBlock后就会对allocation_style等于2时的代码逻辑有更充分的理解。
选定了布局策略allocation_style后,首先要向空隙中填充属性,如下:
// count
int nonstatic_oop_space_count = 0;
int nonstatic_word_space_count = 0;
int nonstatic_short_space_count = 0;
int nonstatic_byte_space_count = 0;
// offset
int nonstatic_oop_space_offset;
int nonstatic_word_space_offset;
int nonstatic_short_space_offset;
int nonstatic_byte_space_offset;
// Try to squeeze some of the fields into the gaps due to long/double alignment.
// 向补白空隙中填充字段,填充的顺序为int、short、byte、oopmap
if( nonstatic_double_count > 0 ) { // 当有long/double类型的实例变量存在时,可能存在空隙
int offset = next_nonstatic_double_offset;
next_nonstatic_double_offset = align_size_up(offset, BytesPerLong);
// 只有开启了-XX:+CompactFields命令时才会进行空白填充
if( compact_fields && offset != next_nonstatic_double_offset ) {
// Allocate available fields into the gap before double field.
int length = next_nonstatic_double_offset - offset;
assert(length == BytesPerInt, "");
// nonstatic_word_count记录了word的总数,由于这个gap算一个特殊位置,故把放入这里的word从正常情况删除,
// 并加入特殊的nonstatic_word_space_count中。
nonstatic_word_space_offset = offset;
if( nonstatic_word_count > 0 ) { // 由于long/double是8字节对齐,所以最多只能有7个字节的空隙,最多只能填充一个word类型的变量
nonstatic_word_count -= 1;
nonstatic_word_space_count = 1; // Only one will fit
length -= BytesPerInt;
offset += BytesPerInt;
}
nonstatic_short_space_offset = offset;
while( length >= BytesPerShort && nonstatic_short_count > 0 ) {
nonstatic_short_count -= 1;
nonstatic_short_space_count += 1;
length -= BytesPerShort;
offset += BytesPerShort;
}
nonstatic_byte_space_offset = offset;
while( length > 0 && nonstatic_byte_count > 0 ) {
nonstatic_byte_count -= 1;
nonstatic_byte_space_count += 1;
length -= 1;
}
// Allocate oop field in the gap if there are no other fields for that.
nonstatic_oop_space_offset = offset;
// when oop fields not first
// heapOopSize在开启指针压缩时为4,否则为8,所以一个oop占用的字节数要看heapOopSize的大小,理论上空隙也最多
// 只能存放一个oop对象
// allocation_style必须不等于0,因为等于0时,oop要分配到开始的位置,和父类的oop进行连续存储,不能
// 进行空隙填充
if( length >= heapOopSize && nonstatic_oop_count > 0 && allocation_style != 0 ) {
nonstatic_oop_count -= 1;
nonstatic_oop_space_count = 1; // Only one will fit
length -= heapOopSize;
offset += heapOopSize;
}
}
}
long/double类型占用8字节,对齐时,最多可能留下7字节的空白。Java数据类型与JVM内部定义的5种数据类型的对应关系如下表所示。
| Java数据类型 | JVM内部数据类型 | 数据宽度 |
| reference | oop | 4字节(指针压缩)/8字节 |
| boolean/byte | byte | 1字节 |
| char/short | short | 2字节 |
| int/float | word | 4字节 |
| long/double | double | 8字节 |
有可能对齐后会有最多7字节的空隙,这样就可按顺序填充int/float、char/short、boolean/byte及引用类型,充分利用了内存空间。
下面开始计算非静态变量的偏移量,如下:
next_nonstatic_word_offset = next_nonstatic_double_offset + (nonstatic_double_count * BytesPerLong);
next_nonstatic_short_offset = next_nonstatic_word_offset + (nonstatic_word_count * BytesPerInt);
next_nonstatic_byte_offset = next_nonstatic_short_offset + (nonstatic_short_count * BytesPerShort);
next_nonstatic_padded_offset = next_nonstatic_byte_offset + nonstatic_byte_count;
// let oops jump before padding with this allocation style
// 为1时的布局为: // Fields order: longs/doubles, ints, shorts/chars, bytes, oops, padded fields
if( allocation_style == 1 ) {
next_nonstatic_oop_offset = next_nonstatic_padded_offset;
if( nonstatic_oop_count > 0 ) {
next_nonstatic_oop_offset = align_size_up(next_nonstatic_oop_offset, heapOopSize);
}
next_nonstatic_padded_offset = next_nonstatic_oop_offset + (nonstatic_oop_count * heapOopSize);
}
将各个类型的变量在instanceOop中的偏移量计算好后,下面就是计算每个变量的实际偏移量了。
3、计算每个变量的偏移量
代码如下:
// Iterate over fields again and compute correct offsets.
// The field allocation type was temporarily stored in the offset slot.
// oop fields are located before non-oop fields (static and non-static).
for (AllFieldStream fs(_fields, _cp); !fs.done(); fs.next()) {
// skip already laid out fields
if (fs.is_offset_set())
continue;
// contended instance fields are handled below
if (fs.is_contended() && !fs.access_flags().is_static()){
continue; // 这个循环逻辑不处理有@Contended注解的实例变量
}
int real_offset;
FieldAllocationType atype = (FieldAllocationType) fs.allocation_type();
// pack the rest of the fields
switch (atype) {
case STATIC_OOP:
real_offset = next_static_oop_offset;
next_static_oop_offset += heapOopSize;
break;
case STATIC_BYTE:
real_offset = next_static_byte_offset;
next_static_byte_offset += 1;
break;
case STATIC_SHORT:
real_offset = next_static_short_offset;
next_static_short_offset += BytesPerShort;
break;
case STATIC_WORD:
real_offset = next_static_word_offset;
next_static_word_offset += BytesPerInt;
break;
case STATIC_DOUBLE:
real_offset = next_static_double_offset;
next_static_double_offset += BytesPerLong;
break;
case NONSTATIC_OOP:
if( nonstatic_oop_space_count > 0 ) {
real_offset = nonstatic_oop_space_offset;
nonstatic_oop_space_offset += heapOopSize;
nonstatic_oop_space_count -= 1;
} else {
real_offset = next_nonstatic_oop_offset;
next_nonstatic_oop_offset += heapOopSize;
}
// Update oop maps
if(
nonstatic_oop_map_count > 0 &&
nonstatic_oop_offsets[nonstatic_oop_map_count - 1] ==
real_offset - int(nonstatic_oop_counts[nonstatic_oop_map_count - 1]) * heapOopSize
){
// Extend current oop map
nonstatic_oop_counts[nonstatic_oop_map_count - 1] += 1;
} else {
// Create new oop map
nonstatic_oop_offsets[nonstatic_oop_map_count] = real_offset;
nonstatic_oop_counts [nonstatic_oop_map_count] = 1;
nonstatic_oop_map_count += 1;
if( first_nonstatic_oop_offset == 0 ) { // Undefined
first_nonstatic_oop_offset = real_offset;
}
}
break;
case NONSTATIC_BYTE:
if( nonstatic_byte_space_count > 0 ) {
real_offset = nonstatic_byte_space_offset;
nonstatic_byte_space_offset += 1;
nonstatic_byte_space_count -= 1;
} else {
real_offset = next_nonstatic_byte_offset;
next_nonstatic_byte_offset += 1;
}
break;
case NONSTATIC_SHORT:
if( nonstatic_short_space_count > 0 ) {
real_offset = nonstatic_short_space_offset;
nonstatic_short_space_offset += BytesPerShort;
nonstatic_short_space_count -= 1;
} else {
real_offset = next_nonstatic_short_offset;
next_nonstatic_short_offset += BytesPerShort;
}
break;
case NONSTATIC_WORD:
if( nonstatic_word_space_count > 0 ) {
real_offset = nonstatic_word_space_offset;
nonstatic_word_space_offset += BytesPerInt;
nonstatic_word_space_count -= 1;
} else {
real_offset = next_nonstatic_word_offset;
next_nonstatic_word_offset += BytesPerInt;
}
break;
case NONSTATIC_DOUBLE:
real_offset = next_nonstatic_double_offset;
next_nonstatic_double_offset += BytesPerLong;
break;
default:
ShouldNotReachHere();
} // end switch
fs.set_offset(real_offset); // 设置真正的偏移量
} // end for
由于第一个变量的偏移量已经计算好,所以接下来就按顺序进行连续存储即可。不过由于实例变量会填充到空隙中,所以还需要考虑这一部分的变量,剩下的同样是通过计算出来的偏移量连续存储即可。最终算出来的每个变量的偏移量要调用fs.set_offset()保存起来,这样就能快速找到这些变量的存储位置了。
对于NONSTATIC_OOP类型的变量来说,会涉及到OopMapBlock,这个知识点在下一篇中将详细介绍。
4、@Contended变量的偏移量
实现代码如下:
// Handle the contended cases.
//
// Each contended field should not intersect the cache line with another contended field.
// In the absence of alignment information, we end up with pessimistically separating
// the fields with full-width padding.
