主要理解几点:
RPN训练
# AnchorTargetCreator就是将20000多个候选的Anchor选出256个Anchor进行分类和回归,选择过程如下:
# 对于每一个GTbbox,选择和它交并比最大的一个Anchor作为正样本。
# 对于剩下的Anchor,从中选择和任意一个GTbbox交并比超过0.7
# 的Anchor作为正样本,正样本数目不超过128个。随机选择和GT
# bbox交并比小于0.3的Anchor作为负样本,负样本和正样本的总数为256
计算分类损失使用的是交叉熵损失,而计算回归损失则使用了SmoothL1Loss,
在计算回归损失的时候只计算正样本(前景)的损失,不计算负样本的损失。
ROIhead训练
(1)ProposalCreator:
# RPN在自身训练的时候还会提供ROIs给FasterRCNN的ROIHead作为训练样本。
# RPN生成ROIs的过程就是ProposalCreator,具体流程如下:
# 对于每张图片,利用它的特征图,计算(大约20000个)Anchor属于前景的概率以及对应的位置参数。
# 选取概率较大的12000个Anchor。
# 利用回归的位置参数修正这12000个Anchor的位置,获得ROIs。
# 利用非极大值抑制,选出概率最大的2000个ROIs。
(2)ProposalTargetCreator
ROIs给出了2000个候选框,分别对应了不同大小的Anchor。我们首先需要利用ProposalTargetCreator挑选出128个sample_rois,
然后使用了ROI Pooling将这些不同尺寸的区域全部Pooling到同一个尺度(7 × 7 7 imes 77×7)上;
我们再来看一下ProposalTargetCreator具体是如何选择128个ROIs进行训练的?过程如下:
- RoIs和GT box的IOU大于0.5的,选择一些如32个。
- RoIs和gt_bboxes的IoU小于等于0(或者0.1)的选择一些(比如 128-32=96个)作为负样本。
同时为了方便训练,对选择出的128个RoIs的gt_roi_loc进行标准化处理(减均值除以标准差)。
RPN不断训练,然后不断更新ROIs,roihead的输入就不断更新。。。。。。。
步骤:
1.build_head()函数: 构建CNN基层网络
图像被缩放16倍
2.build_rpn()函数: 在feature map上生成box的坐标和判断是否有物体
generate_anchors:生成9个坐标框(思想:先定义一个基准框(0,0,16,16),因为经过多层卷积池化之后,
feature map上一点的感受野对应到原始图像就会是一个区域,这里设置的是16,
也就是feature map上一点对应到原图的大小为16x16的区域根据基准框生成一个中心坐标长宽为(
(16,16,7.5,7.5)的框,基本面积16*16 = 256,根据ratios(0.5,1,2),得到3个面积的框[512,256,128]
然后开根号得到3种长[23,16,11]*[8,16,32],再乘以ratios得到宽[12,16,22]*[8,16,32],9组长宽计算出来9个anchor根据公式
x_ctr - 0.5 * (ws - 1),
y_ctr - 0.5 * (hs - 1),
x_ctr + 0.5 * (ws - 1),
y_ctr + 0.5 * (hs - 1)
计算anchors(中心(7.5,7.5))
[[-3.5 2 18.5 13][0 0 15 15][2.5 -3 12.5 18]]
,这3个面积分别生成3种长宽,在给定3种scales(8,16,32),总共生成以下9种
array([[ -83., -39., 100., 56.],
[-175., -87., 192., 104.],
[-359., -183., 376., 200.],
[ -55., -55., 72., 72.],
[-119., -119., 136., 136.],
[-247., -247., 264., 264.],
[ -35., -79., 52., 96.],
[ -79., -167., 96., 184.],
[-167., -343., 184., 360.]])
其中坐标是相对于中心的偏移。
generate_anchors_pre:根据特征图的坐标对应到原图上面去,也就是原图中每隔16个像素会有9个anchors
anchor_shape =[WxHx9, 4]
3.build_proposas()函数: 对box进行判断,挑选合适的box,其中进行iou和nms操作,这里没有训练参数的生成。
① 去除掉超过1000*600这原图的边界的anchor box
② 如果anchor box与ground truth的IoU值最大,标记为正样本,label=1
③ 如果anchor box与ground truth的IoU>0.7,标记为正样本,label=1
④ 如果anchor box与ground truth的IoU<0.3,标记为负样本,label=0
剩下的既不是正样本也不是负样本,不用于最终训练,label=-1
除了对anchor box进行标记外,另一件事情就是计算anchor box与ground truth之间的偏移量
令:ground truth:标定的框也对应一个中心点位置坐标x*,y*和宽高w*,h*
anchor box: 中心点位置坐标x_a,y_a和宽高w_a,h_a
所以,偏移量:
△x=(x*-x_a)/w_a △y=(y*-y_a)/h_a
△w=log(w*/w_a) △h=log(h*/h_a)
通过ground truth box与预测的anchor box之间的差异来进行学习,从而是RPN网络中的权重能够学习到预测box的能力
loss理解:
SmoothL1Loss:
(1)clsscore层:用于分类,输出离散型概率分布:
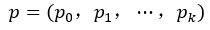
p由k+1类的全连接层利用softmax计算得出
loss_cls层评估分类损失函数。由真实分类u对应的概率决定:

(2) bbox_prdict层:用于调整候选区域位置,输出bounding box回归的位移,输出4*K维数组t,表示分别属于k类时,应该平移缩放的参数
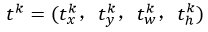
loss_bbox评估检测框定位的损失函数。比较真实分类对应的预测平移缩放参数和真实平移缩放参数的差别
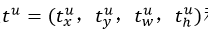

其中,smooth L1损失函数为:
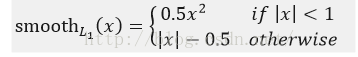
注意:其中x为预测值与真实值之间的差值

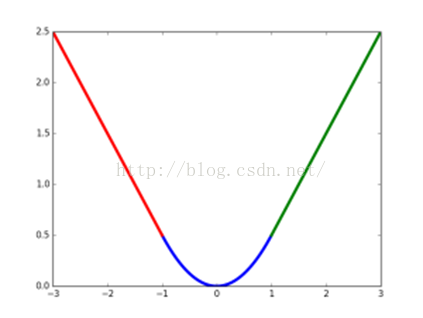
smoothL1损失函数曲线
最后总损失为(两者加权和,如果分类为背景则不考虑定位损失):

规定u=0为背景类(也就是负标签),那么艾弗森括号指数函数[u≥1]表示背景候选区域即负样本不参与回归损失,不需要对候选区域进行回归操作。λ控制分类损失和回归损失的平衡。Fast R-CNN论文中,所有实验λ=1。
Faster R-CNN损失函数
遵循multi-task loss定义,最小化目标函数,FasterR-CNN中对一个图像的函数定义为:

其中:

#4.build_predictions():这里进行最后的类别分类和box框回归之前会有一个rois网络层,该网络会把所有的feature map进行尺寸resize到固定的尺寸,之后进行拉伸。这里有两路输出,一个是box的坐标,另一个是类别的分数。