在实际工作中,我们可能会遇到几十个常用table,每个表有几十个column,很难一下子把它们都记住。
每次使用desc TableA手动查询,效率比较低。特别是碰到DB slowness,就只能干等着,很急。
所以需要做一个可以便捷更新的数据库文档。
最终,我选用了开源的screw来实现。Github的地址在这里:https://github.com/pingfangushi/screw/tree/master
功能
支持多种数据库(主要是传统的关系型数据库)
- Oracle
- MySQL
- SqlServer
- PostgreSQL
支持多种生成文档的格式
- html
- word
- markdown
最终生成的文件是这样的
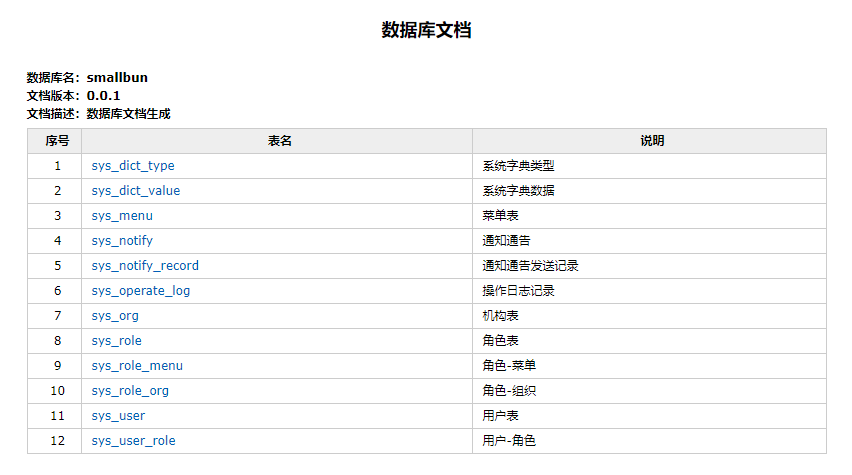
所有表名汇总
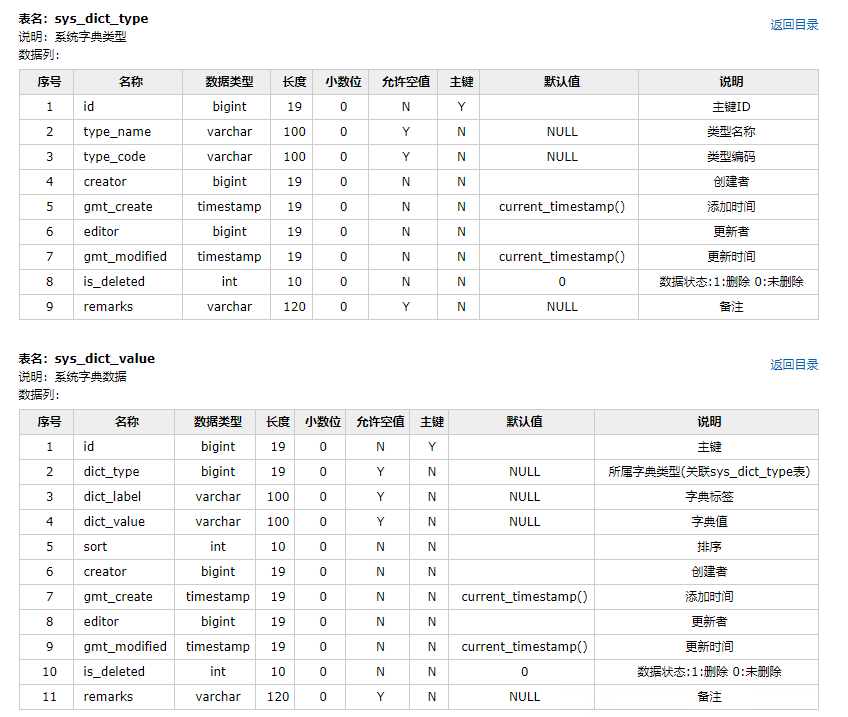
每个表的信息
原理
个人分析,screw的实现应该是这样的:
- 首先,通过一个Connector连接到DB,这里用的是
HikariCP,因为轻量,且速度快。(https://github.com/brettwooldridge/HikariCP) - 然后,通过一系列的Query得到Table Schema。
举例Oracle的Query如下:
- get all schema
SELECT
USERNAME AS SCHEMA_NAME
FROM SYS.ALL_USERS
ORDER BY USERNAME;
- get all table_name under the schema
SELECT
OWNER,
TABLE_NAME
FROM SYS.ALL_TABLES
WHERE OWNER = 'YOUR_SCHEMA';
- get the table_schema of the table, this is equivalent to using
desc
SELECT
COLUMN_NAME "Name",
NULLABLE "Null?",
CONCAT(CONCAT(CONCAT(DATA_TYPE,'('),DATA_LENGTH),')') "Type"
FROM USER_TAB_COLUMNS
WHERE TABLE_NAME='YOUR_TABLE';
实现
第一步,引入依赖,其中,screw和HikariCP是必须的,driver根据自己的数据库进行选择。
<!-- screw -->
<dependency>
<groupId>cn.smallbun.screw</groupId>
<artifactId>screw-core</artifactId>
<version>1.0.4</version>
</dependency>
<!-- HikariCP -->
<dependency>
<groupId>com.zaxxer</groupId>
<artifactId>HikariCP</artifactId>
<version>3.4.5</version>
</dependency>
<!-- driver -->
<dependency>
<groupId>com.oracle.ojdbc</groupId>
<artifactId>ojdbc8</artifactId>
<version>19.3.0.0</version>
</dependency>
<dependency>
<groupId>cn.easyproject</groupId>
<artifactId>orai18n</artifactId>
<version>12.1.0.2.0</version>
</dependency>
第二步,编写代码实现。
这里需要配置三个地方:
- 数据库(从哪里读取数据)
- 输出文件(读取之后存到什么地方)
- 读取哪些数据表(读取哪些数据)
import cn.smallbun.screw.core.Configuration;
import cn.smallbun.screw.core.engine.EngineConfig;
import cn.smallbun.screw.core.engine.EngineFileType;
import cn.smallbun.screw.core.engine.EngineTemplateType;
import cn.smallbun.screw.core.execute.DocumentationExecute;
import cn.smallbun.screw.core.process.ProcessConfig;
import com.zaxxer.hikari.HikariDataSource;
import java.util.ArrayList;
public class DbSchemaHelper {
public static void main(String args[]) {
new DbSchemaHelper().documentGeneration();
}
void documentGeneration() {
//配置 - 数据源
HikariDataSource ds = new HikariDataSource();
ds.setJdbcUrl("jdbc:oracle:thin:@//somelink:port/dbname");
ds.setUsername("user");
ds.setPassword("password");
ds.setDriverClassName("oracle.jdbc.driver.OracleDriver");
ds.setSchema("schema_name");
//配置 - 输出文件
String fileOutputDir = "C:\my_test";
EngineConfig engineConfig = EngineConfig.builder()
//生成文件路径
.fileOutputDir(fileOutputDir)
//打开目录
.openOutputDir(true)
//文件类型
.fileType(EngineFileType.HTML)
//生成模板实现
.produceType(EngineTemplateType.freemarker)
//自定义文件名称
.fileName("test_file")
.build();
//配置 - 读取哪些数据表
ArrayList<String> ignoreTableName = new ArrayList<>();
ignoreTableName.add("test_user");
ignoreTableName.add("test_group");
ArrayList<String> ignorePrefix = new ArrayList<>();
ignorePrefix.add("test_");
ArrayList<String> ignoreSuffix = new ArrayList<>();
ignoreSuffix.add("_test");
ArrayList<String> tablePrefix = new ArrayList<>();
tablePrefix.add("Acc_");
ProcessConfig processConfig = ProcessConfig.builder()
//指定生成逻辑、当存在指定表、指定表前缀、指定表后缀时,将生成指定表,其余表不生成、并跳过忽略表配置
//根据名称指定表生成
.designatedTableName(new ArrayList<>())
//根据表前缀生成
.designatedTablePrefix(tablePrefix)
//根据表后缀生成
.designatedTableSuffix(new ArrayList<>())
//忽略表名
//.ignoreTableName(ignoreTableName)
//忽略表前缀
//.ignoreTablePrefix(ignorePrefix)
//忽略表后缀
//.ignoreTableSuffix(ignoreSuffix)
.build();
Configuration config = Configuration.builder()
//版本
.version("1.0.0")
//描述
.description("DB Schema Doc")
//数据源
.dataSource(ds)
//生成配置
.engineConfig(engineConfig)
//生成配置
.produceConfig(processConfig)
.build();
//执行生成
System.out.println("start");
new DocumentationExecute(config).execute();
System.out.println("end");
}
}
除此之外,也可以使用SpringBoot,或者Maven Plugin,所做的事大概是把一部分Java代码放到了XML里面,但是万变不离其宗,保证上面的三个点都配置好即可。
常见错误
java.lang.AbstractMethodError: oracle.jdbc.driver.T4CConnection.getSchema()Ljava/lang/String;
这是因为oracle驱动版本过低造成的,比如ojdbc6,升级下即可。