心血来潮,想看下腾讯招聘岗都有些啥要求,都需要会啥,都需要做啥。腾讯招聘传送门。
本文仅用于学习与交流使用,不具有任何商业价值,如有问题,请与我联系,我将即时处理。--Python逐梦者。
数据爬取与处理
输入要查询的岗位,比如Python。如下图:
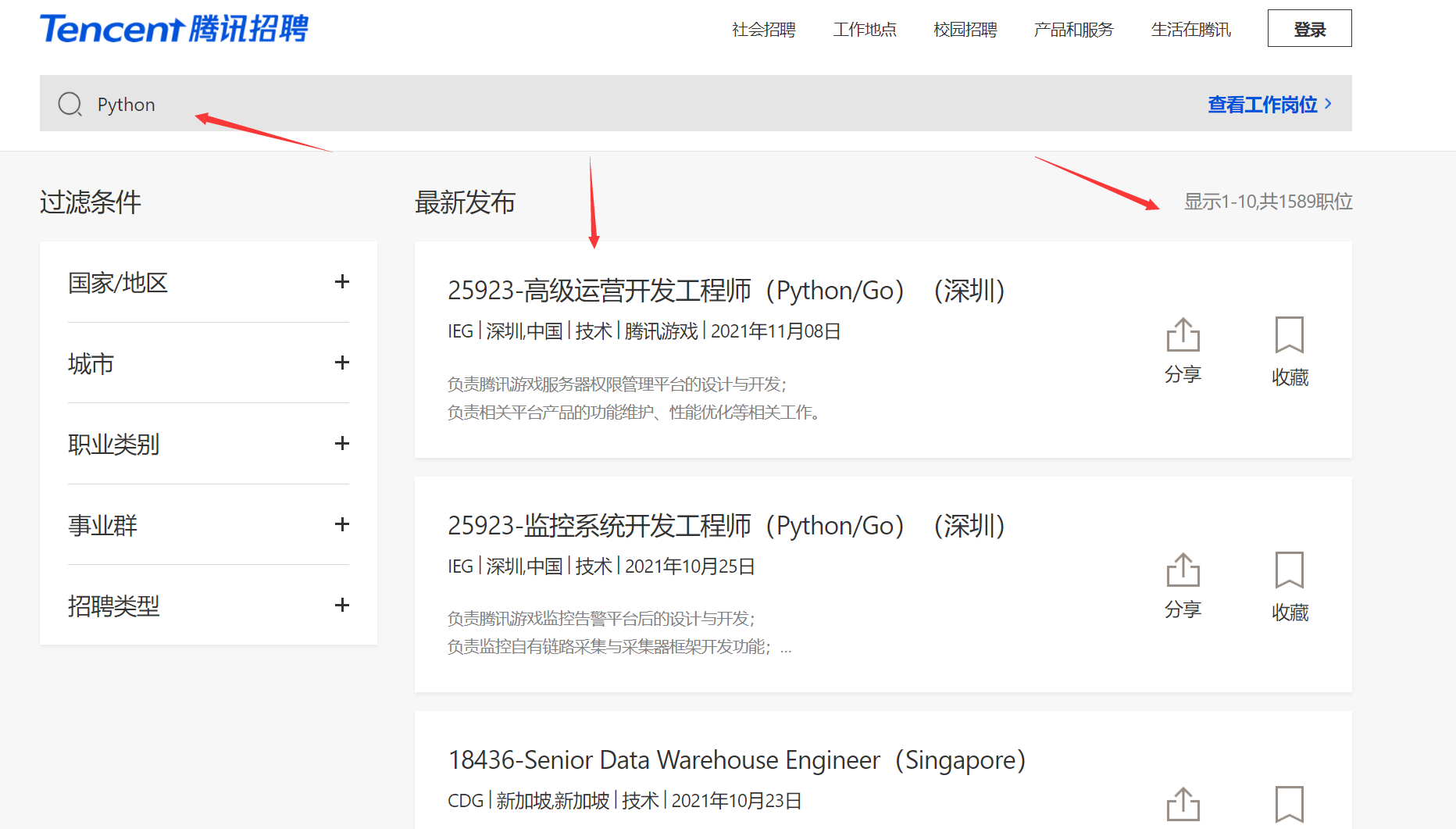
抱着试一试的态度吧,打开开发者工具,看有没有数据接口,如果没有的话,就只能用selenium,parsel,beautifulsoup之类的工具爬了。腾讯招聘还是没让人失望的,有数据接口:
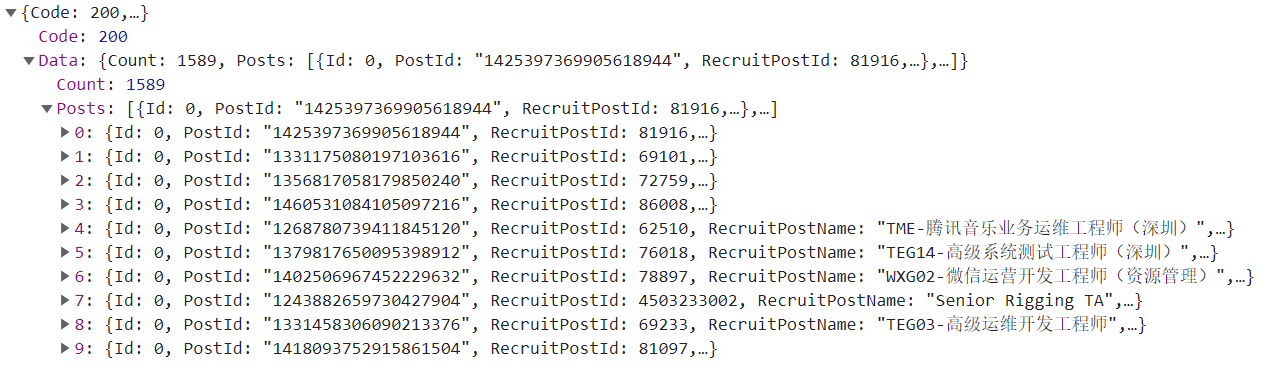
有数据接口就找参数变化:
https://careers.xxx.com/tencentcareer/api/post/Query?timestamp=1637217583960&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=&attrId=&keyword=Python&pageIndex=1&pageSize=10&language=zh-cn&area=cn https://careers.xxx.com/tencentcareer/api/post/Query?timestamp=1637217583960&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=&attrId=&keyword=Python&pageIndex=2&pageSize=10&language=zh-cn&area=cn https://careers.xxx.com/tencentcareer/api/post/Query?timestamp=1637217583960&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCat
发现参数就在index后有页码变化。先爬一页:
1 import requests 2 import json 3 import openpyxl 4 5 # 创建excel表格 6 wb = openpyxl.Workbook() 7 ws = wb.create_sheet(index=0) 8 ws.cell(row=1, column=1, value='职位') 9 ws.cell(row=1, column=2, value='国家') 10 ws.cell(row=1, column=3, value='城市') 11 ws.cell(row=1, column=4, value='职位类别') 12 ws.cell(row=1, column=5, value='更新时间') 13 ws.cell(row=1, column=6, value='简短描述') 14 ws.cell(row=1, column=7, value='详情页') 15 16 # 请求头 17 headers = { 18 'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36', 19 } 20 # 请求url 21 url = 'https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1637220381068&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=&attrId=&keyword=Python&pageIndex=1&pageSize=10&language=zh-cn&area=cn' 