结论:
如果多行在列中具有相同的值ORDER BY,则服务器可以自由以任何顺序返回这些行,并且根据整体执行计划,这样做的方式可能有所不同。换句话说,这些行的排序顺序相对于无序列是不确定的。
验证:
建表语句:
CREATE TABLE `test_limit` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(45) DEFAULT NULL, `create_time` datetime DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=51 DEFAULT CHARSET=utf8mb4
现在想根据创建时间升序查询test_limit表,并且分页查询,每页3条,那很容易写出sql为:
select * from test_limit order by create_time limit 0,3
执行查询(问题复现):
1、查询第1页数据时:
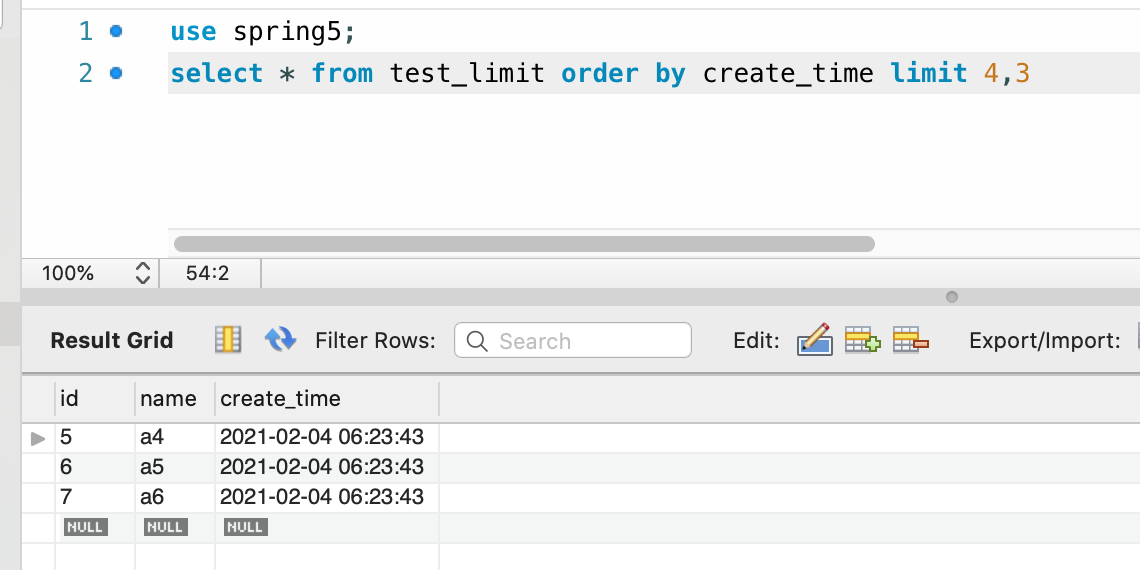
2、查询第6页数据时:
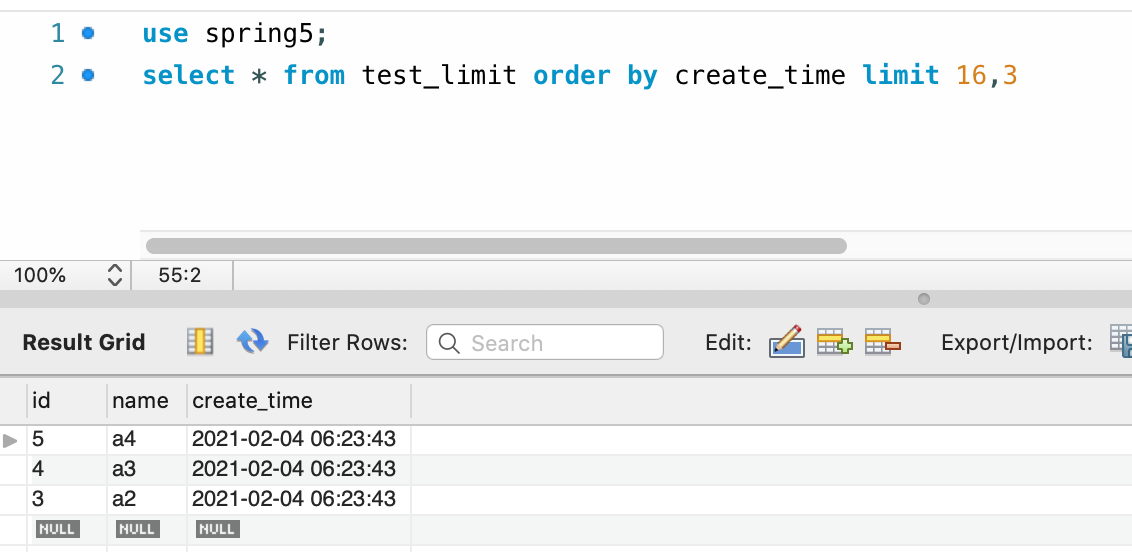
test_limit表共有50条数据,有17页数据,但是实际查询过程中第2页与第6页竟然出现了相同的数据。
上面的实际执行结果已经证明现实与想像往往是有差距的,实际SQL执行时并不是按照上述方式执行的。这里其实是Mysql会对Limit做优化,具体优化方式见官方文档:
这个是5.7版本的说明,提取几个问题直接相关的点做下说明。
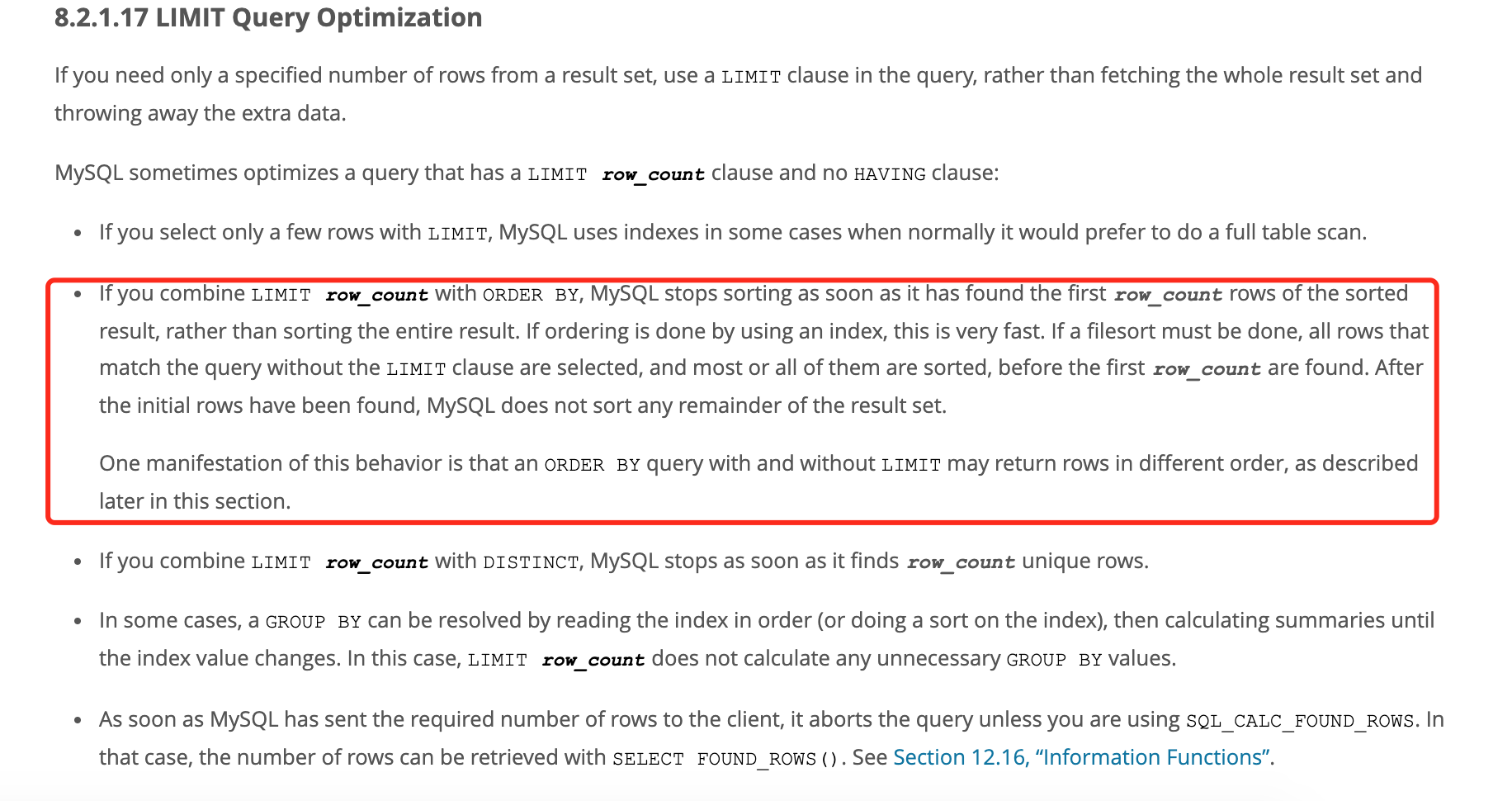
翻译:

这里我们查看下对应SQL的执行计划:
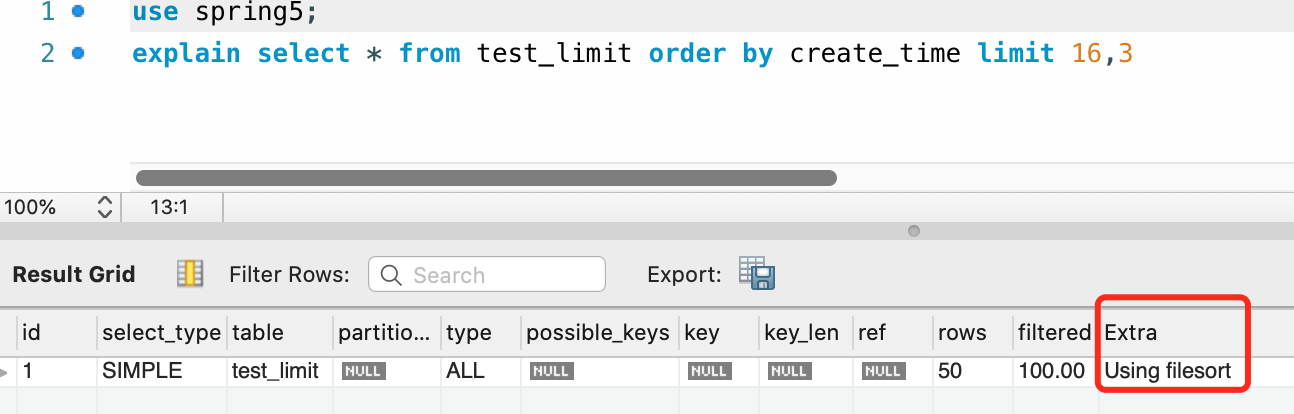
可以确认是用的文件排序,表确实也没有加额外的索引。所以我们可以确定这个SQL执行时是会找到limit要求的行后立马返回查询结果的。
不过就算它立马返回,为什么分页会不准呢?
官方文档里面做了如下说明:

翻译:

基于这个我们就基本知道为什么分页会不准了,因为我们排序的字段是create_time,正好又有几个相同的值的行,在实际执行时返回结果对应的行的顺序是不确定的。对应上面的情况,第2页返回的name为a4的数据行,可能正好排在前面,而第6页查询时name为a4的数据行正好排在后面,所以第6页的数据又出现了。
解决:
官方给出的解决方案(推荐):

翻译:

方案二(个人版):
加索引
*对于区分度不高的字段并不推荐,例如add_time,但是update_time还凑合

效果验证:

执行计划:
