1.中软国际华南区技术总监曾老师还会来上两次课,同学们希望曾老师讲些什么内容?(认真想一想回答)
- 处理某个沟通或技术性难题时是如何应对与解决的?
2.中文分词
(1)下载一中文长篇小说,并转换成UTF-8编码。


1 import jieba 2 novel = open('百年孤独.txt','w',encoding='utf-8')#新“写”一个txt 3 novel.write(''' 4 5 6 百年孤独 7 8 作者:马尔克斯 9 10 第一章 11 12 (文本略) 13 14 ''') 15 novel.close() 16 17 print(novel)
#使用print()检查确认文本已保存至参数中。

(2)使用jieba库,进行中文词频统计,输出TOP20的词及出现次数。
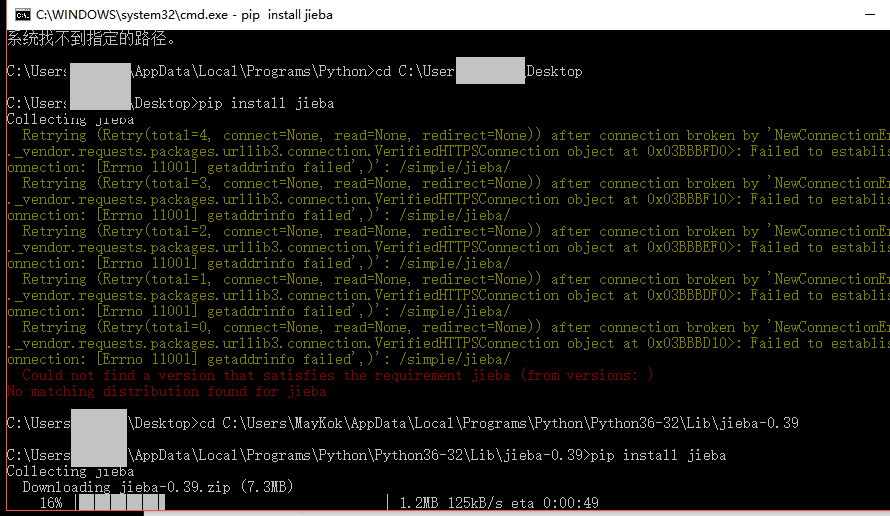
jieba库安装:
1 import jieba 2 novel = open('百年孤独.txt','w',encoding='utf-8')#新“写”一个txt 3 novel.write(''' 4 5 6 百年孤独 7 8 (文本略) 9 10 ''') 11 novel.close() 12 13 print(novel) 14 15 txt = open('百年孤独.txt','r',encoding='utf-8').read() 16 17 words =list(jieba.cut(txt))#jieba库帮忙分词,且已去除标点符号 18 exp = {',',' ','.','。','”','“',':','…',' ','?','、','·'} 19 key=set(words)-exp 20 21 dic = {}#空字典 22 23 for i in key: 24 dic[i]=words.count(i) 25 26 items = list(dic.items())#划分为元组 27 28 items.sort(key=lambda x:x[1],reverse=True)#排序 29 30 for i in range(20): 31 print(items[i]) 32 33 novel.close()

(3)排除一些无意义词、合并同一词。
1 import jieba 2 3 4 txt = open('百年孤独.txt','r',encoding='utf-8').read() 5 6 words =list(jieba.cut(txt))#jieba库帮忙分词,且已去除标点符号 7 exp = {',',' ','.','。','”','“',':','…',' ','?','、','·'} 8 key=set(words)-exp 9 10 dic = {}#空字典 11 12 for i in key: 13 if len(i)>1: 14 dic[i]=words.count(i) 15 else: 16 continue 17 18 items = list(dic.items())#划分为元组 19 20 items.sort(key=lambda x:x[1],reverse=True)#排序 21 22 for i in range(20): 23 print(items[i]) 24 25 novel.close()

**使用wordcloud库绘制一个词云。
