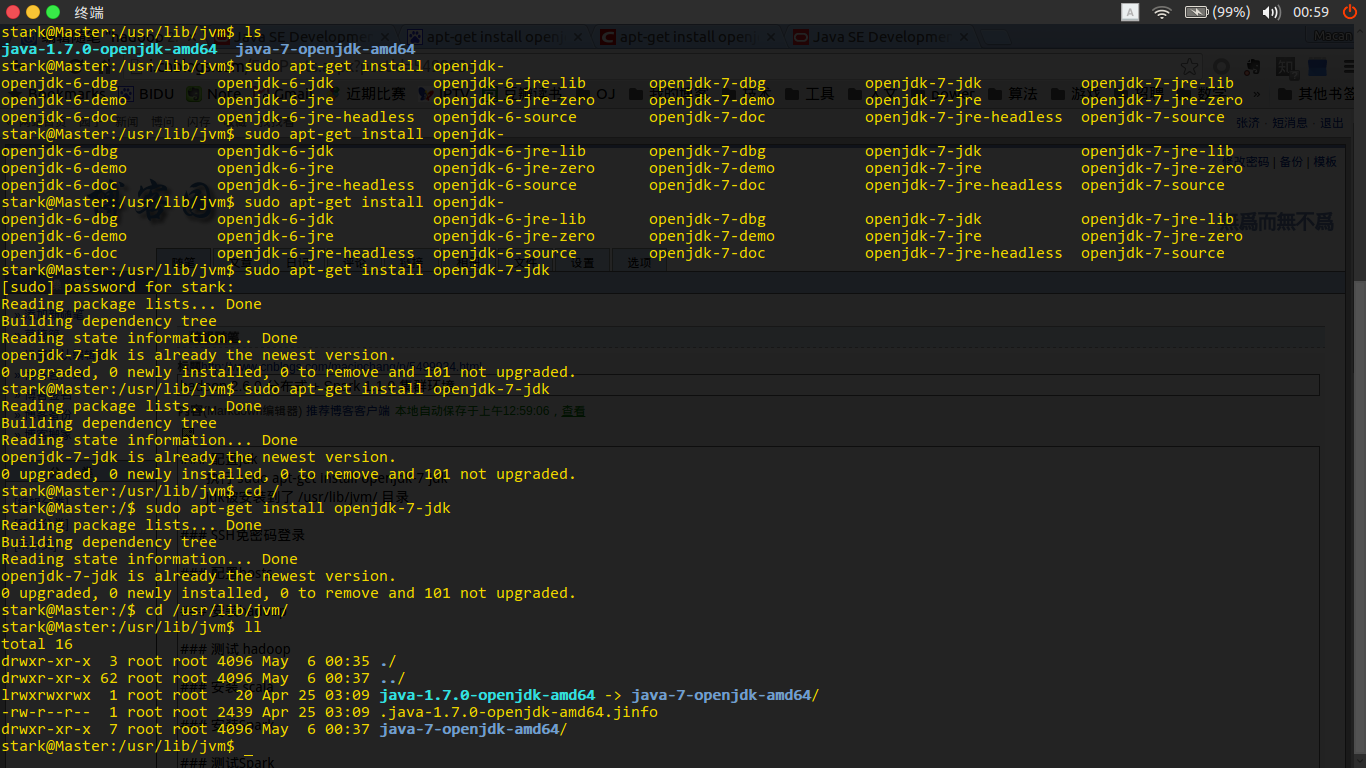
配置jdk
执行 sudo apt-get install openjdk-7-jdk
jdk被安装到了 /usr/lib/jvm/ 目录
配置hosts
使用 vim 打开 /etc/hosts, 将主节点和两个子节点的ip分别定义为 Master, Slave1, Slave2
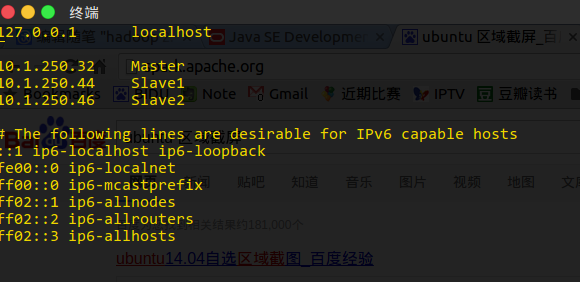
并且在 /etc/hostname中更改对应的主机名