22 response = requests.get(url=url, headers=headers) 23 data = response.json()['Data']['Posts'] # 找到想要的数据 24 j = 1 # 初始计数 25 for item in data: 26 jobName = item['RecruitPostName'] # 职位标题 27 jobworkCountry = item['CountryName'] # 工作国家 28 jobworkCity = item['LocationName'] # 工作城市 29 jobCategory = item['CategoryName'] # 职位类别 30 timeUpdated = item['LastUpdateTime'] # 职位更新时间 31 jobShortDes = item['Responsibility'] # 职位简述 32 jobPostId = item['PostId'] # 职位id,用来做详情页的,从json直接获取的详情页,有些是国外腾讯的,我这里只要国内的详情页 33 jobDetaiPage = f'https://careers.tencent.com/jobdesc.html?postId={jobPostId}' 34 ws.cell(row=j + 1, column=1, value=jobName) # 在第一列第n行写入职位名称 35 ws.cell(row=j + 1, column=2, value=jobworkCountry) # 在第二列第n行写入职位所在国家 36 ws.cell(row=j + 1, column=3, value=jobworkCity) 37 ws.cell(row=j + 1, column=4, value=jobCategory) 38 ws.cell(row=j + 1, column=5, value=timeUpdated) 39 ws.cell(row=j + 1, column=6, value=jobShortDes) 40 ws.cell(row=j + 1, column=7, value=jobDetaiPage) 41 j += 1 # j自增1 42 print('j====================',str(j)) 43 wb.save('test腾讯.xlsx')
数据保存后的截图:

接下来就是翻页,目前还真的没搞懂怎么去翻页爬取,当然可以用csv保存,然后用pandas转换成csv,但是我有强迫症,我要有一个结果。
拎了那么久,忽然发现openpyxl可以append,瞬间解决翻页的问题。脑子里瞬间一万只神兽,原来自己可以这么蠢。
1 """ 2 爬取腾讯招聘 3 """ 4 import pprint 5 import time 6 import random 7 import openpyxl as op 8 import requests 9 import json 10 11 # 创建excel文档 12 wb = op.Workbook() 13 ws = wb.create_sheet(index=0) 14 ws.cell(row=1, column=1, value='职位') 15 ws.cell(row=1, column=2, value='国家') 16 ws.cell(row=1, column=3, value='城市') 17 ws.cell(row=1, column=4, value='职位类别') 