一、数据库操作
创建数据库 create database name;
查看所有数据库 show databases;
删除数据库 drop database name;
进入数据库 use name;
二、表操作
1.查看表 show tables;
2.创建表 create table name(var1 int(4) [not null] [primary key],var2 char(10));
3.查看表结构
describe tablename;
缩写 desc tablename;
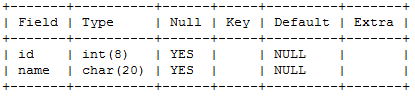
Field (列名),Type(字段类型),null(是否为空),key(主键),default(缺省/默认),extra(描述))
4.删除表 drop table name;
5.修改表结构
#设置自增长 (只有主键能设置)
alter table name change id id int(4) auto_increment;
#改变字段属性
alter table name change id id int(4);
删除主键
alter table name drop var primary key;
增加主键
alter table name change id id int(4) primary key;
增加字段
alter table name add class int(4) after id;
删除字段
alter table name drop name1,name2;
三、数据库增删改查
---增
insert into tablename(id,class,number) values(12,3,55); >>标准格式
insert into tablename values(12,3,99); >>值需要全部对应表字段可行
insert into tablename values(12,3,99),(22,23,12); >>值需要全部对应表字段可行
---查
select name from table;
select name from tablename order by name [asc升序,desc降序];
---改
---查
索引
create index idx_name on table(name);
where 条件语句
where chinese=90;
where class in (1,2,3);
where class not in (1,2,3);
where class !=4;
where class between 1 and 3; 从1 到3
---计数函数
select count(*) from score; 对所有字段统计计算行数,取最大值
select count(name) from score;
---其他语句
select distinct english from score; 去重
select * from score limit 3,4; 从第4行开始,显示4行数据
select * from score order by chinese desc limit 0,3;
select class,count(*) from student group by class; 查询后分组 聚合函数
后缀xx.xx 两个表有相同的字段时用来区别
---max()min() avg()sum()函数求最大最小值
---运算符+-*/
select maths,maths+5 from score;
---连接查询
左连接left join on(以左边的表为主,右边的表没有数据就为空)
select xx,xx.xx,xx from table1,table2 table1 left join table2 on xx.id=xx.id;
select stu.*,ach.* from stu left join ach on stu.id=ach.id;
右连接(以右边的表为主,左边的表没有数据就为空)
select xx,xx.xx,xx from table1,table2 table1 right join table2 on xx.id=xx.id;
内连接inner join(展示两个表中共有的记录)
select stu.*,sc.*,maths+sc.chinese+sc.english total from student stu join score sc on stu.id=sc.id;
外连接()
-
数据去重
将两张表数据合并到一起去重
select id,name,class from student union select class,number,maths from score;
单张表数据
select distinct name from (select name from fuck where fs>80) t(必须给表一个aliasb别名);
找出重复的数据
select * from fuck where name in(select name from fuck group by name having count(*)>1);(一个字段)
select * from fuck where (name,km,fs) in (select name,km,fs from fuck group by name,km,fs having count(*)>1);
所有语句
select distinct sum() from join on where group by having order by limit;
多表查询
select table1.xx table2.xx from table1,table2 where table1.id=table2.id;
delete stu.*,ach.* from stu,ach where stu.id=ach.id and name='hohn';(多表删除)
执行顺序
from > join on >where >group by>sum()>having>select>distinct>order by>limit
查询每门成绩
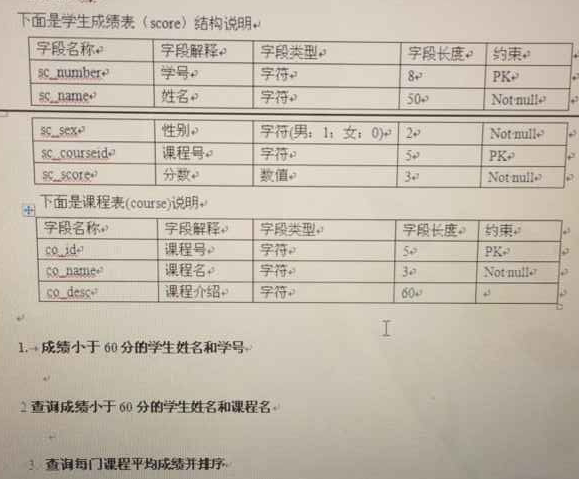
select co_name ,avg(sc_score) avg from score,course where score.couresid=course.co_id group by co_name order avg;
select co_name,avg from (select sc_courseid,avg(sc_source) avg from score group by sc_courseid) t1,course t2 where t1.sc_courseid =t2.co_id order by avg;
每门成绩大于80的学生
1.select name from fuck group by name having min(fs)>80;
2.select distinct name from fuck where name not in (select name from fuck where fs<80);
查询每个科目的最高分的学生信息
select * from student where id in (select t1.stu_id from score t1,(select c_name,max(grade) as grade from score group by c_name) t2 where t1.c_name=t2.c_name and t1.grade=t2.grade);
select student.* from student,(select score.* from score,(select max(grade) grade,c_name from score group by c_name) t1 where
------------------------最大成绩,名称-----------------------
score.c_name=t1.c_name and score.grade=t1.grade) t2 where student.id=t2.stu_id;
每个部门年龄最大员工信息
select t2.name,dept.d_name from dept,(select emp.name,emp.d_id from emp,(select d_id,max(age) max from emp group by d_id) t1 where emp.d_id=t1.d_id and emp.age=t1.max) t2 where t2.d_id=dept.d_id;
每个部门总收入
select d_name,t1.sum from dept,(select d_id,sum(salary) sum from emp group by d_id)t1 where t1.d_id=dept.d_id;
部门收入大于8000
select dept.*,sum from dept,(select d_id,sum(salary) sum from emp group by d_id)t1 where t1.d_id=dept.d_id and sum>8000;
哪个部门没有员工入
每门成绩大于80的学生
select name from fuck group by name having min(fs)>80;
select distinct name from fuck where name not in (select name from fuck where fs<80);
select id,name,age,time,salary,d_id,row_nunmber() over(partition by d_id order by age desc) rn from emp;(分组最大值函数)
+------+------------+ +----+------+-----+ +----+--------+
| name | department | | id | name | sex | | id | salary |
+------+------------+ +----+------+-----+
| 孙七 | 开发 | | 1 | 张三 | 女 | | 1 | 1000 |
| 王五 | 测试 | | 3 | 王五 | 男 | | 2 | 2000 |
| 赵六 | 测试 | | 4 | 赵六 | 男 | | 3 | 2000 |
| 李四 | 开发 | | 5 | 孙七 | 女 | | 4 | 3000 |
| 5 | 5000 |
查处每个部门及部门平均工资由高到低排序;
一
select distinct department,avg(salary) from (select department,t1.salary from department,(select employee.name,salary.salary from employee left join salary on employee.id=salary.id) t1 where department.name=t1.name) t2 group by department order by avg(salary) desc;
二
select distinct t2.department,avg(salary) avg from department,(select department,salary from department,(select name,salary from employee,salary where employee.id=salary.id) t1 where department.name=t1.name) t2 group by t2.department order by avg desc;
三
select department,avg(salary) from department,employee,salary where department.name=employee.name and employee.id=salary.id group by department order by avg(salary) desc;
查询部门工资最高员工姓名(先连接三张表求出部门和最高工资,在连接四章表求出id)
select department.name,max.salary
from department,employee,salary,(select department,max(salary) salary
from department,employee,salary where department.name=employee.name and employee.id=salary.id group by department) max
where department.name=employee.name and employee.id=salary.id and max.salary=salary.salary and department.department=max.department;
select * from tb_student where sno in (select sno from tb_score where grade>(select avg(degree) from tb_score));
select * from tb_student where sno in (select sno from tb_score,(select avg(degree) a from tb_score) avg where avg.a<degree);
只是补充:
like %匹配任意个字符 _ 匹配单个字符
concat() 连接函数 构造可以变化的
concat(name,'_%')
Monaco-Ville"是合併國家名字 "Monaco" 和延伸詞"-Ville".
顯示國家名字,及其延伸詞,如首都是國家名字的延伸。
你可以使用SQL函數 REPLACE 或 MID.
select name,replace(capital,name,'')as ext
from world
where capital like concat(name,'_%')
Show the name and the continent - but substitute Eurasia for Europe and Asia; substitute America - for each country in North America or South America or Caribbean. Show countries beginning with A or B
select name,
CASE WHEN continent='Europe' OR continent='Asia' THEN 'Eurasia'
ELSE 'America' END
from world
where name like 'A%' or name like 'B%'
order by name