SSH免密码登录
分别在Master, Slave1, Slave2 新建用户 stark
root@Master:~# adduser stark
在Master中, 切换到用户 stark
su stark
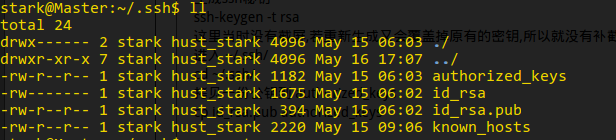
生成ssh秘钥
ssh-keygen -t rsa
这里当时没有截屏,若重新生成又会覆盖掉原有的密钥,所以就没有补截屏了.
进入 ~/.ssh/
cd ~/.ssh/
拷贝一份公钥到 authorized_keys
cp id_rsa.pub authorized_keys
分别在Slave1 和 Slave2 执行上述操作
利用 scp将Slave1和Slave2的公钥拷贝到主节点Master

将子节点的公钥追加到 authorized_keys

将authorized_keys拷贝到其他两台机器


测试SSH无密码连接

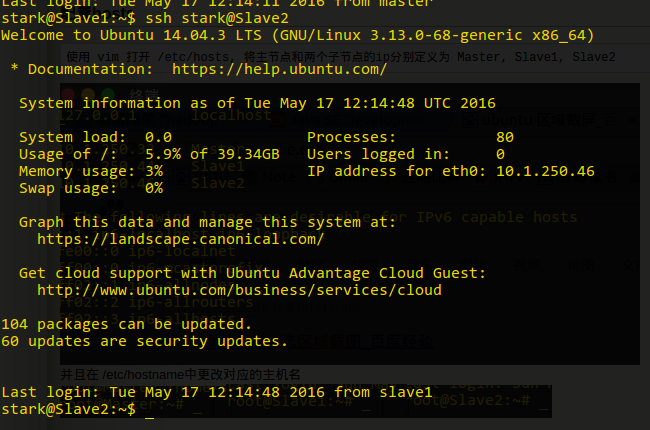
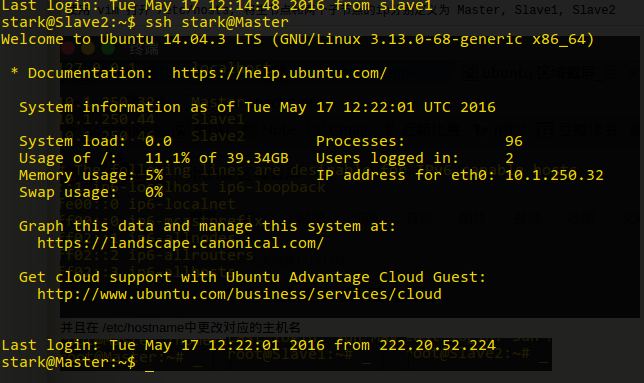
安装hadoop 2.6.0
从 http://mirror.hust.edu.cn/apache/hadoop/common/hadoop-2.6.0/hadoop-2.6.0.tar.gz 下载hadoop到服务器
解压到文件夹 /home/stark/hadoop, 并将终端切换到该目录下
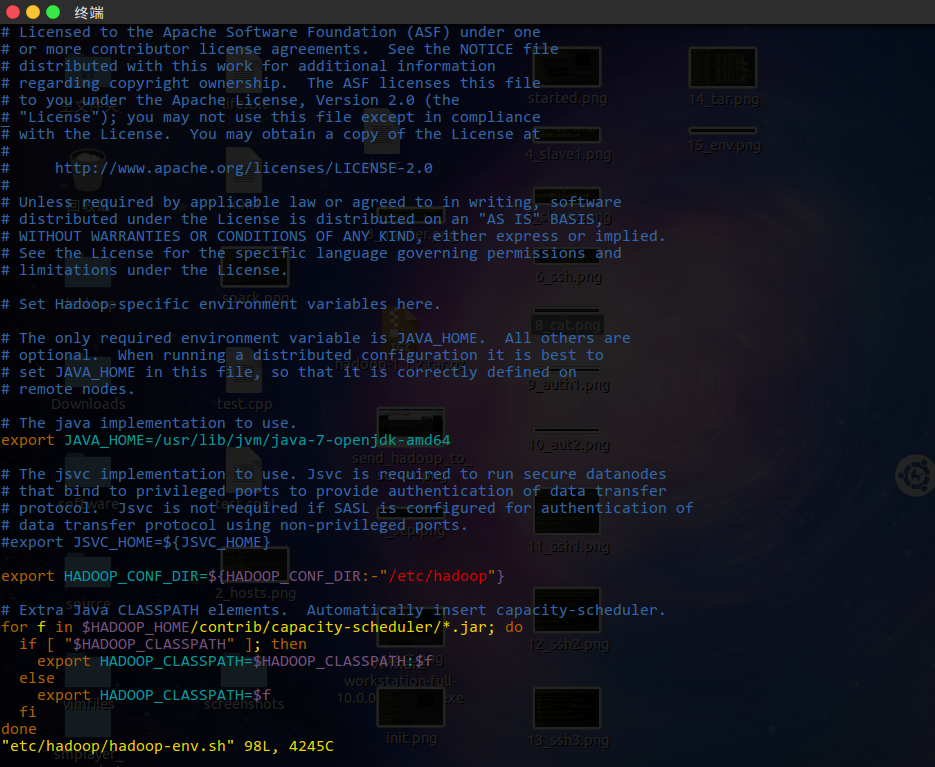
更改 etc/hadoop/hadoop-env.sh中的JAVA_HOME为实际的jdk目录

