1.虚拟环境的搭建
由于在每个项目所使用的解析器,当你运行别人的项目或者和别人合作开发一个项目,各个模块的版本存在差异,创建虚拟环境可以让你运行的环境与别人的保持一致,
虚拟环境的搭建在linue系统和window系统存在细微的差别
linux系统
创建虚拟环境: mkvirtualenv 虚拟环境名
指定解析器器的版本: mkvirtualenv luffy -p python3(这个是指定python解析器使用python3,可以根据需求写自己项目版本)
查看所有虚拟环境:workon
使用虚拟环境:workon 虚拟环境名称
推出虚拟环境: deactivate
删除虚拟环境: rmvirtualenv 虚拟环境名称(不能删除当前正在使用的虚拟环境,需要先退出再删除)
如果当前系统中没有mkvirtualenv命令,可以使用sudo apt-get install python-virtualenv和sudo easy_install virtualenvwrapper来安装
window系统
安装virtualenv:pip install virtualenv
创建虚拟环境: virtualenv 虚拟环境名
安装3.7版本python解释器: virtualenv -p F:Python3.7python37python.exe 虚拟环境名
使用虚拟环境:在创建虚拟环境目录下执行目录文件 ./虚拟环境/Scripts/activate.bat
退出虚拟环境:在创建虚拟环境目录下执行目录文件 ./虚拟环境/Scripts/deactivate.bat
2.项目中经常使用的模块
https://www.cnblogs.com/mark--ping/p/11527445.html
3.日志文件的配置
在项目中,由于需要人不能24小时去监控项目是否发生异常,所有可以通过配置文件添加日志文件配置来保存日志信息,
可以在配置文件中添加一下配置
# 日志配置 LOGGING = { 'version': 1, 'disable_existing_loggers': False, 'formatters': { 'verbose': { 'format': '%(levelname)s %(asctime)s %(module)s %(lineno)d %(message)s' }, 'simple': { 'format': '%(levelname)s %(module)s %(lineno)d %(message)s' }, }, 'filters': { 'require_debug_true': { '()': 'django.utils.log.RequireDebugTrue', }, }, 'handlers': { 'console': { 'level': 'DEBUG', 'filters': ['require_debug_true'], 'class': 'logging.StreamHandler', 'formatter': 'simple' }, 'file': { 'level': 'INFO', 'class': 'logging.handlers.RotatingFileHandler', # 日志位置,日志文件名,日志保存目录必须手动创建 'filename': os.path.join(os.path.dirname(BASE_DIR), "logs/luffy.log"), # 日志文件的最大值,这里我们设置300M 'maxBytes': 300 * 1024 * 1024, # 日志文件的数量,设置最大日志数量为10 'backupCount': 10, # 日志格式:详细格式 'formatter': 'verbose' }, }, # 日志对象 'loggers': { 'django': { 'handlers': ['console', 'file'], 'propagate': True, # 是否让日志信息继续冒泡给其他的日志处理系统 }, } }
此外,由于django框架不能识别一些数据库的错误,可以自定义一个异常处理方法,然后可以通过配置让系统认识异常从而记录下来
新建一个exceptions.py文件
from rest_framework.views import exception_handler from django.db import DatabaseError from rest_framework.response import Response from rest_framework import status import logging logger = logging.getLogger('django') def custom_exception_handler(exc, context): """ 自定义异常处理 :param exc: 异常类 :param context: 抛出异常的上下文 :return: Response响应对象 """ # 调用drf框架原生的异常处理方法 response = exception_handler(exc, context) if response is None: view = context['view'] if isinstance(exc, DatabaseError): # 数据库异常 logger.error('[%s] %s' % (view, exc)) response = Response({'message': '服务器内部错误'}, status=status.HTTP_507_INSUFFICIENT_STORAGE) return response
在配置文件中添加设置
REST_FRAMEWORK = { # 异常处理 'EXCEPTION_HANDLER': 'luffyapi.utils.exceptions.custom_exception_handler',#字典后面是自定义异常的路径 }
4.用户登陆表
虽然django内部已经有用户登陆的表,但是该表格不满足项目需求,需要自定义一些字段来满足不同的登陆方式,如微信登陆,手机登录等
我们可以自定义一个类,该类继承系统提供的登陆模型类AbstractUser
class User(AbstractUser): """用户模型类""" mobile = models.CharField(max_length=11, unique=True, verbose_name='手机号') class Meta: db_table = 'ly_users' verbose_name = '用户' verbose_name_plural = verbose_name
写好类后需要在配置文件
AUTH_USER_MODEL = 'users.User' #app名+模型类名,不用写models.py这个文件名,系统自动识别,所有模型类必须写在models.py文件中
中告诉系统登陆时使用自定义模型类而不是使用系统提供的
用户登陆时,默认是通过用户名和密码的匹配来认证登陆成功与否,但用手机号登陆时就会失败所有可以通过自定义类来写登陆逻辑
def get_user_by_account(account): """ 根据帐号获取user对象 :param account: 账号,可以是用户名,也可以是手机号 :return: User对象 或者 None """ try: if re.match('^1[3-9]d{9}$', account): # 帐号为手机号 user = User.objects.get(mobile=account) else: # 帐号为用户名 user = User.objects.get(username=account) except User.DoesNotExist: return None else: return user import re from .models import User from django.contrib.auth.backends import ModelBackend class UsernameMobileAuthBackend(ModelBackend): """ 自定义用户名或手机号认证 """ def authenticate(self, request, username=None, password=None, **kwargs): user = get_user_by_account(username) if user is not None and user.check_password(password): return user
通过配置文件来告诉系统
AUTHENTICATION_BACKENDS = [ 'user.utils.UsernameMobileAuthBackend', ]
5.外部接口的使用
6.媒体文件的上传
后端需要给前端发生图片,视频等媒体文件,需要创建一个目录来存在这些文件,并且把该文件的目录告诉django框架
在配置文件中添加
# 访问静态文件的url地址前缀 STATIC_URL = '/static/' # 设置django的静态文件目录 STATICFILES_DIRS = [ os.path.join(BASE_DIR,"static") ] # 项目中存储上传文件的根目录[暂时配置],注意,uploads目录需要手动创建否则上传文件时报错 MEDIA_ROOT=os.path.join(BASE_DIR,"uploads") # 访问上传文件的url地址前缀 MEDIA_URL ="/media/"
新增url
from django.urls import re_path from django.conf import settings from django.views.static import serve urlpatterns = [ ... re_path(r'media/(?P<path>.*)', serve, {"document_root": settings.MEDIA_ROOT}), ]
7.celery
使用celery可以异步处理一些耗时或者定时文体
安装:pip install -U celery
使用:新建一个任务目录
luffyapi/ ├── mycelery/ ├── config.py # 配置文件 ├── __init__.py ├── main.py # 主程序 └── sms/ # 一个目录可以放置多个任务,该目录下存放当前任务执行时需要的模块或依赖 └── tasks.py # 任务的文件,名称必须是这个!!!
在main.py中
# 主程序 from celery import Celery # 创建celery实例对象 app = Celery("luffy") # 通过app对象加载配置 app.config_from_object("mycelery.config") # 自动搜索并加载任务 # 参数必须必须是一个列表,里面的每一个任务都是任务的路径名称 # app.autodiscover_tasks(["任务1","任务2"]) app.autodiscover_tasks(["mycelery.sms","mycelery.cache"]) # 启动Celery的命令 # 强烈建议切换目录到项目的根目录下启动celery!! # celery -A mycelerymain worker --loglevel=info
在config.py中
# 任务队列的链接地址 broker_url = 'redis://127.0.0.1:6379/15' # 结果队列的链接地址 result_backend = 'redis://127.0.0.1:6379/14'
在tasks.py中写逻辑
# celery的任务必须写在tasks.py的文件中,别的文件名称不识别!!! from mycelery.main import app @app.task # name表示设置任务的名称,如果不填写,则默认使用函数名做为任务名 def send_sms(): print("发送短信!!!") @app.task # name表示设置任务的名称,如果不填写,则默认使用函数名做为任务名 def send_sms2(): print("发送短信任务2!!!")
官方文档http://docs.jinkan.org/docs/celery/getting-started/index.html
celery定时任务文档:http://docs.celeryproject.org/en/latest/userguide/periodic-tasks.html
8.分页数据
在rest_framework中已经有2个分页器的功能的类分别是PageNumberPagination和LimitOffsetPagination,可以自定义一个类继承模块提供的类就可以自定义分页器。
PageNumberPagination:这个类展示数据是从第m条数据开始,到m+1 ..... 一致到第n条数据,共展现n-m条数据
LimitOffsetPagination:这个类展示数据是从第m条数据开始,往后偏移n条数据,共展现m+n条数据
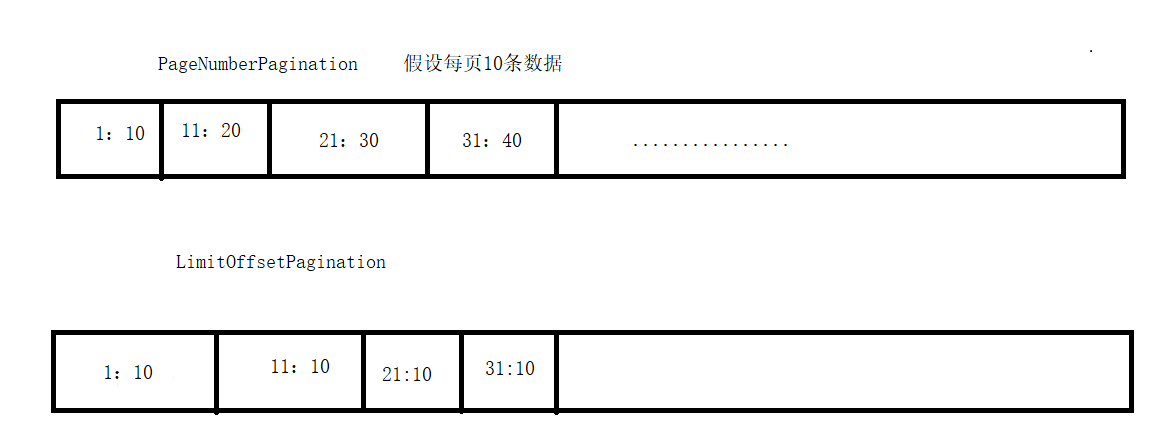
两个类区别如图所示,一个是通过首位数据的id来展示数据,一个是首id+偏移来展示数据
以PageNumberPagination为例:
from rest_framework.pagination import PageNumberPagination class CustomPageNumberPagination(PageNumberPagination): # page_query_param = "" # 地址上面代表页码的变量名,默认为page page_size = 5 # 每一页显示的数据量,没有设置页码,则不进行分页 # 允许客户端通过指定的参数名来设置每一页数据量的大小,默认是size page_size_query_param = "size" max_page_size = 20 # 限制每一页最大展示的数据量 # 按条件筛选[分类]展示课程信息 from django_filters.rest_framework import DjangoFilterBackend from rest_framework.filters import OrderingFilter from .paginations import CustomPageNumberPagination class CourseListAPIView(ListAPIView): """课程列表""" queryset = Course.objects.filter(is_show=True,is_delete=False).order_by("orders") serializer_class = CourseModelSerializer filter_backends = [DjangoFilterBackend, OrderingFilter] # 设置支持设置的筛选过滤字段 filter_fields = ('course_category', ) # 设置支持设置的排序字段 ordering_fields = ('id', 'students', 'price') # 指定分页器 pagination_class = CustomPageNumberPagination
9.数据库事物开启与回滚
在某些逻辑中可能会存在同时操作多个数据表,但不能100%保证执行成功,如果放任报错前的数据,会导致数据表出现很多无用数据,所以需要开启事务
开启事务的两种方法
添加装饰器
from django.db import transaction from rest_framework.views import APIView class OrderAPIView(APIView): @transaction.atomic # 开启事务,当方法执行完成以后,自动提交事务 def post(self,request): ....
使用with语句:
from django.db import transaction from rest_framework.views import APIView class OrderAPIView(APIView): def post(self,request): .... with transation.atomic(): # 设置事务回滚的标记点 sid = transation.savepoint() .... try: .... except: transation.savepoint_rallback(sid) #报错则回滚到标记点