Python 数据库框架
选择数据库框架的因素:
- 易用性:抽象层,也称为对象关系映射(Object-Relational Mapper,ORM)或对象文档映射(Object-Document Mapper,ODM),在用户不知觉的情况下把高层的面向对象操作转换成低层的数据库指令。
- 性能:ORM 和 ODM 把对象业务转换成数据库业务会有一定的损耗。真正的关键点在于如何选择一个能直接操作低层数据库的抽象层,以防特定的操作需要直接使用数据库原生指令优化。
- 可移植性:必须考虑其是否能在你的开发平台和生产平台中使用。
项目结构搭建
application
|____application web目录
|____manage.py 脚本数据
|____runserver.py 启动服务器
| |______init__.py 模块导出文件
| |____app.conf 配置文件
| |____models.py 数据模型
| |____views.py 视图
| |____static 静态文件
| |____templates 页面模板
| | |____base.html
| | |____index.html
| | |____login.html
1. Flask安装和框架(官网演示)
Flask官网: http://flask-sqlalchemy.pocoo.org/
中文 http://www.pythondoc.com/flask-sqlalchemy/
Flask安装:pip3 install Flask-SQLAlchemy
PyMySQL:pip3 install Flask-PYMy
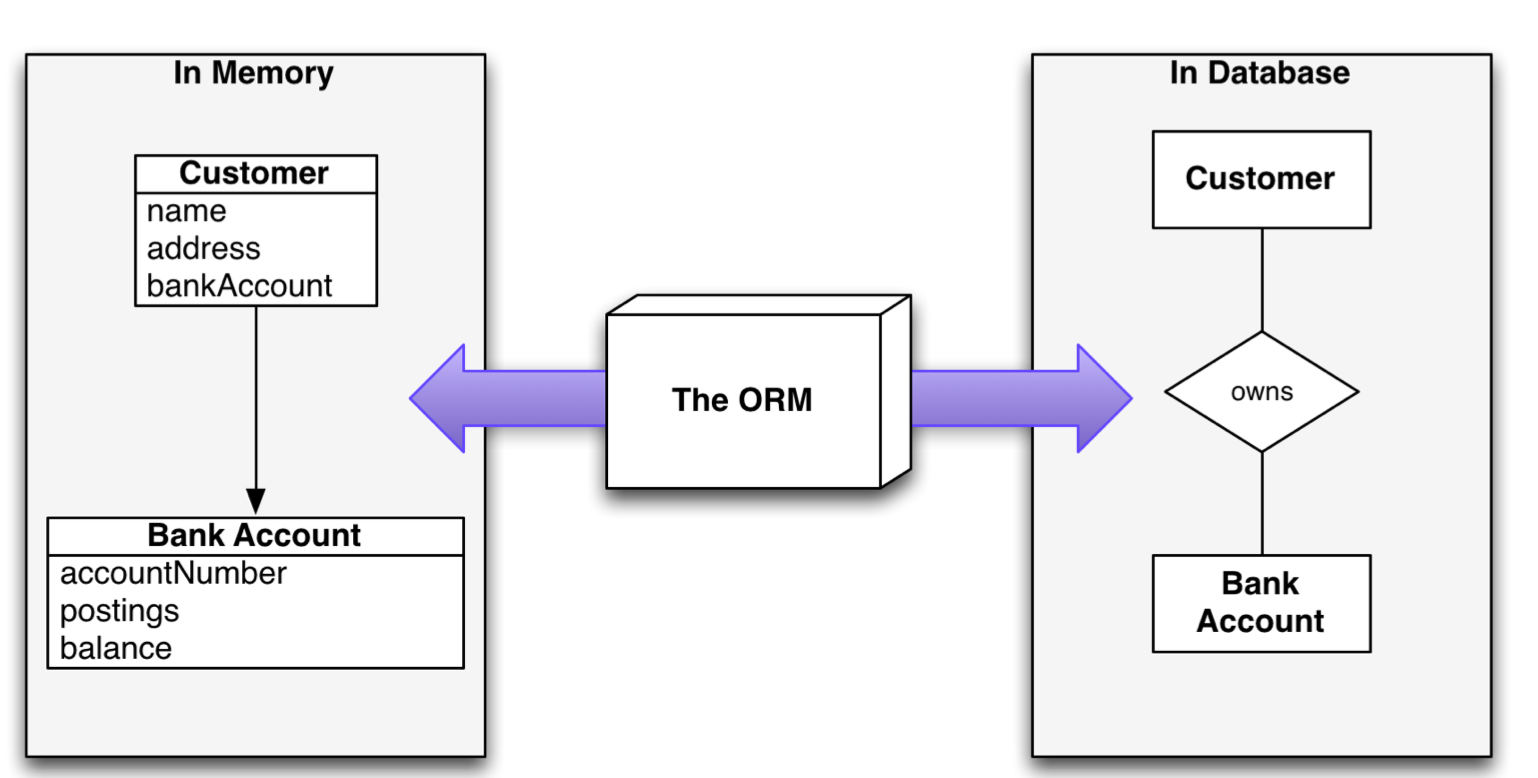
2. ORM介绍
对象和关系数据是业务实体的两种表现形式,业务实体在内存中表现为对象,在数据库中表现为关系数据;
内存中的对象之间存在关联和继承关系,在数据库中关系数据无法直接表达多关联和继承关系;
对象-关系映射系统一般以中间件形式存在,主要实现程序对象到关系数据库数据的映射;
在业务逻辑层和用户界面层中,都是面向对象的,当对象信息发生变化,需把对象的信息保存在关系数据库中。
3. 数据库切换/初始化
3.1 使用URL连接数据库
| 数据库引擎 | URL |
|---|---|
| MySQL | mysql://username:password@hostname/database |
| Postgres | postgresql://username:password@hostname/database |
| SQLite(Unix) | sqlite:////absolute/path/to/database |
| SQLite(Windows) | sqlite:///c:/absolute/path/to/database |
1、SQLALCHEMY_DATABASE_URI ——连接数据的数据库
如:SQLALCHEMY_DATABASE_URI = 'mysql://root:1234567890@localhost:3306/test';
2、SQLALCHEMY_ECHO
若设为True,SQLAlchemy记录所有发送到标准输出的语句,对跳是有帮助;
3、SQLALCHEMY_RECORD_QUERIES ——显式地禁用或启用查询记录
查询记录在调试或测试模式下自动启用;
4、SQLALCHEMY_NATIVE_UNICODE ——显式地禁用原生的unicode
5、SQLALCHEMY_TRACK_MODIFICATIONS
若设为True,SQLAlchemy将追踪对象的修改和发送信号;默认是None;
例子 :首先配置模块导出模块,导入SQLAlchemy扩展,再创建一个Flask应用,接着加载配置,然后创建SQLAlchemy对象,并将Flask应用作为参数传递
1 #__init__.py 2 3 from flask import Flask 4 from flask_sqlalchemy import SQLAlchemy 5 6 app = Flask(__name__) 7 app.config.from_pyfile('app.conf') 8 9 db = SQLAlchemy(app)
1 #app.conf 2 3 SQLALCHEMY_DATABASE_URI = 'mysql://root:1234567890@localhost:3306/test' 4 SQLALCHEMY_TRACK_MODIFICATIONS = True 5 SQLALCHEMY_ECHO = False 6 SQLALCHEMY_NATIVE_UNICODE = True 7 SQLALCHEMY_RECORD_QUERIES = False
3.3数据模型
1. 程序中有很多类,数据库中有很多表,SQLAlchemy将类与表结合;
2. db.Model指定所在类与数据库相关联,所有模型的基类是db.Model,存储在必须创建的SQLAlchemy实例;
3. 所有模型的定义都要继承db.Model类!
