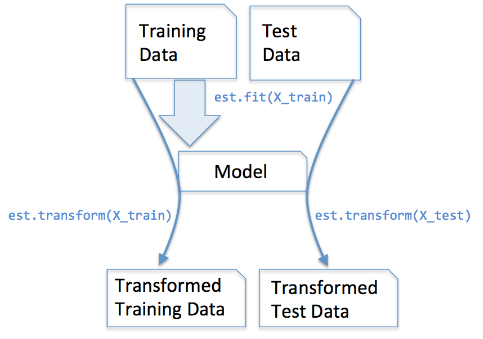
1. 数据预处理
2. 特征提取
DictVectorizer
参考:https://blog.csdn.net/qq_36847641/article/details/78279309
提取前的字典结构
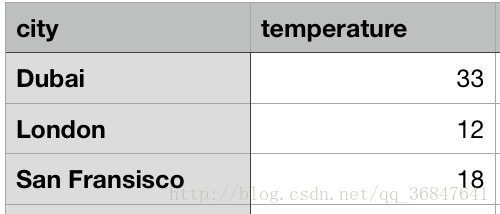
提取后的数组结构

3. 测试集和训练集划分
train_test_split 函数用于将矩阵随机划分为训练子集和测试子集,并返回划分好的训练集测试集样本和训练集测试集标签
X_train,X_test, y_train, y_test =cross_validation.train_test_split(train_data,train_target,test_size=0.3, random_state=0)
参考:https://www.cnblogs.com/bonelee/p/8036024.html
各种回归 https://blog.csdn.net/yeoman92/article/details/75051848
4. 数据集
datasets.load_*?
datasets.load_boston #波士顿房价数据集
datasets.load_breast_cancer #乳腺癌数据集
datasets.load_diabetes #糖尿病数据集
datasets.load_digits #手写体数字数据集
datasets.load_files
datasets.load_iris #鸢尾花数据集
datasets.load_lfw_pairs
datasets.load_lfw_people
datasets.load_linnerud #体能训练数据集
datasets.load_mlcomp
datasets.load_sample_image
datasets.load_sample_images
datasets.load_svmlight_file
datasets.load_svmlight_files