更改 etc/hadoop/core-site.xml为

更改 etc/hadoop/hdfs-site.xml为

更改 etc/hadoop/mapred-site.xml 为
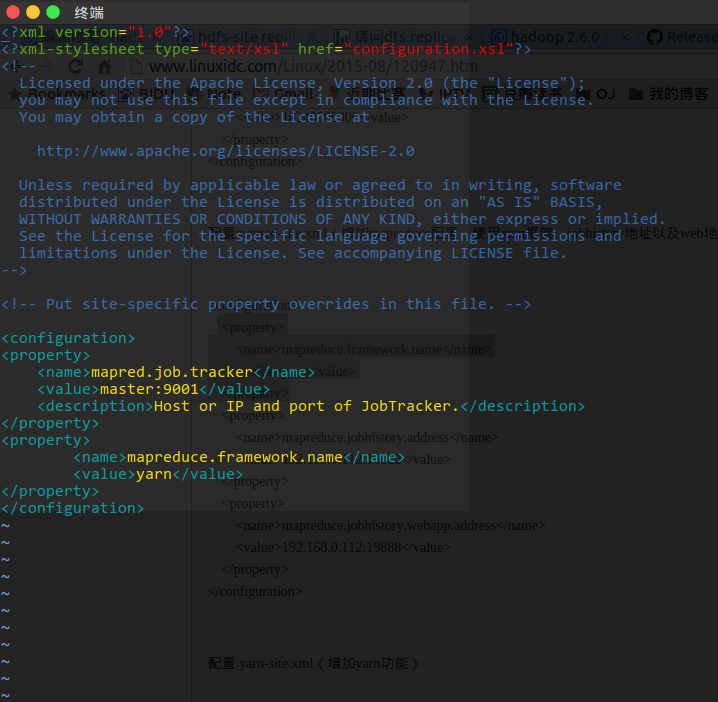
将配置好的hadoop拷贝到其他两个节点