4. 用Column定义一列,列名是赋值给那个变量的名称;
5. 列的类型是Column的第一个参数,可直接提供,常见类型如下:
| 类型名 | Python类型 | 说 明 |
|---|---|---|
| Integer | int | 普通整数,一般是 32 位 |
| SmallInteger | int | 取值范围小的整数,一般是 16 位 |
| BigInteger | int 或 long | 不限制精度的整数 |
| Float | float | 浮点数 |
| Numeric | decimal.Decimal | 定点数 |
| String | str | 变长字符串 |
| Text | str | 变长字符串,对较长或不限长度的字符串做了优化 |
| Unicode | unicode | 变长 Unicode 字符串 |
| UnicodeText | unicode | 变长 Unicode 字符串,对较长或不限长度的字符串做了优化 |
| Boolean | bool | 布尔值 |
| Date | datetime.date | 日期 |
| Time | datetime.time | 时间 |
| DateTime | datetime.datetime | 日期和时间 |
| Interval | datetime.timedelta | 时间间隔 |
| Enum | str | 一组字符串 |
| PickleType | 任何 Python 对象 | 自动使用 Pickle 序列化 |
| LargeBinary | str | 二进制文件 |
最常使用的SQLAlchemy列选项
| 选项名 | 说 明 |
|---|---|
| primary_key | 如果设为 True ,这列就是表的主键 |
| unique | 如果设为 True ,这列不允许出现重复的值 |
| index | 如果设为 True ,为这列创建索引,提升查询效率 |
| nullable | 如果设为 True ,这列允许使用空值;如果设为 False ,这列不允许使用空值 |
| default | 为这列定义默认值 |
关系表达
关系型数据库使用关系把不同表中的行联系起来。
1. 一对多关系
"一"的一方关系使用db.relationship()方法表示,第一个参数是多的一方的类名的字符串形式,其他参数见下:
| 选项名 | 说 明 |
|---|---|
| backref | 在为建立双向连接,设置反向引用,在多的一方所在类上声明新的属性; |
| primaryjoin | 明确指定两个模型之间使用的联结条件。只在模棱两可的关系中需要指定 |
| lazy | 指定如何加载相关记录。可选值有 select (首次访问时按需加载)、 immediate (源对象加载后就加载)、 joined (加载记录,但使用联结)、 subquery (立即加载,但使用子查询),noload (永不加载)和 dynamic (不加载记录,但提供加载记录的查询) |
| uselist | 如果设为 Fales ,不使用列表,而使用标量值 |
| order_by | 指定关系中记录的排序方式 |
| secondary | 指定 多对多 关系中关系表的名字 |
| secondaryjoin | SQLAlchemy 无法自行决定时,指定多对多关系中的二级联结条件 |
如一个User拥有多个Image,定义一对多关系;
因为设置backref参数,Image表(多)可获取User表(一)的属性,如
1 #models.py 2 3 class User(db.Model): 4 id = db.Column(db.Integer, primary_key=True, autoincrement=True) 5 username = db.Column(db.String(80), unique=True) 6 password = db.Column(db.String(32)) 7 head_url = db.Column(db.String(256)) 8 images = db.relationship('Image', backref = 'user', lazy = 'dynamic') 9 10 class Image(db.Model): 11 id = db.Column(db.Integer, primary_key = True, autoincrement = True) 12 url = db.Column(db.String(512)) 13 user_id = db.Column(db.Integer, db.ForeignKey('user.id')) 14 created_date = db.Column(db.DateTime)
2. 一对一关系
一对一关系可以用前面介绍的一对多关系表示,但调用 db.relationship() 时要把 uselist 设为 False ,把“多”变成“一”
3. 多对多关系
如博客中tag和日志的关系;
定义用于关系的辅助表,辅助表不建议使用模型,采用实际的表;
1 tags = db.Table('tags', 2 db.Column('tag_id', db.Integer, db.ForeignKey('tag.id')), 3 db.Column('page_id', db.Integer, db.ForeignKey('page.id')) 4 ) 5 6 class Page(db.Model): 7 id = db.Column(db.Integer, primary_key=True) 8 tags = db.relationship('Tag', secondary=tags, backref=db.backref('pages', lazy='dynamic')) 9 10 class Tag(db.Model): 11 id = db.Column(db.Integer, primary_key=True)
4. 数据库操作
- 创建表
1 python manage.py shell 2 >>> from manage.py import db 3 >>> db.create_all()
- 删除表
1 db.drop_all()
- 插入行
向数据库插入数据分三步:
1 创建对象
2 以参数形式传递,添加到会话
3 提交会话(如果不提交,数据库不会改动)
注意:这里的会话是SQLAlchemy会话;
1 user = User('Alice', '123456', 'http://images.***.com/head/1223/m.png')
2 db.session.add(user)
3 db.session.commit()
- 删除行
从数据库中删除数据分三步:
1 查询数据
2 从会话中删除
3 提交会话
1 user = User.query.get(1) 2 user.delete() # 删除方法1 3 db.session.delete(user) # 删除方法2 4 db.session.commit()
- 更新
更新数据库中的数据分三步:
1 查询数据
2 更新数据
3 提交会话
1 user = User.query.filter_by(id > 5) 2 user.username = '[newname]' # 更新方法1 3 user.update({'username' : '[newname]'}) # 更新方法2 4 db.session.commit()
- 查询
1 查询全部。Role.query.all()
2 条件查询(使用过滤器)。User.query.filter_by(role=user_role).all()
常用过滤器
| 过滤器 | 说 明 |
|---|---|
| filter() | 把过滤器添加到原查询上,返回一个新查询 |
| filter_by() | 把等值过滤器添加到原查询上,返回一个新查询 |
| limit() | 使用指定的值限制原查询返回的结果数量,返回一个新查询 |
| offset() | 偏移原查询返回的结果,返回一个新查询 |
| order_by() | 根据指定条件对原查询结果进行排序,返回一个新查询 |
| group_by() | 根据指定条件对原查询结果进行分组,返回一个新查询 |
| 方 法 | 说 明 |
|---|---|
| all() | 以列表形式返回查询的所有结果 |
| first() | 返回查询的第一个结果,如果没有结果,则返回 None |
| first_or_404() | 返回查询的第一个结果,如果没有结果,则终止请求,返回 404 错误响应 |
| get() | 返回指定主键对应的行,如果没有对应的行,则返回 None |
| get_or_404() | 返回指定主键对应的行,如果没找到指定的主键,则终止请求,返回 404 错误响应 |
| count() | 返回查询结果的数量 |
| paginate() | 返回一个 Paginate 对象,它包含指定范围内的结果 |
- 查询分类及例子
1 简单查询
query.all():返回list类型的所有数据
2 带条件查询
query.filter_by(name='twc').all()
query.filter_by(id=5).first()
query.filter(User.username.endswith('0')).all()
3 排序查询
query.order_by(User.id.desc()).offset(1).limit(2).all()
4 分组查询
query.get(ident):基于主键的id属性,返回指定元组
5 组合查询
query.filter(and_(User.id > 57, User.id < 59)).all()
query.filter(or_(User.id == 57, User.id == 59)).all()
6 分页查询
paginate(page=None, per_page=None, error_out=True)返回pagination对象,第一个参数表示当前页,第二个参数表示每页显示的数量,error_out=True表示若制定也没有内容则报404错误,否则返回空列表;
pagination对象常用方法如下:
items:返回当前页的内容列表
has_next:是否还有下一页
has_prev:是否还有上一页
next(error_out=False):返回下一页的Pagination对象
prev(error_out=False):返回上一页的Pagination对象
page:当前页的页码(从1开始)
pages:总页数
per_page:每页显示的数量
prev_num:上一页页码数
next_num:下一页页码数
query:返回创建该Pagination对象的查询对象
total:查询返回的记录总数