//
// Additionally, this should not break alignment for the fields, so we round the alignment up
// for each field.
if (nonstatic_contended_count > 0) { // 标注有@Contended注解的字段数量
// if there is at least one contended field, we need to have pre-padding for them
next_nonstatic_padded_offset += ContendedPaddingWidth;
// collect all contended groups
BitMap bm(_cp->size());
for (AllFieldStream fs(_fields, _cp); !fs.done(); fs.next()) {
// skip already laid out fields
if (fs.is_offset_set()){
continue;
}
if (fs.is_contended()) {
bm.set_bit(fs.contended_group());
}
}
// 将同一组的@Contended变量布局在一起
int current_group = -1;
while ((current_group = (int)bm.get_next_one_offset(current_group + 1)) != (int)bm.size()) {
for (AllFieldStream fs(_fields, _cp); !fs.done(); fs.next()) {
// skip already laid out fields
if (fs.is_offset_set())
continue;
// skip non-contended fields and fields from different group
if (!fs.is_contended() || (fs.contended_group() != current_group))
continue;
// handle statics below
if (fs.access_flags().is_static())
continue;
int real_offset;
FieldAllocationType atype = (FieldAllocationType) fs.allocation_type();
switch (atype) {
case NONSTATIC_BYTE:
next_nonstatic_padded_offset = align_size_up(next_nonstatic_padded_offset, 1);
real_offset = next_nonstatic_padded_offset;
next_nonstatic_padded_offset += 1;
break;
case NONSTATIC_SHORT:
next_nonstatic_padded_offset = align_size_up(next_nonstatic_padded_offset, BytesPerShort);
real_offset = next_nonstatic_padded_offset;
next_nonstatic_padded_offset += BytesPerShort;
break;
case NONSTATIC_WORD:
next_nonstatic_padded_offset = align_size_up(next_nonstatic_padded_offset, BytesPerInt);
real_offset = next_nonstatic_padded_offset;
next_nonstatic_padded_offset += BytesPerInt;
break;
case NONSTATIC_DOUBLE:
next_nonstatic_padded_offset = align_size_up(next_nonstatic_padded_offset, BytesPerLong);
real_offset = next_nonstatic_padded_offset;
next_nonstatic_padded_offset += BytesPerLong;
break;
case NONSTATIC_OOP:
next_nonstatic_padded_offset = align_size_up(next_nonstatic_padded_offset, heapOopSize);
real_offset = next_nonstatic_padded_offset;
next_nonstatic_padded_offset += heapOopSize;
// Create new oop map
assert(nonstatic_oop_map_count < max_nonstatic_oop_maps, "range check");
nonstatic_oop_offsets[nonstatic_oop_map_count] = real_offset;
nonstatic_oop_counts [nonstatic_oop_map_count] = 1;
nonstatic_oop_map_count += 1;
if( first_nonstatic_oop_offset == 0 ) { // Undefined
first_nonstatic_oop_offset = real_offset;
}
break;
default:
ShouldNotReachHere();
}
if (fs.contended_group() == 0) {
// Contended group defines the equivalence class over the fields:
// the fields within the same contended group are not inter-padded.
// The only exception is default group, which does not incur the
// equivalence, and so requires intra-padding.
next_nonstatic_padded_offset += ContendedPaddingWidth;
}
fs.set_offset(real_offset);
} // end for
// Start laying out the next group.
// Note that this will effectively pad the last group in the back;
// this is expected to alleviate memory contention effects for
// subclass fields and/or adjacent object.
// If this was the default group, the padding is already in place.
if (current_group != 0) {
next_nonstatic_padded_offset += ContendedPaddingWidth;
}
} // end while
// handle static fields
}
同为一组的、有@Contended注解的变量要布局在一起。同一组的变量可能类型不同,并且也不会遵循之前介绍的对实例变量的布局策略,所以要在每次开始之前调用align_size_up()进行对齐操作。在布局完一组后要填充ontendedPaddingWidth个字节,然后使用相同的逻辑布局下一组的变量。最终的变量偏移量同样会调用fs.set_offset()保存起来,以方便后续进行偏移查找。
相关文章的链接如下:
1、在Ubuntu 16.04上编译OpenJDK8的源代码
13、类加载器
14、类的双亲委派机制
15、核心类的预装载
16、Java主类的装载
17、触发类的装载
18、类文件介绍
19、文件流
20、解析Class文件
21、常量池解析(1)
22、常量池解析(2)
23、字段解析(1)
24、字段解析之伪共享(2)
作者持续维护的个人博客classloading.com。
关注公众号,有HotSpot源码剖析系列文章!

参考文章:
(1)成员变量重排序