测试 hadoop
格式化节点
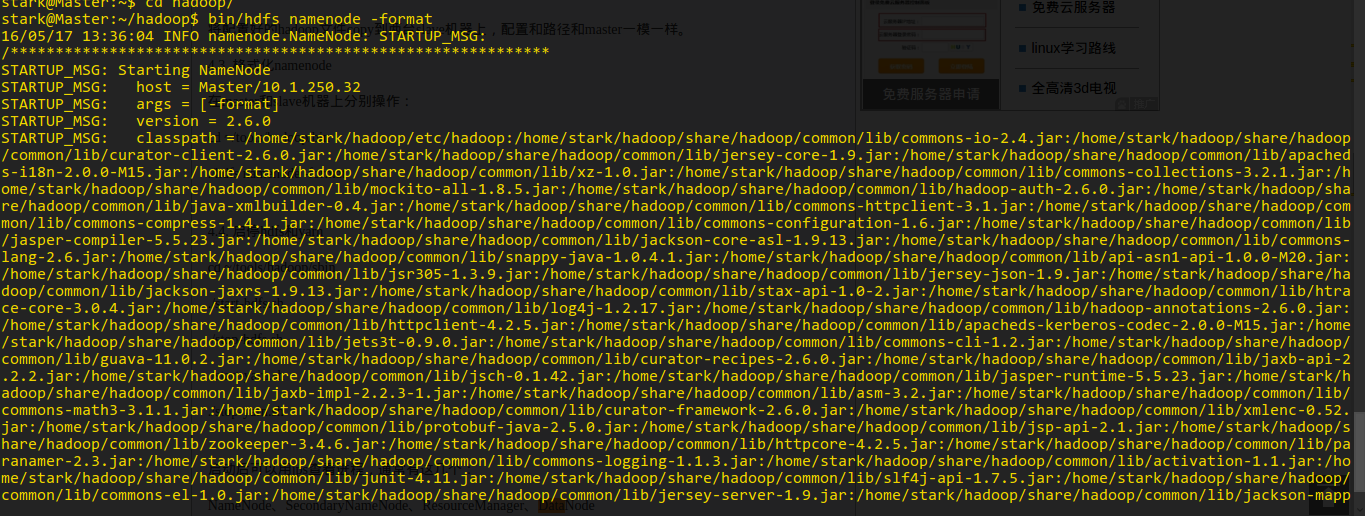
启动 hdfs 和 yarn


查看状态

运行 wordcount
在hdfs中创建目录 input
将file拷贝到input中
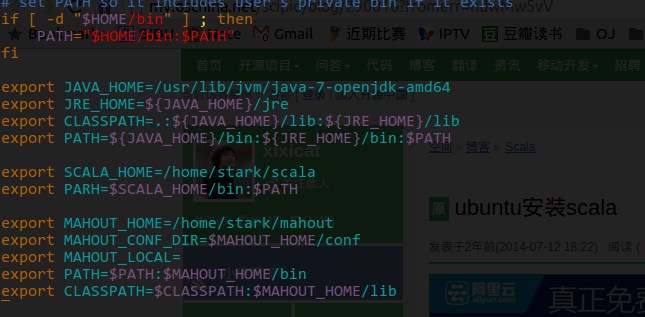
安装 scala

