C/C++ 预处理元编程
从一个问题开始
以下代码存在结构性重复,如何消除?
// EventId.h
enum EventId
{
setupEventId = 0x4001,
cfgEventId,
recfgEventId,
releaseEventId
// ...
};
// EventCounter.h
struct EventCounter
{
U32 setupEventCounter;
U32 cfgEventCounter;
U32 recfgEventCounter;
U32 releaseEventCounter;
// ...
};
// EventCounter.c
EventCounter g_counter = {0};
// CountEvent.c
void countEvent(U32 eventId)
{
switch(eventId)
{
case setupEventId:
g_counter.setupEventCounter++;
break;
case cfgEventId:
g_counter.cfgEventCounter++;
break;
case recfgEventId:
g_counter.recfgEventCounter++;
break;
case releaseEventId:
g_counter.releaseEventCounter++;
break;
// ...
}
}
// PrintCounter.c
void printCounter()
{
printf("setupEventCounter = %d \n", g_Counter.setupEventCounter);
printf("cfgEventCounter = %d \n", g_Counter.cfgEventCounter);
printf("recfgEventCounter = %d \n", g_Counter.recfgEventCounter);
printf("releaseEventCounter = %d \n", g_Counter.releaseEventCounter);
// ...
}
上面的例子中除了每个文件内部有结构性重复,文件之间也有结构性重复!当我们每增加一个消息的定义,都需要依次在四个文件中增加对应的消息ID定义,计数器定义,计数器累加以及计数器打印的代码,在整个过程中还要保证所有变量名、字符串等的命名一致性问题。
那么如何解决上述问题呢?最容易想到的方式就是定义一个元数据文件,然后写个脚本自动扫描元数据文件,自动生成上述四个文件。
例如可以定义一个xml格式的元数据文件event.xml:
<?xml version = "1.0 ecoding = utf-8>
<event>
<item> setup </item>
<item> cfg </item>
<item> recfg </item>
<item> release </item>
<!-- more event-->
</event>
然后再写一个python脚本,按照规则从这个xml自动生成EventId.h、EventCounter.h, CountEvent.c、PrintEvent.c,如下图所示:

在大的项目中频繁使用上述方式,往往导致纯业务代码的技术栈不一致!例如元数据定义可以用xml、yaml、json..., 脚本语言可以用python、ruby、perl..., 将会引起如下问题:
- 需要项目中所有构建代码的机器上安装对应脚本语言的解释器;
- 版本的构建过程管理变得复杂;
- 受限于业务软件人员能力,对于脚本的修改可能会集中在熟练掌握脚本语言语法的人身上;
- 连贯的代码开发过程,却要在不同IDE和工具链之间切换;
那么有没有办法利用C/C++语言自身完成上述工作呢? 有!那就是利用预处理元编程技巧!
预处理元编程
对于上述问题,我们回顾利用脚本的解决方法: 先定义一份元数据,然后利用脚本将其解释成四种不同的展现方式! 一份描述,想要在不同场合下不同含义,如果利用宿主语言解决的手段就是多态!
大多数程序员都知道对于C++语言,可以实施多态的阶段分为静态期和动态期。静态期指的是编译器在编译阶段确定多态结果,而动态期是在程序运行期确定!静态多态的常用手段有函数/符号重载、模板等,动态多态的手段往往就是虚函数。
事实上很少有人关注,C/C++的预处理阶段也是实施多态的一个重要阶段,而这时可以采用的手段就是宏!
宏是一个很强大的工具!简单来说宏就是文本替换,正是如此宏可以用来做代码生成,我们把利用宏来做代码生成的技巧叫做预处理元编程!
往往越是强大的东西,越容易被误用,所以很多教科书都在劝大家谨慎使用宏,语言层面很多原来靠宏来做的事情逐渐都有替代手段出现,但是唯独代码生成这一点却没有能够完全替代宏的方式。恰当的使用宏来做代码生成,可以解决别的技巧很难完成的事情!相信如果有一天C/C++把宏从语言中剔除掉,整个语言将会变得无趣很多:)
下面我们看看如何用预处理元编程来解决上述例子中的问题!
第一种做法
和脚本解决方案类似,首先要定义元数据文件,只不过这次元数据文件是一个C/C++头文件,对元数据的定义使用宏函数!
//EventMeta.h
EVENTS_BEGIN(Event, 0x4000)
EVENT(setup)
EVENT(cfg)
EVENT(recfg)
EVENT(release)
EVENTS_END()
这份元数据如何解释,完全看其中的EVENTS_BEGIN、EVENT、EVENTS_END宏函数如何被解释了!
接下来我们定义四个解释器文件,分别对上述三个宏做不同的解释,最终做到将元数据可以翻译到消息ID定义,消息计数器定义,计数函数和打印函数。
// StructInterpreter.h
#define EVENTS_BEGIN(name, id_offset) struct name##Counter {
#define EVENT(event) U32 event##EventCounter;
#define EVENTS_END() };
// EventIdInterpreter.h
#define EVENTS_BEGIN(name, id_offset) enum name##Id { name##BaseId = id_offset
#define EVENT(event) , event##EventId
#define EVENTS_END() };
// CountInterpreter.h
#define EVENTS_BEGIN(name, id_offset) \
void count##name(U32 eventId) \
{ \
switch(eventId){
#define EVENT(event) \
case event##EventId: \
g_counter.event##EventCounter++; \
break;
#define EVENTS_END() }};
// PrintInterpreter.h
#define EVENTS_BEGIN(name, id_offset) \
void printCounter() {
#define EVENT(event) \
printf(#event"EventCounter = %d \n", g_counter.event##EventCounter);
#define EVENTS_END() };
由于我们给了同一组宏多份重复的定义,所以需要定义一个宏擦除文件,以免编译器告警!
// UndefInterpreter.h
#ifdef EVENTS_BEGIN
#undef EVENTS_BEGIN
#endif
#ifdef EVENT
#undef EVENT
#endif
#ifdef EVENTS_END
#undef EVENTS_END
#endif
这样我们就完成了类似脚本工具所作的工作! 注意上面的元数据文件、四个解释器文件以及最后的宏擦除文件都是头文件,但是都不要加头文件include guard!
最后我们用上述定义好的文件来生成最终的消息ID定义、计数器定义、计数函数以及打印函数!
// EventId.h
#ifndef H529C3CEC_F5B5_4E3D_9185_D82AF679C1D4
#define H529C3CEC_F5B5_4E3D_9185_D82AF679C1D4
#include "interpreter/EventIdInterpreter.h"
#include "EventMeta.h"
#include "interpreter/UndefInterpreter.h"
#endif
//EventCounter.h
#ifndef HD8D5D593_CCA2_4FE9_9456_4AD69EF8FA54
#define HD8D5D593_CCA2_4FE9_9456_4AD69EF8FA54
#include "BaseTypes.h"
#include "interpreter/StructInterpreter.h"
#include "EventMeta.h"
#include "interpreter/UndefInterpreter.h"
#endif
// CountEvent.c
#include "EventId.h"
#include "EventCounter.h"
#include "interpreter/CountInterpreter.h"
#include "EventMeta.h"
#include "interpreter/UndefInterpreter.h"
// PrintCounter.c
#include "EventCounter.h"
#include <stdio.h>
#include "interpreter/PrintInterpreter.h"
#include "EventMeta.h"
#include "interpreter/UndefInterpreter.h"
可以看到,代码生成的写法很简单,就是依次包含解释器文件、元数据文件和宏擦除文件。 生成文件就是最终我们代码要使用的文件,这时头文件则需要加include guard,每个文件还要包含自身依赖的头文件,做到自满足。
和使用脚本的解决方案效果一样,我们以后每次增加一个消息定义只用更改元数据文件即可,其它所有地方会自动生成,避免了很多重复性劳动!重要的是,预处理元编程仍然是使用C/C++技术栈,不会复杂化开发和构建过程!
