一、Spark 集群安装
(1)准备:
- 三台机器。eg:hadoop0、hadoop1、hadoop2
- 每台机器都安装有Java(scala运行是需要java环境的)
(2)Spark安装包上传到一台服务器,比如hadoop0,修改spark-env.sh以及slaves配置文件(在conf目录下)
- spark-env.sh 添加如下配置:
export JAVA_HOME=/home/vagrant/share/jdk1.8.0_211
export SPARK_MASTER_HOST=hadoop0
# 以下默认就是7077
#export SPARK_MASTER_PORT=7077
- slaves 添加节点名称:
hadoop1
hadoop2
(3)将文件从hadoop0拷贝到hadoop1以及hadoop2;以下是文件拷贝shell命令↓
for i in {1..2}; do scp -r /home/vagrant/share/spark-2.4.5-bin-hadoop2.7/ hadoop$i:/home/vagrant/share/; done
(4)启动,进入spark sbin目录:start-all.sh。jps 可看到 hadoop0 有 master进程,hadoop1和hadoop2有worker进程
(5)web访问master:http://192.168.11.10:8080/
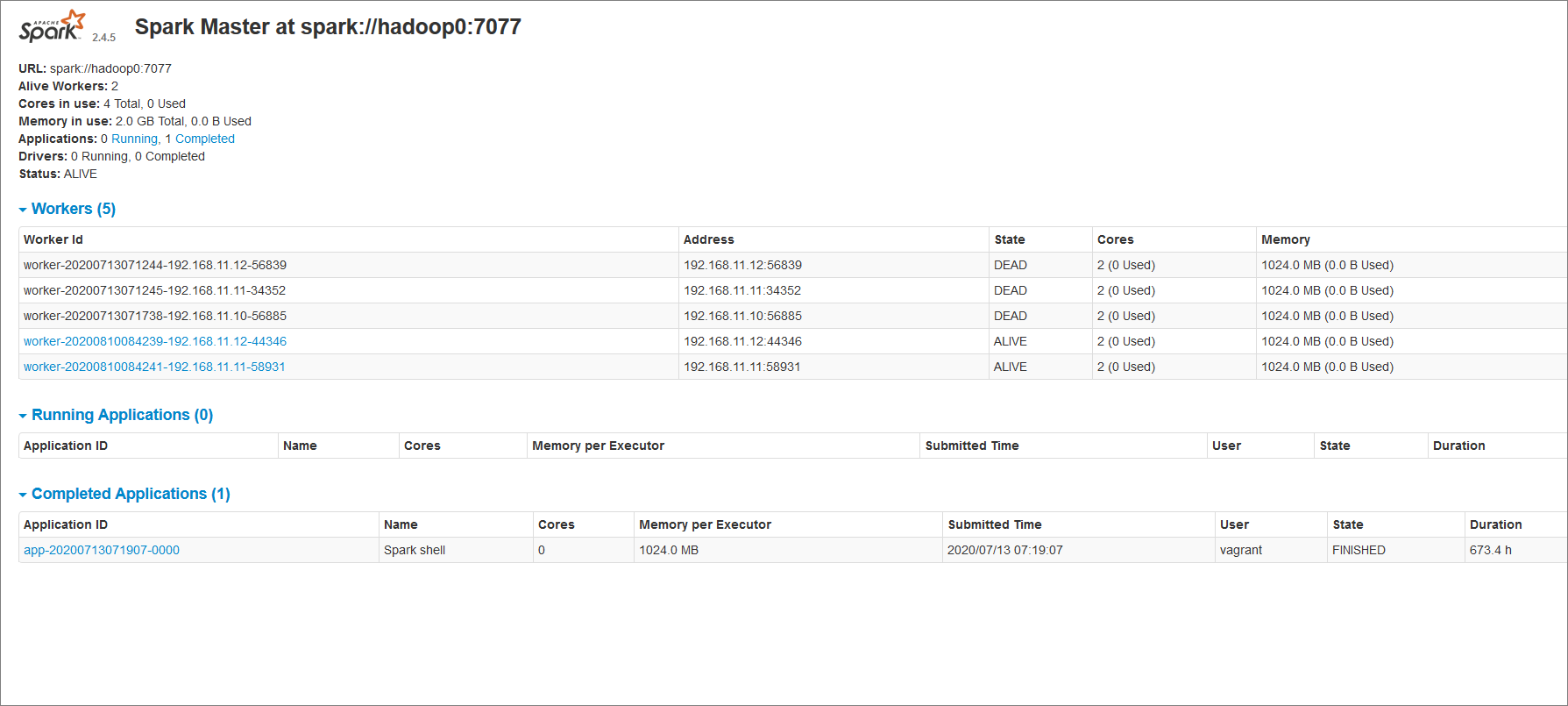
两个worker节点和一个master节点。此集群只有一个master节点,如果master挂了,集群则不可用,因此拉入zookeeper进行分布式节点管理。↓
二、Spark集群高可用安装
(1)安装zookeeper集群
(2)修改spark配置:修改 spark-env.sh 如下:
添加配置:export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=hadoop0:2181,hadoop1:2181,hadoop2:2181 -Dspark.deploy.zookeeper.dir=/spark"
删除配置:export SPARK_MASTER_HOST=hadoop0
最后将配置同步到其他spark节点
(3)启动集群:先启动zookeeper,然后在一台机器上启动spark:start-all.sh,最后再在备用spark节点启动备用master节点:start-master.sh.注意启动顺序,否则会启动失败
(4)检验是否成功:将master节点停掉,看其是否会启用备用master,
三、Spark实践
(1)提交任务到spark集群
使用spark原有样例:bin/spark-submit --master spark://hadoop1:7077 --class org.apache.spark.examples.SparkPi examples/jars/spark-examples_2.11-2.4.5.jar 100
(2)使用spark-shell
启动spark-shell:
- ./bin/spark-shell(没指定master运行模式是本地模式)
- ./bin/spark-shell --master spark://hadoop1:7077,hadoop0:7077
spark-shell也是一个任务,所以在集群中每个节点都会启动一个CoarseGrainedExecutorBackend进程,用来执行任务
四、Spark常用算子实践
(0)初始化获得RDD:
- val data = Array(1,2,3,4,5)
val distData = sc.parallelize(data)
- val peopleDF = spark.sparkContext.textFile("examples/src/main/resources/people.txt")
(1)map(func):对单条数据进行操作,比如一个分区有1000条数据,则会执行1000次map,不会导致OOM。eg:
输入:distData.map(_ * 2).collect()
输出:Array[Int] = Array(2, 4, 6, 8, 10)
(2)mapPartitions(func) :对单个分区的数据进行操作,比如一个分区有1000条数据,则只会执行一次map,每个分区执行一次map,容易造成OOM。eg:
输入:distData.mapPartitions(x => x.map(_*2)).collect()
输出:Array[Int] = Array(2, 4, 6, 8, 10)
(3)mapPartitionsWithIndex(func):比mapPartitions多了一个index参数,即可以知道使用了的具体的分区编号
输入:distData.mapPartitionsWithIndex((index,x) => x.map((index,_))).collect()
输出:Array[(Int, Int)] = Array((1,1), (2,2), (3,3), (4,4), (5,5))
(4)flatMap(func):类似于map,但是每一个输入元素可以被映射为0或多个输出元素
输入:distData.flatMap(1 to _).collect()
输出:Array[Int] = Array(1, 1, 2, 1, 2, 3, 1, 2, 3, 4, 1, 2, 3, 4, 5)
(5)glom():将每一个分区形成一个数组,形成新的RDD类型时RDD[Array[T]]
输入:val glomRdd = sc.parallelize(1 to 16,4) glomRdd.glom().collect()
输出:Array[Array[Int]] = Array(Array(1, 2, 3, 4), Array(5, 6, 7, 8), Array(9, 10, 11, 12), Array(13, 14, 15, 16))
(6)groupBy(func):分组
输入:distData.groupBy(_%2).collect()
输出:Array[(Int, Iterable[Int])] = Array((0,CompactBuffer(4, 2)), (1,CompactBuffer(3, 5, 1)))
(7)filter(func):过滤
输入:distData.filter(_%2 == 0).collect()
输出:Array[Int] = Array(2, 4)
(8)sample(withReplacement, fraction, seed) :随机抽样。withReplacement为是否有放回抽样;fraction为抽取的结果比例(大体比例);seed为随机种子,默认为0~Long.maxvalue之间的一个整数。
输入:distData.sample(false,0.5,90).collect()
输出:Array[Int] = Array(1, 3)
(9)distinct([numTasks])):去重;numTasks为并行任务去重,默认8,可自定义。
输入:distData.distinct(1).collect()
输出:Array[Int] = Array(4, 1, 3, 5, 2)
(10)coalesce(numPartitions):缩减分区数;可通过参数shuffle = false/true是否进行shuffle
输入:glomRdd.coalesce(3).partitions.size
输出:3
(11)repartition(numPartitions):重新分区;其底层调用的也是coalesce,但是会进行shuffle即shuffle = true
(11-1)repartitionAndSortWithinPartitions(partitioner):重新分区,并对重新分区里头的数据进行排序。这个比先repartition,然后对每个分区的数据进行sortBy效率高,因为它会在shuffle的过程中进行排序,边shuffle边排序,这也是官方推荐使用的算子
(12)sortBy(func,[ascending], [numTasks]):排序;默认升序
(13)pipe(command, [envVars]):管道,针对每个分区,都执行一个shell脚本,返回输出的RDD
样例:rdd.pipe("/opt/module/spark/pipe.sh").collect()
(14)union(otherDataset):两个RDD并集
输入:glomRdd.union(distData).collect()
输出:Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 1, 2, 3, 4, 5)
(15)subtract (otherDataset):去除两个RDD中相同的元素,不同的RDD将保留下来
