目标:
我们内部系统里记录的酒店名字是由很多人输入的,每个人输入的可能不完全一样,比如,‘成都凯宾斯基大酒店’, ‘凯宾斯基酒店’, ‘凯宾斯基’, 我们的初步想法是能不能把大量的记录归类,把很多相似的名字归成一类,然后自动给出一个建议的名字
向量化和建模:
大概的想法是,先找出一个相似性算法,然后在调用一种分类算法。相似性算法很多是基于vector的,怎么把中文转化成vector? 这个文章介绍了怎么处理中文 (sklearn: TfidfVectorizer 中文处理及一些使用参数)
聚类:
聚类的时候我并不想像 K-means那样指定一个K值,我需要的是自动根据输入数据的集中程度来决定分多少类, 这个文章(机器学习总结(十):常用聚类算法(Kmeans、密度聚类、层次聚类)及常见问题)里介绍可以用 DBSCAN 算法. 后来想我这个case其实根本不需要什么DBSCAN, 只要设置一个threashold就可以了,我设置的0.5, 就是凡是相似度 >0.5的都认为相似度很高了,也就是同一个酒店
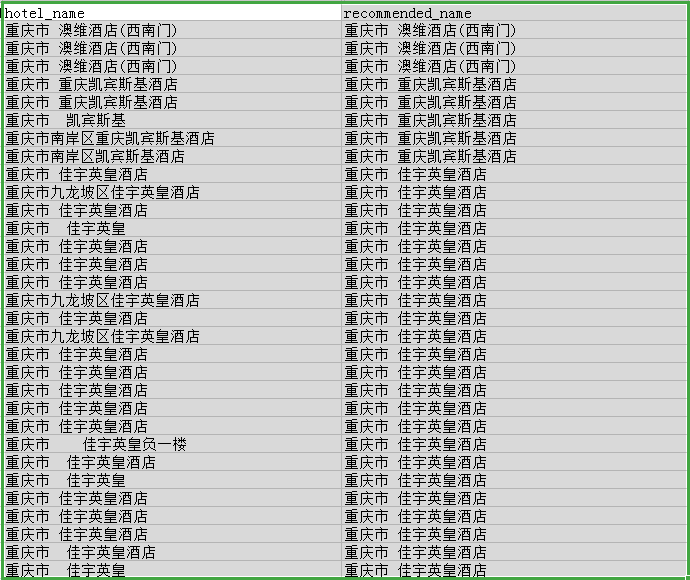
最终出来的效果如下:
没用什么高级的技术,主要用的是参考资料里sklearn: TfidfVectorizer 提供的API,来得到酒店名字之间的相似矩阵,然后取矩阵里面相似度高的归为同一个酒店,我选的相似度 >0.8 这个threshold. 最后,从选出来的里面取最常见的那个酒店名字作为推荐使用的名字.
Ref:
- Quick review on Text Clustering and Text Similarity Approaches
- 通俗理解word2vec
- sklearn: TfidfVectorizer 中文处理及一些使用参数
- https://www.coursera.org/lecture/text-mining/4-2-text-clustering-generative-probabilistic-models-part-1-gJTFA, 这里讲了基于 Generative Probabilistic Model 和 Similarity 两种方法的 Text Clustering.