另一种做法
除了上述做法外,还有另一种做法,就是把元数据文件定义成一个宏函数,然后将解释器定义成不同名的宏函数,传给元数据对应的宏函数。这种做法可以避免定义宏擦除文件。具体如下:
// EventMeta.h
#define EVENT_DEF( __EVENTS_BEGIN \
, __EVENT \
, __EVENTS_END) \
__EVENTS_BEGIN(name, id_offset) \
__EVENT(setup) \
__EVENT(cfg) \
__EVENT(recfg) \
__EVENT(release) \
__EVENTS_END()
依然需要写四个解释器文件,每个里面各自实现一份__EVENTS_BEGIN、__EVENT和__EVENTS_END的宏函数定义。不同的是每个解释器文件中的宏函数可以起更合适的名字,定义只要满足宏函数接口特征要求即可! 例如”StructInterpreter.h”和“EventIdInterpreter.h"的定义如下:
// StructInterpreter.h
#define STRUCT_BEGIN(name, id_offset) struct name##Counter {
#define FIELD(event) U32 event##EventCounter;
#define STRUCT_END() };
// EventIdInterpreter.h
#define EVENT_ID_BEGIN(name, id_offset) enum name##Id { name##BaseId = id_offset
#define EVENT_ID(event) , event##EventId
#define EVENT_ID_END() };
最后做代码生成,只要把解释器里面定义的宏函数注入给元数据文件定义的宏函数即可:
// EventId.h
#ifndef H529C3CEC_F5B5_4E3D_9185_D82AF679C1D4
#define H529C3CEC_F5B5_4E3D_9185_D82AF679C1D4
#include "interpreter/EventIdInterpreter.h"
#include "EventMeta.h"
EVENT_DEF(EVENT_ID_BEGIN, EVENT_ID, EVENT_ID_END)
#endif
//EventCounter.h
#ifndef HD8D5D593_CCA2_4FE9_9456_4AD69EF8FA54
#define HD8D5D593_CCA2_4FE9_9456_4AD69EF8FA54
#include "BaseTypes.h"
#include "interpreter/StructInterpreter.h"
#include "EventMeta.h"
EVENT_DEF(STRUCT_BEGIN, FIELD, STRUCT_END)
#endif
该方法中由于没有重名宏,所以也就不再需要宏擦除文件了。计数函数和打印函数的生成,大家可以自行练习!
上述两种方法,各自适合不同场合:
-
第一种方法适合于需要定义大量元数据的场合! 优点是元数据的描述比较简洁,如同在使用内部DSL。 但是这种方法由于解释器文件之间存在同名宏,所以你的IDE在自动符号解析时可能会发出抱怨;
-
第二种方法由于避免了重名宏,所以元数据和解释器的定义不受文件约束。这对于IDE比较友好! 但是定义元数据的方式会受到宏的语法限制(例如以’ \’换行的噪音)。另外当元数据定义用到大量不同的宏函数时,每次代码生成做宏函数注入也很累。
构建内部DSL
在C++语言中,模板元编程是构建内部DSL的常用武器。模板元编程本质上是一种函数式编程,该技术可以让C++在编译期做代码生成。在实际使用中结合预处理元编程和模板元编程,可以简化彼此的复杂度,让代码生成更加灵活,是C++构建内部DSL的强大武器!
以下是一个在真实项目中应用的例子!
在重构某一遗留系统代码时,发现该系统包含一个模块,用来接收另一个控制器子系统传来的配置消息,然后根据配置消息中携带的参数值进行领域对象建立、修改、删除等操作。该模块可以接收的配置消息有几十种,消息均采用结构体定义,每个消息里面可以嵌套包含其它子结构体,对于消息中的每个子结构体可以有一个对应的present字段指示该子结构体内的所有参数值在这次配置中是否有效。消息中的每个参数字段都有一个合法范围,以及一个预先定义好的错误码。对一个消息的合法性校验就是逐个检查消息里面每一个字段以及对应present为true的子结构体内的每个字段是否在其预定的合法范围内,如果某一个字段不在合法范围内,就做错误log记录,然后函数结束并返回对应的错误码!如下是一条配置消息的校验函数的代码原型:
Status XxxMsgCheck(const XxxMsg& msg)
{
// ...
if((MIN_VLAUE1 > msg.field1) || (msg.field1 > MAX_VALUE1))
{
ERR_LOG("XxxMsg : field1 is error, expect range[%d, %d], actual value(%d)", MIN_VALUE1, MAX_VALUE1, msg.field1);
return XXX_MSG_FIELD1_ERRCODE;
}
// ...
if(msg.subMsg1Present)
{
if(msg.subMsg1.field1 > MAX_VALUE2)
{
ERR_LOG("XxxMsg->subMsg1 : field1 is error, expect range[0, %d], actual value(%d)", MAX_VALUE2, msg.subMsg1.field1);
return XXX_MSG_FIELD2_ERRCODE;
}
// ...
}
if(msg.subMsg2Present)
{
//...