输入:glomRdd.subtract(distData).collect()
输出:Array[Int] = Array(16, 8, 12, 9, 13, 6, 10, 14, 7, 11, 15)
(16)intersection(otherDataset):取两个RDD交集
(17)cartesian(otherDataset):取两个RDD笛卡尔积
(18)zip(otherDataset):将两个RDD组合成Key/Value形式的RDD,这里默认两个RDD的partition数量以及元素数量都相同,否则会抛出异常。
输入:val rdd1 = sc.parallelize(Array(1,2,3),3)
val rdd2 = sc.parallelize(Array("a","b","c"),3)
rdd1.zip(rdd2).collect
输出:Array[(Int, String)] = Array((1,a), (2,b), (3,c))
(19)partitionBy:对pairRDD进行分区操作,如果原有的partionRDD和现有的partionRDD是一致的话就不进行分区, 否则会生成ShuffleRDD,即会产生shuffle过程
输入:val rdd = sc.parallelize(Array((1,"aaa"),(2,"bbb"),(3,"ccc"),(4,"ddd")),4)
var rdd2 = rdd.partitionBy(new org.apache.spark.HashPartitioner(2))
rdd2.partitions.size
输出:2
(20)reduceByKey(func, [numTasks]):在一个(K,V)的RDD上调用,返回一个(K,V)的RDD,使用指定的reduce函数,将相同key的值聚合到一起,reduce任务的个数可以通过第二个可选的参数来设置
输入:val rdd = sc.parallelize(List(("female",1),("male",5),("female",5),("male",2)))
rdd.reduceByKey((x,y) => x+y).collect()
输出:Array[(String, Int)] = Array((female,6), (male,7))
(21)groupByKey:根据key分组;reduceByKey在shuffle之前有combine操作即会先进行本地聚合,可减少网络开销以及磁盘开销,而groupByKey没有combine操作;一般reduceByKey性能好点
(22)aggregateByKey(zeroValue:U,[partitioner: Partitioner]) (seqOp: (U, V) => U,combOp: (U, U) => U):对每个分区的数据进行分组,然后进行相应的func操作
输入:val rdd = sc.parallelize(List(("a",3),("a",2),("c",4),("b",3),("c",6),("c",8)),2)
查看分区情况:rdd.glom.collect()
Array[Array[(String, Int)]] = Array(Array((a,3), (a,2), (c,4)), Array((b,3), (c,6), (c,8)))
测试算子:rdd.aggregateByKey(0)(math.max(_,_),_+_).collect() // 对每个分区的数据进行分组,然后取每个分区中相同分组中的最大值相加
输出:Array[(String, Int)] = Array((b,3), (a,3), (c,12))
(23)foldByKey(zeroValue: V)(func: (V, V):跟aggregateByKey类似,但是少了个seqOp参数
测试算子:rdd.foldByKey(0)(_+_).collect() // 对每个分区的数据进行分组,然后取每个分区中相同分组中的值相加
输出:Array[(String, Int)] = Array((b,3), (a,5), (c,18))
(24)sortByKey([ascending], [numTasks]):排序
(25)mapValues(func):遍历所有value,遍历过程中可对value进行相关操作
输入:val rdd3 = sc.parallelize(Array((1,"a"),(1,"d"),(2,"b"),(3,"c")))
