由于天热,中午吃完饭后不再去逛了,感觉这段时间其实也是可以利用起来的,所以决定每天中午积累一些小的知识点。今天中午,先总结一下最近造数据用到手命令,load data。
使用这个命令的起源是因为最近要做压力测试,需要造数据,当时计划是向一张表中添加200W条数据,试了好几种方式,都感觉太慢,导致本来一件小事折腾了好几天,最终改用load data,基本上轻松搞定。所以在insert大量数据的时候,这个是比较好的选择。
先总结一下在使用load data之前,试用过的几种低效率的方式:
1)由于项目中有我要填充的数据表的DAO,所以我为了省事,直接写了个简单的入库的测试用例,循环调用那个DAO的insert方法,然而我发现非常慢,一万条数据都执行了半个小时,那么相当于2W条就需要一个小时,200W数据就需要200小时,肯定受不了。
2)然后我想到在程序中操作还有些程序启动,连接及释放的过程比较费时间,那就不在程序中做了,直接在mysql客户端做啊,然后我又想了第二个办法,先用程序生成1W条insert语句到一个sql文件中,然后在客户端中用source命令来执行,但是从结果上来看,还是很慢。
最后经同事提醒和之前的经验,决定使用load data 试试,最终在折腾了一些时间之后用起来了,看效果还是相当不错,100W条只花费了我不到2分钟的时间,采用这个方法,几个表的很快就造完了。下面正式介绍一下mysql的load data命令。
一,命令介绍
很多人估计和我一样,希望能百度到一个最全的介绍这个命令的博文,其实对于这个命令的最全介绍,mysql的官方文档上就用,如下:
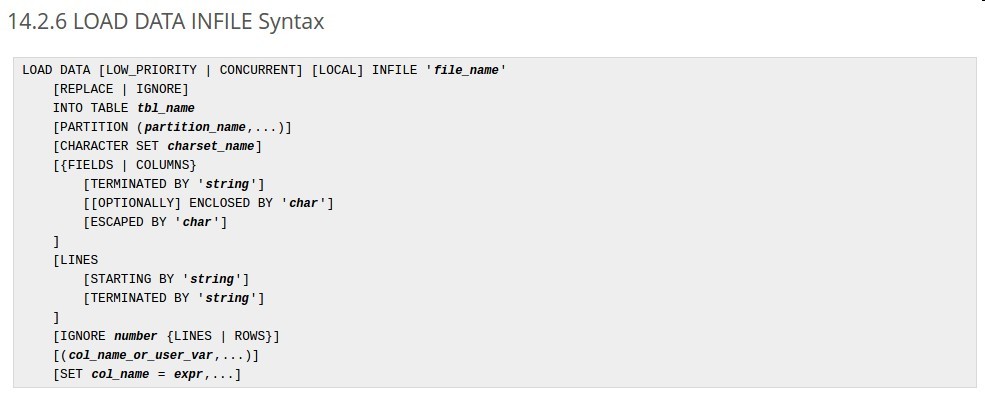
每次看这样带各种括号的命令就让人头大,但我们可以简化一下,只保留那些最必要的命令符,则以上命令可以简化如下:
load data infile 'file_name' into table tbl_name
看上去简单多了,就四个关键字,简直跟一般的命令一样,那么这个命令是什么意思呢,就是把名为file_name的文件中的数据加载到名为tbl_name的表格中去。看起来非常的好理解。
二、参数详解
知道了命令的意思,我们接下来再看一下上图中各个可选参数的意思
1)LOW_PRIORITY | CONCURRENT: 这个指定了load data操作与其操作表的线程的优化级关系,根据文档说明,这个只对那些只采用了表级别锁(如MYISAM)的引擎有影响,比如InnoDB使用的是行锁,不受这个影响,具体的来说,使用了LOW_PRIORITY,则本操作会在其它线程完成之后再操作,而CONCURRENT会和其它线程同时进行,这个对性能是有一些影响。
2)LOCAL: 这是个非常重要的关键字,指明了文件的位置,简单的说,如果指定了local,则表示文件位于客户端,如果没有,则表示文件在Server端。同时,这个关键字的使用还会影响到load data命令对于错误数据的处理方式。这两者的主要区别如下:
a) 如果是指定了local,则数据从客户端读取,文档中的说法是会在服务端的临时目录下创建一份文件的copy,但我在测试的时候并没有发现,如果file_name中是绝对路径就不用解释,如果是相对路径,则文件的位置应该是在客户端程序启动的位置,所以为了保险,一般使用绝对路径。由于涉及到数据传输,所以这种方式会相对来说慢一些。
b)如果未指定local,则文件应该是直接在服务端,这种情况下如果文件名使用的是相对路径,则又分两种情况,一种是文件名前没有相对目录,则直接是在默认数据库的data目录下查找,如果是指定了相对目录,则从server的data目录下寻找。
c)如果指定了local,则当某条数据处理有误时,系统把这个错误记录为一个warning,不会影响下一条数据的处理,因为涉及到数据传输。而如果没有指定local,则默认情况下,遇到错误后不会继续执行。
所以,如果我们是在客户端执行load data命令,一定记得加上local参数。
3)REPLACE | IGNORE: 这个指定了如果当前的数据跟表中的数据有惟一性冲突的时候,采用什么样的方式,是替换已有还是忽略当前。特别需要说明的是,当这两种方式都未指定时,如果数据来自于客户端,则重复的数据会忽略,如果来源于服务端,则命令将终止执行。
4)PARTITION: 指定具体的分区,由于之前数据库中没用到过分区,个人对这块也不熟悉,所以暂时不解释,等到了解了再补充。
5)CHARACTER SET : 指定编码集,如果文件的编码跟数据库的编码不一致,可能会出现乱码的问题。所以要注意的是,这里指定的是文件的编码集,而不是数据库的。
6)[{FIELDS | COLUMNS} [TERMINATED BY 'string'] [[OPTIONALLY] ENCLOSED BY 'char'] [ESCAPED BY 'char'] ]
这个指定了对于字段的处理方式,FIELDS和COLUMNS应该是用其一即可。TERMINATED表示字段间的分隔符,ENCLOSED BY的意思是字段值由什么符号包围,而ESCAPED表示指定转义字符。
在不指定这个参数的情况下,默认的字段分隔符是 , 默认字段值无任何值包围,默认转义字符为\.(反斜线)
7) [LINES [STARTING BY 'string'] [TERMINATED BY 'string']]:
指定每一行的起始符与终止符,默认情况下,起始符为空,终止符为' ',对于windows产生的文本文件来说,需要指定换行符为' '.
8)IGNORE number LINES: 忽略文件中的前 number 行,通常情况下,我们生成的文件可能有列名,那么要忽略的放在,这儿的值设置为1即可。需要注意的是这里是行的数量,而不是行号。
9)[(col_name_or_user_var,...)] : 有的时候我们不需要给所有的字段都填充值,这个时候就可以指定列名,以()将列名括起来,注意这里也可以是用户自定义的用户表达式。
10) [SET col_name = expr,...]: 如果在前一步中指定了用户表达式,那么相应就可以使用列名等于用户表达式的方式来指定,这个我没有用过,给出一个官方的示例如下:
LOAD DATA INFILE 'file.txt' INTO TABLE t1(column1, @var1) SET column2 = @var1/100;
三、总结:
经过自己的实际使用之后,个人觉得这个工具在导入大批量数据时还是比较实用的,虽然可选的参数过多,但是正是由于这些可选的参数,使得我们在导入数据时,可以进行很多方面的定制化。