}
// ...
return SUCCESS;
}
可以看到消息校验函数内的代码存在大量的结构性重复,而这样的函数在该模块中一共存在几十个。模块中最大的一个消息包含四十多个子结构体,展开后一共有800多个参数字段,仅对这一个消息的校验函数就达三千多行。该模块一共不足三万行,而类似这样的消息校验代码就占了一万多行,还不算为每个字段定义错误码、合法范围边界值等宏带来的头文件开销。对这样一个模块,消息校验并不是其领域核心,但是结构性重复导致其占用了相当大的代码比例,核心的领域逻辑代码反而被淹没在其中。
另一个由此引入的问题在于测试,在对该模块进行包围测试的时候发现需要构造一条合法的消息很累。大多数测试仅需关注消息中的几个参数字段,但是为了让消息通过校验,需要把消息中所有的字段都赋上合法的值,否则就不能通过校验。于是有的开发人员在测试的时候,干脆采用一种侵入式的做法,通过预处理宏或者全局变量的方式把消息校验函数关闭。
上述问题可能是类似系统中的一个通用问题,根据不同的场景可以在不同的层面上去解决。例如我们可以追问这种参数校验是否有价值,以引起防御式编程风格的争辩;或者在不考虑性能的时候引入一种数据字典的解决方案;或者为了保持兼容来做代码生成...
在这里我们给出利用预处理元编程构造内部DSL做代码生成的解决方式!
通过分析,上述代码中一共存在四种明显的结构性重复。试想每当你为某一个消息增加一个字段,需要做的事情有:1)在消息结构体中增加字段定义;2)为该字段定义错误码;3)在校验函数中增加该字段的合法性校验代码;4)修改所有使用该消息的测试,将该字段设置成合法值,以便让原测试中的消息能够通过校验。
那么采用预编译元编程的解决思路就是:定义一份元数据描述规则,然后写四个解释器文件;通过解释器文件对元数据进行解释自动生成上述四种代码。用户后续就只用按照规则定义元数据文件,在里面描述消息结构特征、以及每个字段的合法范围特征即可。
考虑到消息的结构体定义往往是接口文件,一般修改受限;而且别的子系统也要使用,需要考虑兼容别人的使用习惯,所以对于消息结构体的定义暂不修改,下面只用代码生成来解决其它三种重复。
在本场景中,由于可预期元数据数量很多,而且会经常发生变更,所以我们采用前面介绍的第一种预处理元编程的方式来做。在这里元数据的描述规则设计很重要,它决定了用户将来使用是否方便,是否易于理解。事实上其本质就是在定义一种DSL,需要斟酌其中每一个关键字的含义和用法。
例如对于下面的消息:
// XxxMsg.h
struct XxxMsg
{
U8 field1;
U32 field2;
U16 field3;
U16 field4;
U16 field5;
U16 field6;
};
按照我们设计的DSL,对其元数据描述文件如下:
// XxxMsgMeta.h
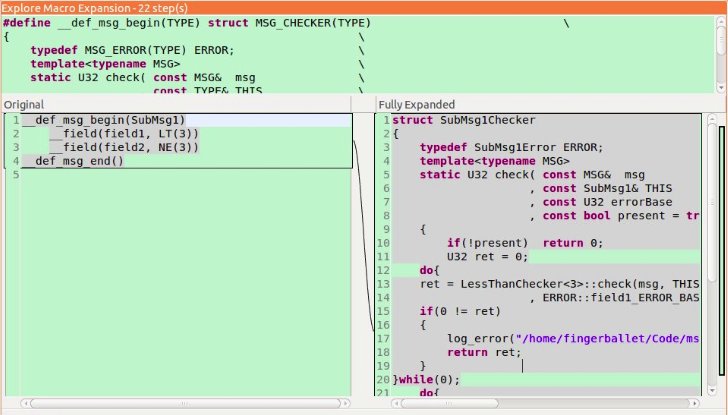
__def_msg_begin(XxxMsg)
__field(field1, LT(3))
__field(field2, NE(3))
__field(field3, GE(1))
__field(field4, BT(2, 128))
__field(field5, __())
__field(field6, OR(LE(2), EQ(255)))
__def_msg_end()
可以看到通过__def_msg_begin和__def_msg_end来进行消息的描述。其中需要描述每一个消息字段的名称和合法范围。合法范围的定义通过下面几种关键字:
- EQ : ==
- NE : !=
- LE : =<
- LT : <
- GE : >=
- GT : >
- BT : between[min, max]
- OR : || , 即用来组合两个条件式,满足其一即可。
- __ : omit, 即对该字段不校验
- OP : user-defined special operation, 即用户自定义的字段校验方式
所有的静态范围描述,使用上面的关键字组合就够了;对于动态规则,用户需要通过关键字OP来扩展自定义的校验方式。
例如对于下面这个消息SpecialOpMsg,其中的field2字段的校验是动态的,它必须大于field1字段的值才是合法的:
// SpecialOpMsg.h
struct SpecialOpMsg
{
U8 field1;
U8 field2;
};
这时对于field2字段需要按照如下方式自定义一个Operation类,其中使用DECL_CHECK来定义一个方法,描述field2字段的校验规则;如果该消息要被测试用例使用的话则还需要用DECL_CONSTRUCT来定义一个field2字段的创建函数。
在定义方法的时候,消息的名字msg,field2字段的错误码error都是预定义好的,直接使用即可。
// Field2Op.h
#include "FieldOpCommon.h"
struct Field2Op
{
DECL_CHECK()
{
return (field2 > msg.field1) ? 0 : error;