rdd3.mapValues(_+"|||").collect()
输出:Array[(Int, String)] = Array((1,a|||), (1,d|||), (2,b|||), (3,c|||))
(26)join(otherDataset, [numTasks]):将两个RDD中相同key的值聚合到一起形成新的元组
输入:val rdd = sc.parallelize(Array((1,"a"),(2,"b"),(4,"c")))
val rdd1 = sc.parallelize(Array((1,4),(2,5),(3,6)))
rdd.join(rdd1).collect()
输出:Array[(Int, (String, Int))] = Array((1,(a,4)), (2,(b,5)))
(27)cogroup(otherDataset, [numTasks]):将两个RDD按照相同的key集合到一个迭代器
输入:rdd.cogroup(rdd1).collect()
输出:Array[(Int, (Iterable[String], Iterable[Int]))] = Array((1,(CompactBuffer(a),CompactBuffer(4))), (2,(CompactBuffer(b),CompactBuffer(5))), (3,(CompactBuffer(),CompactBuffer(6))), (4,(CompactBuffer(c),CompactBuffer())))
(29)reduce(func):执行算子;跟map相似,它是对每条数据进行操作的
输入:val c = sc.parallelize(1 to 10)
c.reduce((x, y) => x + y)
输出:Int = 55
(30)reduceByKey(func):根据key进行分组,然后计算每个分组里头的数据
输入:val a = sc.parallelize(List((1,2),(3,4),(3,6)))
a.reduceByKey((x,y) => x + y).collect
输出:Array[(Int, Int)] = Array((1,2), (3,10))
(31)collect():以数组的形式返回所有数据
(32)count():返回RDD中元素的个数
(33)first():返回RDD中第一个元素
(34)take(N):返回前N个元素组成的数组
(35)takeOrdered(N):返回排序后的前N个元素的数组,默认升序
(36)aggregate(zeroValue: U)(seqOp: (U, T) ⇒ U, combOp: (U, U) ⇒ U):对每个分区的数据进行seoOp操作,然后将每个分区操作之后的结果进行combOp操作
输入:var rdd1 = sc.makeRDD(1 to 10,2)
rdd.aggregate(0)(_+_,_+_)
输出:Int = 55
(37)countByKey:对相同的key进行个数统计
输入:val a = sc.parallelize(List((1,2),(3,4),(3,6)))
a.countByKey
输出:scala.collection.Map[Int,Long] = Map(1 -> 1, 3 -> 2)
(38)saveAsTextFile(path):将RDD存储为本地文件
(39)foreach(func):迭代处理
输入:val c = sc.parallelize(List("cat", "dog", "tiger", "lion"), 2)
c.foreach(x => println(x + "s are yummy"))
输出:控制台是没有输出的,因为这个是在executor节点执行的,所以需要到executor的stout里头看输出
(40)foreachPartition(func):对每个分区的数据进行迭代处理;区别在于它为每个分区进行处理,所以在将数据写入数据库中时,可以为每个分区创建一个数据库连接而不用每条数据创建一个连接
输入:c.foreachPartition(patition => patition.foreach(x => println(x + "s are yummy")))
输出:控制台是没有输出的,因为这个是在executor节点执行的,所以需要到executor的stout里头看输出
(41)combileByKey: