参考资料
https://blog.csdn.net/u011127019/article/details/99629697
(1)C# 的所有源代码文件,默认编码为 UTF-8,注意,是源代码文件,而不是 C# 中的 string。
(2)C# 中的所有 string,默认编码均为 Unicode (UTF-16)。
(3)C# 产生的 ASP.NET 源代码,如 ASPX/CS,在浏览器响应回去客户端之后,编码默认为 UTF-8。可以通过 ContentType 请求头信息更改默认编码。比如:ContentType: application/json, charset=utf-8。
(4)C# 中可以用 System.Text.Encoding.ASCII 提供的相关方法,把默认 Unicode 编码的字符串转换为 ASCII。详细请参考 GetString,GetBytes,GetByteCount 等方法。
测试过程
代码
1 public static string TestCoder() 2 { 3 string msg = "测试ceshi";//7个字符 4 StringBuilder sbContent = new StringBuilder(); 5 6 Dictionary<int, byte[]> pairs = new Dictionary<int, byte[]>(); 7 8 byte[] b1 = Encoding.ASCII.GetBytes(msg); 9 byte[] b2 = Encoding.Default.GetBytes(msg); 10 byte[] b3 = Encoding.UTF7.GetBytes(msg); 11 byte[] b4 = Encoding.UTF8.GetBytes(msg); 12 byte[] b5 = Encoding.Unicode.GetBytes(msg); 13 byte[] b6 = Encoding.BigEndianUnicode.GetBytes(msg); 14 byte[] b7 = Encoding.UTF32.GetBytes(msg); 15 16 pairs.Add(pairs.Count, b1); 17 pairs.Add(pairs.Count, b2); 18 pairs.Add(pairs.Count, b3); 19 pairs.Add(pairs.Count, b4); 20 pairs.Add(pairs.Count, b5); 21 pairs.Add(pairs.Count, b6); 22 pairs.Add(pairs.Count, b7); 23 24 foreach (KeyValuePair<int, byte[]> item in pairs) 25 { 26 sbContent.AppendLine(""); 27 string s1 = Encoding.ASCII.GetString(item.Value); 28 string s2 = Encoding.Default.GetString(item.Value); 29 string s3 = Encoding.UTF7.GetString(item.Value); 30 string s4 = Encoding.UTF8.GetString(item.Value); 31 string s5 = Encoding.Unicode.GetString(item.Value); 32 string s6 = Encoding.BigEndianUnicode.GetString(item.Value); 33 string s7 = Encoding.UTF32.GetString(item.Value); 34 35 int coder = item.Key; 36 string codeName = ""; 37 switch (coder) 38 { 39 case 0: codeName = "ASCII"; break; 40 case 1: codeName = "Default"; break; 41 case 2: codeName = "UTF7"; break; 42 case 3: codeName = "UTF8"; break; 43 case 4: codeName = "Unicode"; break; 44 case 5: codeName = "BigEndianUnicode"; break; 45 case 6: codeName = "UTF32"; break; 46 default: 47 break; 48 } 49 sbContent.AppendLine($"{coder}、编码方式:{codeName}".Replace("�", "")); 50 sbContent.AppendLine($"{coder}.1、解码结果-ASCII:{s1}".Replace("�", "")); 51 sbContent.AppendLine($"{coder}.2、解码结果-Default:{s2}".Replace("�", "")); 52 sbContent.AppendLine($"{coder}.3、解码结果-UTF7:{s3}".Replace("�", "")); 53 sbContent.AppendLine($"{coder}.4、解码结果-UTF8:{s4}".Replace("�", "")); 54 sbContent.AppendLine($"{coder}.5、解码结果-Unicode:{s5}".Replace("�", "")); 55 sbContent.AppendLine($"{coder}.6、解码结果-BigEndianUnicode:{s6}".Replace("�", "")); 56 sbContent.AppendLine($"{coder}.7、解码结果-UTF32:{s7}".Replace("�", "")); 57 } 58 59 return sbContent.ToString(); 60 }
结果
由于解码后会有�,而C#遇到�会终止字符串,所以下面的文字结果可能不准确,直接返回结果参见截图
0.ASCII
0.1、解码结果-ASCII:??ceshi
0.2、解码结果-Default:??ceshi
0.3、解码结果-UTF7:??ceshi
0.4、解码结果-UTF8:??ceshi
0.5、解码结果-Unicode:㼿散桳�
0.6、解码结果-BigEndianUnicode:㼿捥獨�
0.7、解码结果-UTF32:��
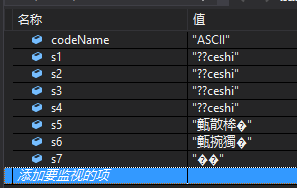
1.Default
1.1、解码结果-ASCII:????ceshi
1.2、解码结果-Default:测试ceshi
1.3、解码结果-UTF7:²âÊÔceshi
1.4、解码结果-UTF8:����ceshi
1.5、解码结果-Unicode:�퓊散桳�
1.6、解码结果-BigEndianUnicode:닢쫔捥獨�
1.7、解码结果-UTF32:���
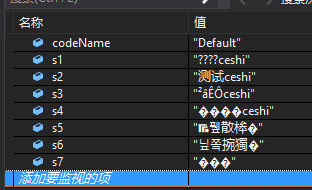
2.UTF7
2.1、解码结果-ASCII:+bUuL1Q-ceshi
2.2、解码结果-Default:+bUuL1Q-ceshi
2.3、解码结果-UTF7:测试ceshi
2.4、解码结果-UTF8:+bUuL1Q-ceshi
2.5、解码结果-Unicode:戫畕ㅌⵑ散桳�
2.6、解码结果-BigEndianUnicode:⭢啵䰱儭捥獨�
2.7、解码结果-UTF32:����
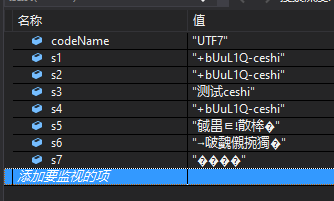
3.UTF8
3.1、解码结果-ASCII:??????ceshi
3.2、解码结果-Default:娴嬭瘯ceshi
3.3、解码结果-UTF7:æµè¯ceshi
3.4、解码结果-UTF8:测试ceshi
3.5、解码结果-Unicode:뗦閯散桳�
3.6、解码结果-BigEndianUnicode:�诨꾕捥獨�
3.7、解码结果-UTF32:���
4.Unicode
4.1、解码结果-ASCII:Km??ceshi
4.2、解码结果-Default:Km諎ceshi
4.3、解码结果-UTF7:KmÕceshi
4.4、解码结果-UTF8:KmՋceshi
4.5、解码结果-Unicode:测试ceshi
4.6、解码结果-BigEndianUnicode:䭭햋挀攀猀栀椀
4.7、解码结果-UTF32:����

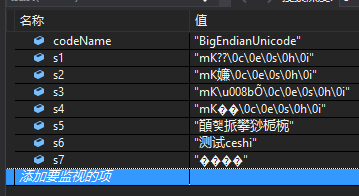
5.BigEndianUnicode
5.1、解码结果-ASCII:mK??ceshi
5.2、解码结果-Default:mK嬚ceshi
5.3、解码结果-UTF7:mKÕceshi
5.4、解码结果-UTF8:mK��ceshi
5.5、解码结果-Unicode:䭭햋挀攀猀栀椀
5.6、解码结果-BigEndianUnicode:测试ceshi
5.7、解码结果-UTF32:����
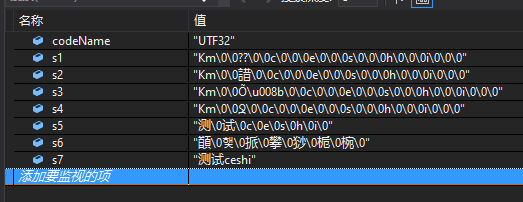
6.UTF32
6.1、解码结果-ASCII:Km??ceshi
6.2、解码结果-Default:Km諎ceshi
6.3、解码结果-UTF7:KmÕceshi
6.4、解码结果-UTF8:KmՋceshi
6.5、解码结果-Unicode:测试ceshi
6.6、解码结果-BigEndianUnicode:䭭햋挀攀猀栀椀
6.7、解码结果-UTF32:测试ceshi
总结
7种编码方式,
只有ASCII无法编码后正确还原原字符串,因为ASCII本身就没有编入汉字
其他6种都可以正确还原原字符串