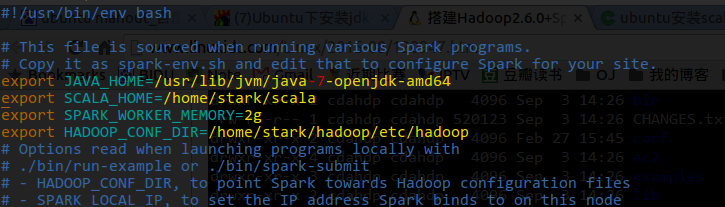
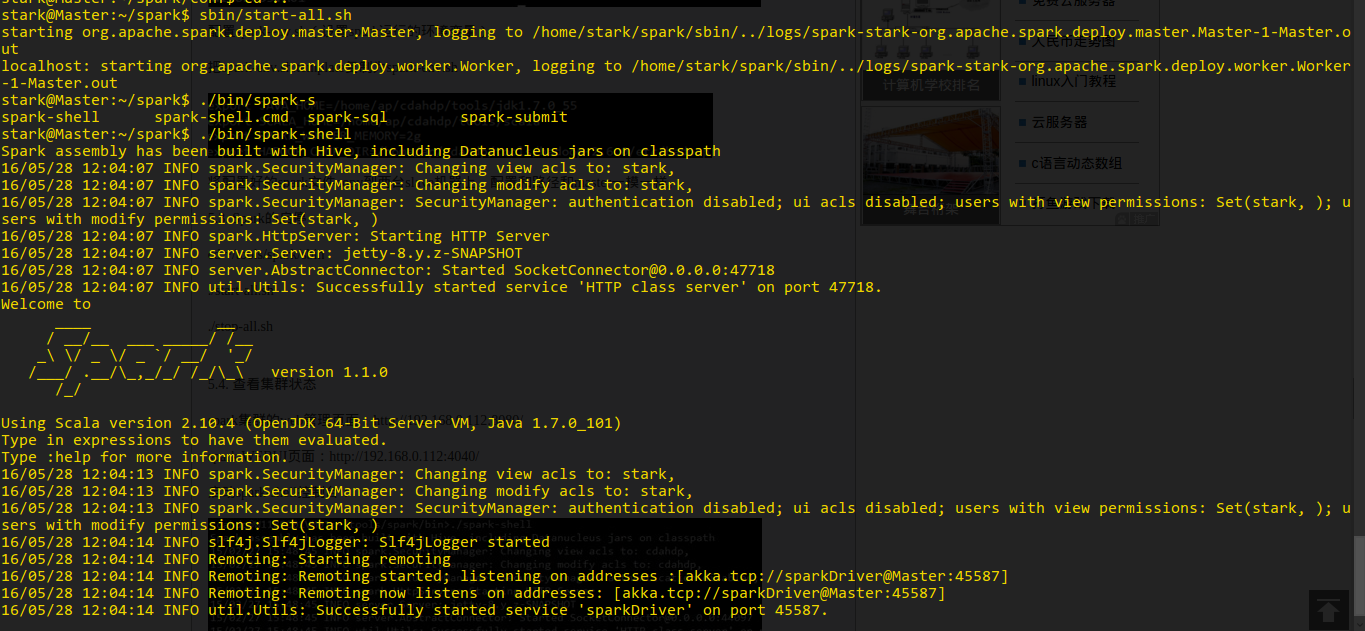
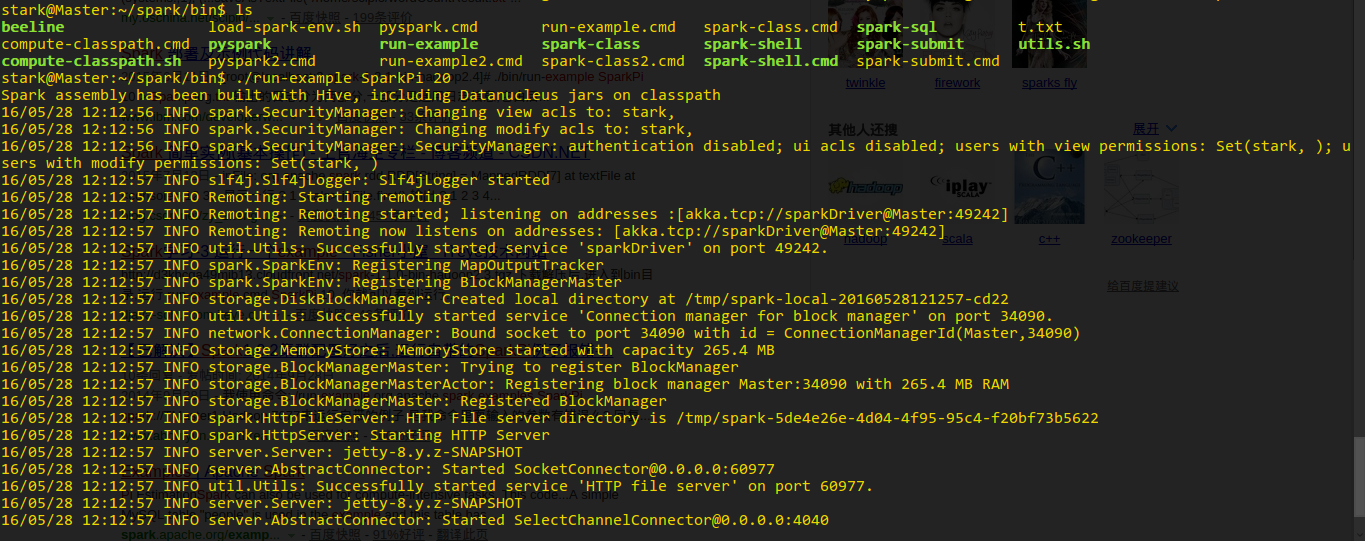
安装Spark

安装 mahout

