Clustering
K-means:
基本思想是先随机选择要分类数目的点,然后找出距离这些点最近的training data 着色,距离哪个点近就算哪种类型,再对每种分类算出平均值,把中心点移动到平均值处,重复着色算平均值,直到分类成功.
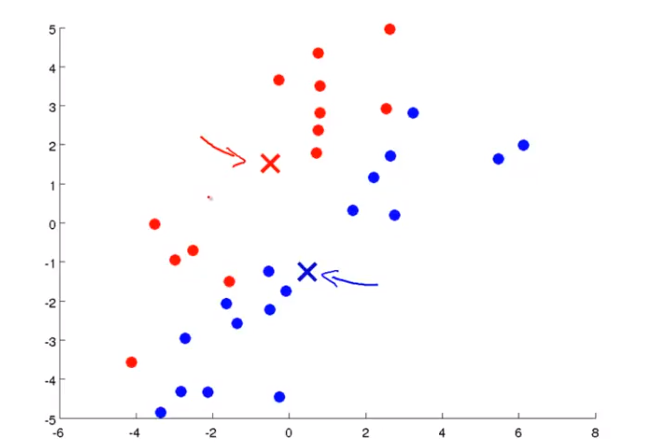


为了防止k-means 算法得到的是local optima, 可以多次运行k-means, 然后选取得到J最小值的那次初始化方法.

One way to choose K is elbow method

Dimentionality Reduction
Dimentionality Reduction: 1. data compression to save space of memory and speed up compute. 2. 还有一个作用是可以用降维来visualize data.

降维最常用的算法PCA (Principal Component Analysis)


the 1st step of PCA algo is data preprocessing

PCA algo in matlab:
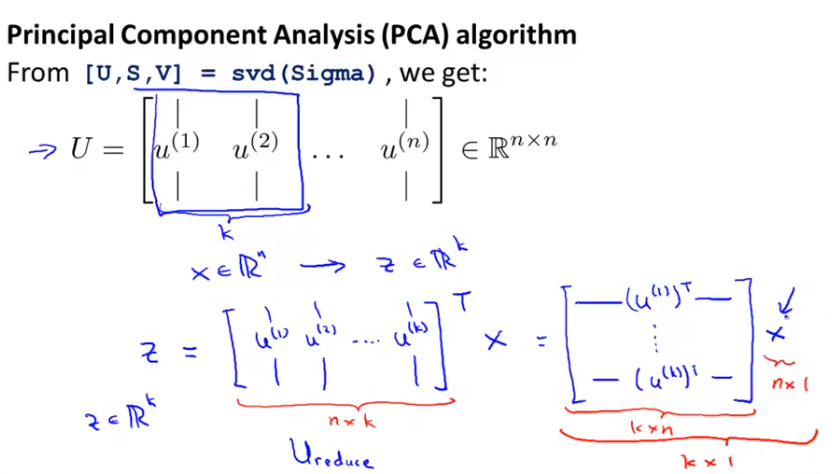

How to de-compress back from 100-dimentional to 1000-dimentional

How to choose the parameter K


Advice for using PCA. PCA is often used for data compresion and visualization. it is bad to use it to prevent overfitting.