5.1sort 命令
sort [选项] [输入文件]
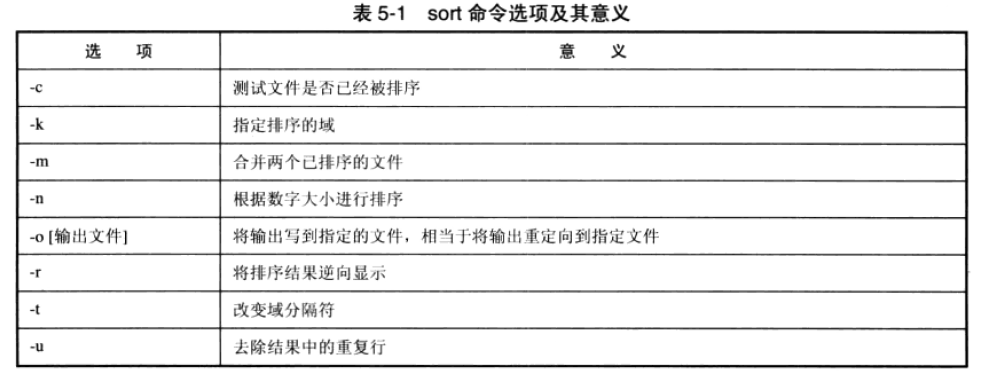
5.1sort排序命令,排序的域和awk差不多
-t设置分隔符
-k用来指定排序的域,默认情况下都是按照第一域来进行排序
-n用来指定根据数字的大小进行排序
-r用于将排序结果逆向输出
-u选项用于去除排序结果中的重复行
-o控制输出结果的显示
-c选项用于测试结果是否排好序
-m用于将排好序的两个文件合并
5.1.2sort和awk两者有效的结合起来,可以有效的对文本块进行排序,4条命令和3个管道,(这个排序没太看明白)
5.2uniq命令
用于去除文本中的重复行,必须是连续重复出现的行,与sort -u不一样 后者是所有的重复行都被除去
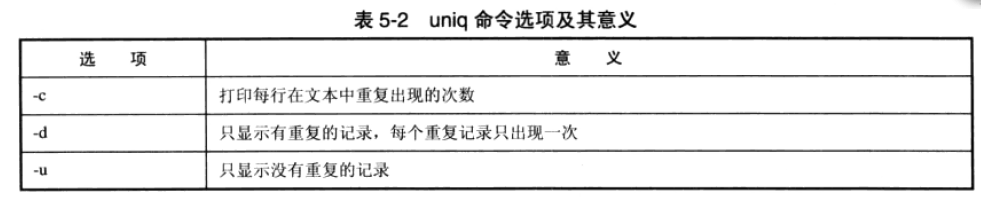
统计单词出现次数该程序没太看懂


5.3join命令
join用于连接已经排好序的记录(排序指的是哪个域排好序呢?),连接两个文件具有相同域的记录。

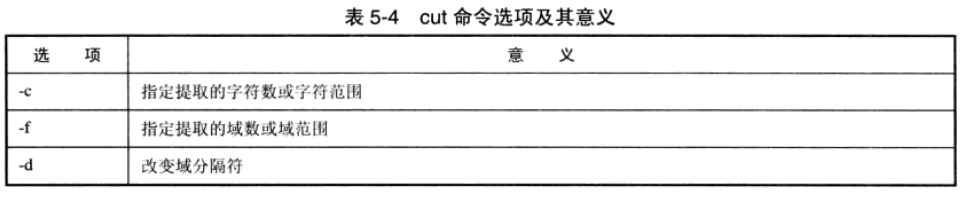
5.4cut命令
用于将记录按域或者按行提取文本
5.5paste命令
用于将文本文件,或标准输出中的内容黏贴到新的文件中,它可以将来自不同文件的数据黏贴到一起,形成新的文件。
5.6split用于将大文件切割成小文件。它可以按照文件的行数,字节数来切割文件,并在输出的时候自动加上行号。

-b和-C选项在切割文件的时候,-b选项中的某个文件完全按照指定大小来切割。而-C选项中,还要考虑记录的完成性,所以被切分成的文件大小可能不是指定大小


5.7tr命令 实现字符转换功能,和sed命令类似,但比sed命令简单,


5.8tar命令进行Linux系统的解压和压缩
上机练习题:


(1)sort -t- -k2 student (如果专业相同,会怎么排呢)
(2)sort -t- -k3nr student (如果出生年份也相同呢)
(3)sort -t- -k4 -o province student (如何指定第二排序的域)
(4)sort -t- -c student
sort -t- -c province
(5) 不会。。。。。。。。。。

cat PROFESSOR.db | awk -v RS=" " '{gsub(" ","@");print}' | sort -t@ -k2 | awk -v ORS=" " '{gsub("@"," ");print}'

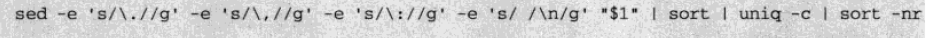
3.再加上-e 's/://g' -e 's/-//g' -e 's/@//g'
4.不会。。。。。。。。。。。。

sort -t- student
sort -t- score
join -t- student score

6. cut -d- -f1 >file1
cut -d- -f2 >file2
paste -d- file1 file2
7.cut -d- -f1 | paste -d" " ---
![]()

没太懂题目的意思。。。。。。。

9,10不太会。。。
11.split -1 student cut_student.ab
ls cut_student*
split -C50 student
12 tr "[a-z]" "[A-Z]" <student