模块
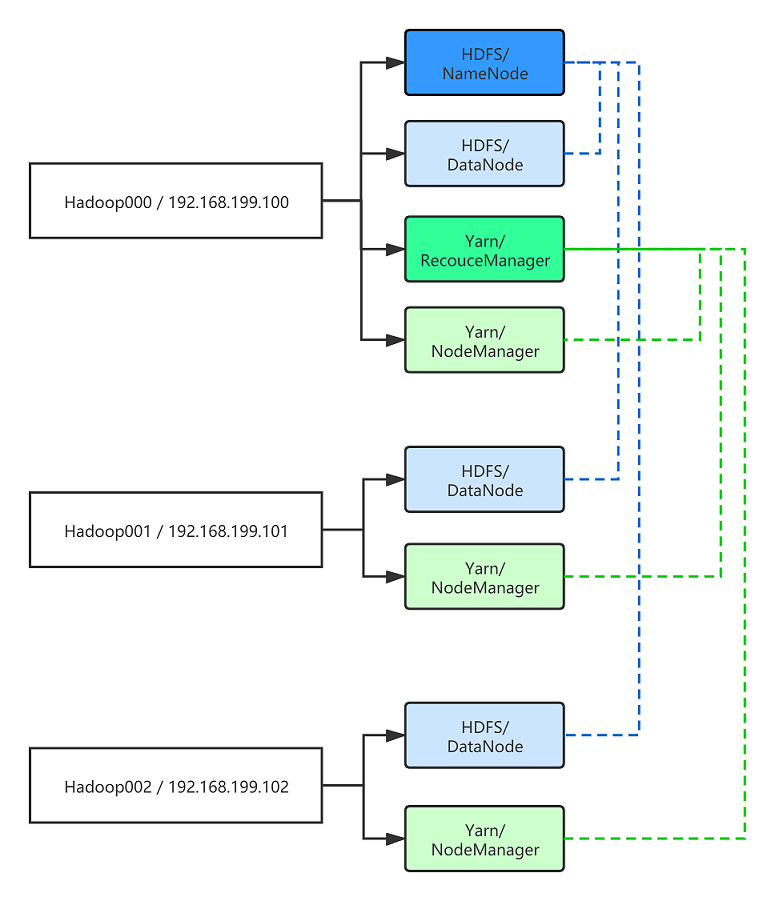
以三台机器为例,分别为 hadoop000 ,hadoop001,hadoop002 。在这些机器上我需要部署哪些模块呢?
- HDFS: NameNode,DataNode
- YARN: ResourceManager,NodeManager
如下图所示:
修改 hostname 与 hosts
以机器1为例,其它机器类似。
修改hostname
vim /etc/hostname
hadoop000
修改ip映射
vim /etc/hosts
192.168.199.100 localhost
192.168.199.100 hadoop000
192.168.199.101 hadoop001
192.168.199.102 hadoop002
注:不能简单地只copy-paste到其它机器上,需要适当修改。
配置 ssh 登录
首先,每台机器上需要已安装 ssh 。
然后,到每台机器上,分别生成一遍 rsa key pair :ssh-keygen -t rsa 。
最后,将 public key 拷贝到其它机器上,以机器1为例,其它机器类似。
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop000
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop001
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop002
(注:SSH免密码登录详解,可参考这一篇 -> https://www.cnblogs.com/maxstack/p/13609285.html)
安装 JDK
首先,在机器1上安装并配置JDK。
- 在 hadoop000 上部署 jdk ,download and unzip
- 将 jdk bin 配置到系统环境变量 bash_profile ,config JAVA_HOME and PATH
然后,将机器1的东西拷贝到其它机器上。(注意拷贝的目录需要保持一致)
scp -r jdk1.8.0_91 hadoop@hadoop001:~/app/java/
scp -r jdk1.8.0_91 hadoop@hadoop002:~/app/java/
scp ~/.bash_profile hadoop@hadoop001:~/
scp ~/.bash_profile hadoop@hadoop002:~/
部署 Hadoop
和 JDK 类似,先在机器1上配置好,然后拷贝到其它机器上。
1. download hadooop and unzip
2. configuration change
2.1 hadoop-env.sh
配置 JAVA_HOME
JAVA_HOME=XXX
2.2 core-site.xml
配置主节点
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop000:8020</value>
</property>
2.3 hdfs-site.xml
配置存储目录
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/app/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/app/tmp/dfs/data</value>
</property>
2.4 yarn-site.xml
配置 yarn
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop000</value>
</property>
2.5 mapred-site.xml
配置 mapreduce 框架
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
2.6 slaves
配置从节点
hadoop000
hadoop001
hadoop002
3. copy to other machines
scp -r hadoop-2.6.0-cdh5.15.1 hadoop@hadoop001:~/app/hadoop/
scp -r hadoop-2.6.0-cdh5.15.1 hadoop@hadoop002:~/app/hadoop/
scp ~/.bash_profile hadoop@hadoop001:~/
scp ~/.bash_profile hadoop@hadoop002:~/
4. format namenode
到每台机器上,格式化 NN
hadoop namenode -format
启动 Cluster
登录一台机器,比如 hadoop000 ,启动HDFS:
./start-dfs.sh
同样地,启动 yarn:
./start-yarn.sh
最后,到每台机器上使用jps,或者使用 UI ,观察模块启动情况。