18 ws.cell(row=1, column=5, value='更新时间') 19 ws.cell(row=1, column=6, value='简短描述') 20 ws.cell(row=1, column=7, value='详情页') 21 22 # 请求头 23 headers = { 24 'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36', 25 } 26 # 翻页爬取 27 for page in range(1, 159 + 1): 28 time.sleep(random.randint(2, 5)) # 还是休眠一下吧,为别人的服务器着想 29 print(f'======================正在爬取第{page}页数据======================') 30 url = f'https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1637217786429&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=&attrId=&keyword=Python&pageIndex={page}&pageSize=10&language=zh-cn&area=cn' 31 response = requests.get(url=url,headers=headers) 32 res = response.json() # 获取到json数据 33 # 找到需要的数据 34 data = res['Data']['Posts'] 35 # print(len(data)) 36 # pprint.pprint(data) 37 # 开始循环读取数据 38 for item in data: 39 jobName = item['RecruitPostName'] # 职位标题 40 jobworkCountry = item['CountryName'] # 工作国家 41 jobworkCity = item['LocationName'] # 工作城市 42 jobCategory = item['CategoryName'] # 职位类别 43 timeUpdated = item['LastUpdateTime'] # 职位更新时间 44 jobShortDes = item['Responsibility'] # 职位简述 45 jobPostId = item['PostId'] # 职位id,用来做详情页的,从json直接获取的详情页,有些是国外腾讯的,我这里只要国内的详情页 46 jobDetaiPage = f'https://careers.tencent.com/jobdesc.html?postId={jobPostId}' # 详情页 47 print(jobName, jobworkCountry, jobworkCity, jobCategory, timeUpdated, jobShortDes, jobDetaiPage, sep=" | ") 48 time.sleep(2) #休眠查看结果 49 # 逐行写入数据 50 ws.append([jobName, jobworkCountry, jobworkCity, jobCategory, timeUpdated, jobShortDes, jobDetaiPage]) 51 # if page == 10: 52 # print('爬到第十页了,程序退出!') 53 # break 54 55 wb.save('腾讯Python岗.xlsx')
可视化
招聘岗位统计条形图:
1 """ 2 招聘职位分类柱状图和饼图 3 """ 4 # 先读取数据 5 import pandas as pd 6 from pyecharts.globals import ThemeType 7 import pyecharts.options as opts 8 from pyecharts.charts import Bar, Pie 9 10 # 读取excel表格 11 df = pd.read_excel('腾讯Python岗.xlsx') # 读取 12 data = df['职位类别'].value_counts() # 统计 13 14 x = data.index.tolist() # 索引列表,也就是职位列表列表 15 y = data.tolist() # 值列表,也就是统计的职位次数列表 16 17 print(x) #['技术', '产品', '设计', '战略与投资', '财务', '销售、服务与支持', '营销与公关', '法律与公共策略', '人力资源', '内容'] 18 print(y) #[1413, 80, 50, 16, 7, 5, 3, 3, 3, 2] 19 20 num = y # 数量,y轴数据 21 lab = x # 职位类别,标签数据,也就是x轴数据 22 # 数据准备好了就可以绘图了 23 bar = ( 24 Bar() 25 .add_xaxis(lab) # x轴,标签数据 26 .add_yaxis('', y_axis=num) # 第一个y轴数据 27 .set_global_opts( 28 title_opts=opts.TitleOpts( 29 title='腾讯招聘职位类别柱状图', 30 title_textstyle_opts=opts.TextStyleOpts(font_size=35)), 31 legend_opts=opts.LegendOpts(is_show=False), 32 ) 33 # .reversal_axis() # 翻转坐标轴 34 ) 35 bar.render('腾讯招聘岗位柱状图.html')
结果:
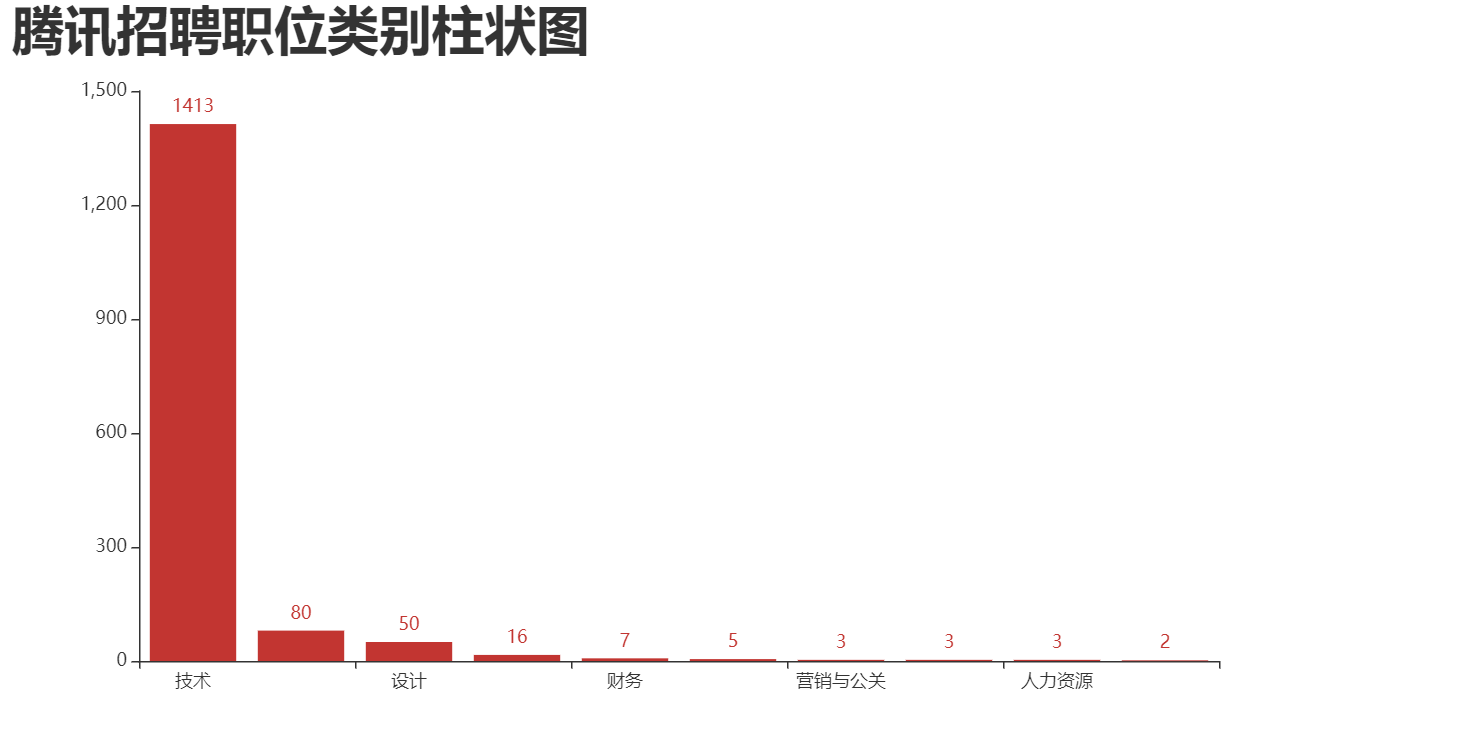
饼图:
1 # 先读取数据 2 import pandas as pd 3 from pyecharts.globals import ThemeType 4 import pyecharts.options as opts 5 from pyecharts.charts import Bar, Pie 6 7 # 读取excel表格 8 df = pd.read_excel('腾讯Python岗.xlsx') # 读取 9 data = df['职位类别'].value_counts() # 统计 10 11 x = data.index.tolist() # 索引列表,也就是职位列表列表 12 y = data.tolist() # 值列表,也就是统计的职位次数列表 13 14 print(x) #['技术', '产品', '设计', '战略与投资', '财务', '销售、服务与支持', '营销与公关', '法律与公共策略', '人力资源', '内容'] 15 print(y) #[1413, 80, 50, 16, 7, 5, 3, 3, 3, 2] 16 17 num = y # 数量,y轴数据 18 lab = x # 职位类别,标签数据,也就是x轴数据 