}
DECL_CONSTRUCT()
{
field2 = msg.field1 + 1;
}
};
// SpecialOpMsgMeta.h
__def_msg_begin(SpecialOpMsg)
__field(field1, GE(10))
__field(field2, OP(Field2Op))
__def_msg_end()
当有消息结构嵌套的时候,需要逐个描述每个子结构,最后用子结构拼装最终的消息描述。
例如对于如下消息结构:
// SimpleMsg.h
struct SubMsg1
{
U8 field1;
U32 field2;
};
struct SubMsg2
{
U16 field1;
};
struct SimpleMsg
{
U32 field1;
SubMsg1 subMsg1;
U16 subMsg2Present;
SubMsg2 subMsg2;
};
定义的元数据描述如下:
// SimpleMsgMeta.h
/////////////////////////////////////////////
__def_msg_begin(SubMsg1)
__field(field1, LT(3))
__field(field2, NE(3))
__def_msg_end()
/////////////////////////////////////////////
__def_msg_begin(SubMsg2)
__field(field1, GE(3))
__def_msg_end()
/////////////////////////////////////////////
__def_msg_begin(SimpleMsg)
__field(field1, BT(3,5))
__sub_msg(SubMsg1, subMsg1)
__opt_sub_msg(SubMsg2, subMsg2, subMsg2Present)
__def_msg_end()
可以看到,可以用__sub_msg来指定包含的子结构;如果某个子结构是由present字段指明是否进行校验的话,那么就使用__opt_sub_msg,指明子结构体类型,字段名以及present对应的字段名称。
对消息描述方式的介绍就到这里!事实上还有很多实现上的细节,例如:如果字段或者子结构是数组的情况;如果是数组,数组大小可以是静态的或者由某一个字段指明大小的;整个消息中可以包含一个开关字段,如果开关关闭的话则本消息整体都不用校验,等等。以下是目前支持的所有描述方式:
- __field : 描述一个字段,需要指明字段的合法范围;
- __opt_field:描述一个可选字段,除了给出可选范围,还要给出对应的present字段;
- __switch_field : 开关字段,当该字段关闭态的话,整个消息不做校验;
- __fix_arr_field : 静态数组字段,需要指明字段合法范围,还需要指明数组静态大小;
- __dyn_arr_field : 动态数组字段,需要指明字段的合法范围,还需要给出指示数组大小的字段;
- __fix_arr_opt_field: 可选的静态数组字段,在__fix_arr_field的基础上给出对应的present字段;
- __dyn_arr_opt_field: 可选的动态数组字段,在__dyn_arr_field的基础上给出对应的present字段;
- __sub_msg: 描述一个包含的子结构;
- __opt_sub_msg:描述一个包含的可选子结构体;在__sub_msg的基础上还需给出对应的present字段;
- __fix_arr_sub_msg:静态数组子结构;在__sub_msg的基础上还需给出静态数组的大小;
- __dyn_arr_sub_msg:动态数组子结构;在__sub_msg的基础上还需给给出指示该数组大小的字段;
- __fix_arr_opt_sub_msg:可选的静态数组子结构;在__fix_arr_sub_msg的基础上还需给出对应的present字段;
- __dyn_arr_opt_sub_msg:可选的动态数组子结构;在__dyn_arr_sub_msg的基础上还需给出对应的present字段;
当利用上述规则描述好一个消息后,我们就可以用写好的预处理解释器来生成最终我们想要的代码了。例如对上面的SimpleMsg, 我们定义如下文件:
#include "SimpleMsg.h"
#include "ErrorCodeInterpret.h"
#include "SimpleMsgMeta.h"
#include "ConstrantInterpret.h"
#include "SimpleMsgMeta.h"
#include "ConstructInterpret.h"
#include "SimpleMsgMeta.h"
const U32 SIMPLE_MSG_ERROR_OFFSET = 0x4001;
__def_default_msg(SimpleMsg, SIMPLE_MSG_ERROR_OFFSET);
上面分别用ErrorCodeInterpret.h、ConstrantInterpret.h和ConstructInterpret.h把SimpleMsg消息的元数据描述生成了对应的错误码、供消息校验用的verify方法以及供测试用例使用的construct方法。在实际中,我们往往会把上面几个代码生成放在不同文件中,对于construct的生成只放在测试中。注意最后需要用__def_default_msg描述,给出消息的错误码起始偏移值。另外,可以将__def_default_msg替换成__def_msg,这样还可以在消息中增加其它自定义方法。在自定义方法中可以直接使用消息的所有字段。例如:
__def_msg(SimpleMsg, ERROR_OFFSET)
{
bool isXXX() const
{
return (field1 + subMsg1.field1) == 10;
}
};
经过上述代码生成后,就可以把原来的plain msg转变成一个method-ful msg。它的每个字段都自动定义了一个从起始值递增的错误码。它包含一个verify方法,这个方法会根据规则对每个字段做校验,在错误的时候记录log并且返回对应的错误码。它还可以包含用户自定义的其它成员方法。
例如对于SimpleMsg我们可以这样使用:
TEST(MagCc, should_return_the_error_code_correctly)
{
SimpleMsg msg;
msg.field1 = 3; // OK : __field(field1, BT(3,5))
msg.subMsg1.field1 = 2; // OK : __field(field1, LT(3))
msg.subMsg1.field2 = 1; // OK : __field(field2, NE(3))
msg.subMsg2Present = 1;
msg.subMsg2.field1 = 2; // ERROR:__field(field1, GE(3))
ASSERT_EQ(0x4004, MSG_WRAPPER(SimpleMsg)::by(msg).verify());
}
如果生成了construct方法的话,那么测试用例就可以直接调用其生成一个所有字段都在合法范围内的消息码流:
TEST(MagCc, should_construct_msg_according_the_range_description_correctly)
{
SimpleMsg msg;
MSG_CTOR(SimpleMsg)::construct(msg);
ASSERT_EQ(3, msg.field1);
ASSERT_EQ(2, msg.subMsg1.field1);
ASSERT_NE(3, msg.subMsg1.field2);
ASSERT_EQ(1, msg.subMsg2Present);
ASSERT_EQ(3, msg.subMsg2.field1);
}
对于错误码、verify和construct的具体生成实现,主要定义在几个解释器文件里面。对verify和construct的实现使用了一些模板的技巧。利用预处理元编程,可以将对应的宏翻译到不同的模板实现上去,所以每组模板可以只用关注一个方面,简化了模板的使用复杂度。对于预处理元编程在构造内部DSL上的使用就介绍到这里,本例中的其它细节不再展开,具体的源代码放在msgcc,可自行下载阅读。
工程实践
由于预处理元编程主要在使用宏的技巧,所以在工程实践中,使用可以自动宏展开提示的IDE,会使这一技巧的使用变得容易很多! 例如eclipse-cdt中使用快捷键“ctr+=”,可以直接在IDE中看到宏展开后的效果。
另外,也可以给makefile中增加预处理文件的构建目标,在出问题的时候可以构建出预处理后的源代码文件,以方便问题定位。
# makefile example
$(TARGET_PATH)%.i : $(SOURCE_PATH)%.cpp
$(CXX) -E -o $@ -c $<
总结
预处理元编程利用了宏的文本替换原理,给一组宏不同的解释,做到可以将一份元数据解释成不同的形式。预处理元编程相比用脚本做代码生成的方案,和内部DSL相比较外部DSL的优缺点基本一致,优点是可以保持技术栈一致,缺点是代码生成会受限于宿主语言的语法约束。
预处理元编程是一项很罕用的技术,但是使用在恰当的场合,将会是一项解决结构性重复的有效技巧! 在C++语言中预处理元编程和模板元编程的结合使用,是构造内部DSL的强大武器! 由于受限于宏本身的种种限制(难以调试、难以重构),该技巧最好用在结构模式大量重复,而每个变化方向都相对稳定的情况下! 预处理元编程千万不要滥用,使用前需要先评估其带来的复杂度和收益!
** 作者: MagicBowen, Email: e.bowen.wang@icloud.com; 转载请注明作者信息, 谢谢! **