一.搭建大数据开发环境
我电脑的开发环境为(windows系统下 hadoop-2.7.1+spark-2.2.0+scala-2.11.12+jdk-8u261+Apache-hive-2.1.1+MYSQL 5.6.35+IDEA 2019)
1.官网下载hadoop-2.7.1.tar.gz、scala-2.11.12.msi、spark-2.2.0-bin-hadoop2.7.tgz、jdk-8u261-windows-x64.exe、apache-hive-2.1.1-bin.tar.gz、mysql-5.6.35安装包
2.安装jdk1.8,详细步骤自行百度(注意环境变量配置正确)
3.安装scala2.11.12(版本我选择的是2.11,更高级的12版本可能会出现问题)
4.安装hadoop2.7.1,适用于开发环境的本地模式(查看hadoop安装目录bin文件夹下是否存在hadoop.dll和winutils.exe),配置本地模式所需的hadcoop-env.cmd、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml配置文件(注意hadoop还可以搭建伪分布式和完全分布式)
5.解压hadoop-common-2.2.0-bin-master.zip、spark-2.2.0-bin-hadoop2.7.tgz、apache-hive-2.1.1-bin.tar.gz,免安装的,配置相关的配置文件即可,注意hive初始化元数据库命令 hive --service metastore时可能会报java.sql.SQLSyntaxErrorException: You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near '[CHARACTER SET charset_name] [COLLATE collation_name] NULL,`VIEW_ORIGINAL_T' at line 12错误,查看本地安装的mysql版本、hive-site.xml配置的驱动以及hive下lib文件夹中的mysql-connector-java jar包版本是否相匹配
二.准备的资料
数据源pmt.json以及ip解析工具库ip2region.db
三.idea搭建maven工程
1.新建maven工程

2.在工程中新建模块,工程结构如下
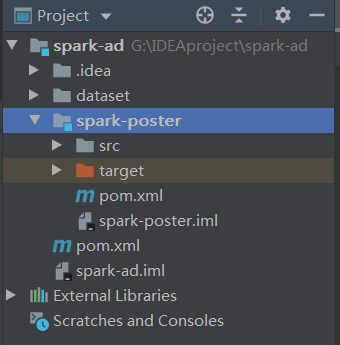
3.编写spark=poster模块的pom文件
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <parent> <artifactId>spark-ad</artifactId> <groupId>com.ly</groupId> <version>1.0-SNAPSHOT</version> </parent> <modelVersion>4.0.0</modelVersion> <artifactId>spark-poster</artifactId> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <scala.version>2.11.8</scala.version> <scala.binary.version>2.11</scala.binary.version> <spark.version>2.2.0</spark.version> <hadoop.version>2.7.1</hadoop.version> <mysql.version>8.0.21</mysql.version> </properties> <dependencies> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-library</artifactId> <version>${scala.version}</version> </dependency> <!--Spark Core 依赖--> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_${scala.binary.version}</artifactId> <version>${spark.version}</version> </dependency> <!--Spark SQL 依赖--> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_${scala.binary.version}</artifactId> <version>${spark.version}</version> </dependency> <!--Spark SQL与Hive集成 依赖--> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-hive_${scala.binary.version}</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>${hadoop.version}</version> </dependency> <!--Mysql 连接驱动--> <!-- https://mvnrepository.com/artifact/mysql/mysql-connector-java --> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>${mysql.version}</version> </dependency> <!--解析IP --> <dependency> <groupId>org.lionsoul</groupId> <artifactId>ip2region</artifactId> <version>1.7.2</version> </dependency> <dependency> <groupId>com.typesafe</groupId> <artifactId>config</artifactId> <version>1.2.1</version> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.scala-tools</groupId> <artifactId>maven-scala-plugin</artifactId> <version>2.15.2</version> <executions> <execution> <goals> <goal>compile</goal> <goal>testCompile</goal> </goals> </execution> </executions> </plugin> <plugin> <artifactId>maven-compiler-plugin</artifactId> <version>3.6.0</version> <configuration> <source>1.8</source> <target>1.8</target> </configuration> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-surefire-plugin</artifactId> <version>2.19</version> <configuration> <skip>true</skip> </configuration> </plugin> </plugins> </build> </project>
4.创建scala目录
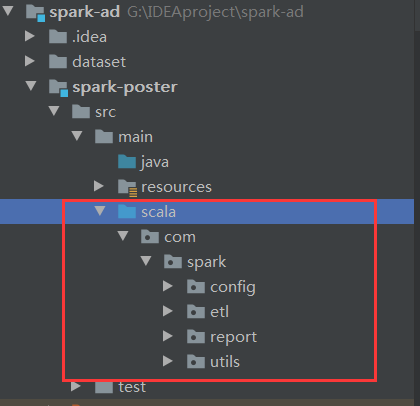
5.编写配置文件
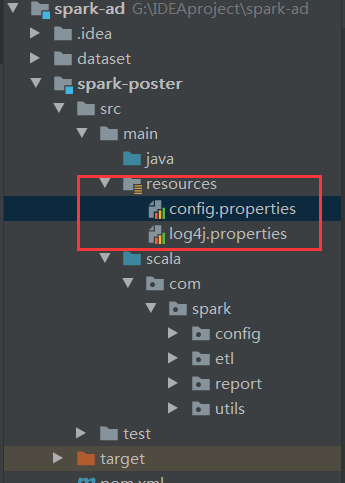
6.具体业务开发
............
demo地址 git@github.com:white66/spark-ad.git
我只是学习一下业务开发的步骤思路,首先就是开发环境的搭建,这是一切的基础。数据源pmt.json里面的json数据是自己伪造的,在本地开发时,相关文件可以放在本地文件系统,在实际生产环境中,这些文件都是放在hdfs中的。从数据源文件读取数据后先要进行ETL处理保存数据至hive分区表中,这样做是对数据进行清洗并按照预先定义好的数据仓库模型将数据加载到数据仓库中。接着是具体业务开发,从hive分区表中读取etl后的数据通过DSL/SQL来进行数据分析处理,最后将数据保存至MYSQL、redis、elasticsearch等数据库中