19 # 数据准备好了就可以绘图了 20 pie = ( 21 Pie(init_opts=opts.InitOpts(width='1650px', height='500px', theme=ThemeType.VINTAGE)) 22 .set_global_opts( 23 title_opts=opts.TitleOpts( # 标题选项 24 title='腾讯招聘岗位饼图', 25 title_textstyle_opts=opts.TextStyleOpts(font_size=35), 26 ), 27 legend_opts=opts.LegendOpts( # 图例位置 28 pos_left='5%', 29 pos_top='10%', 30 ) 31 ) 32 .set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}: {d}")) # 数据标签设置 33 .add(series_name='', center=[280, 270], data_pair=[(j, i) for i, j in zip(num, lab)]) # 饼图 34 .add(series_name='', center=[810, 270], data_pair=[(j, i) for i, j in zip(num, lab)], radius=['40%', '70%']) # 环图 35 .add(series_name='', center=[1350, 270], data_pair=[(j, i) for i, j in zip(num, lab)], rosetype='radius') # 南丁格尔图 36 ).render('腾讯招聘岗饼图.html')
运行结果截图:
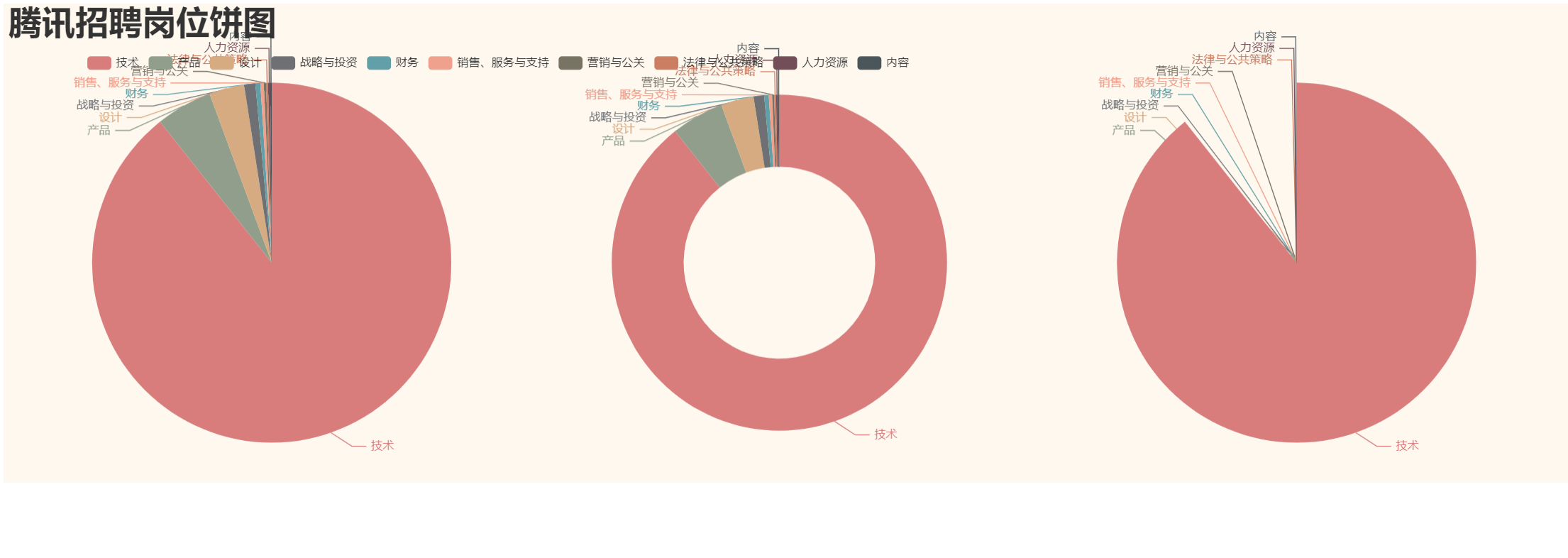
最后一个可视化是地图分布:
1 # 先读取数据 2 import pandas as pd 3 from pyecharts.globals import ThemeType 4 import pyecharts.options as opts 5 from pyecharts.charts import Bar, Pie, Map 6 7 # 读取excel表格 8 df = pd.read_excel('腾讯Python岗.xlsx') # 读取 9 data = df['城市'].value_counts() 10 11 x = data.index.tolist() #城市列表 12 y = data.tolist() #城市数量统计列表 13 print(x) 14 print(y) 15 # 打包数据 16 alldata = zip(x, y) 17 18 # 开始绘图 19 map = ( 20 Map(init_opts=opts.InitOpts(width='1080px', height='960px', theme=ThemeType.VINTAGE)) 21 .add('', [list(z) for z in zip(x, y)], 'china') # 中国地图 22 .set_global_opts( 23 title_opts=opts.TitleOpts(title="职位分布地图显示",), 24 visualmap_opts=opts.VisualMapOpts(max_=1100,is_piecewise=True), 25 ) 26 ).render('中国地图分布.shtml')
截图如下:
