这里只介绍三种最常用的方式
1.HBase shell
HBase的命令行工具是最简单的接口,主要用于HBase管理
首先启动HBase

帮助
hbase(main):001:0> help
查看HBase服务器状态
hbase(main):001:0> status

查询HBse版本
hbase(main):002:0> version

ddl操作
1.创建一个member表
hbase(main):013:0> create 'table1','tab1_id','tab1_add','tab1_info'

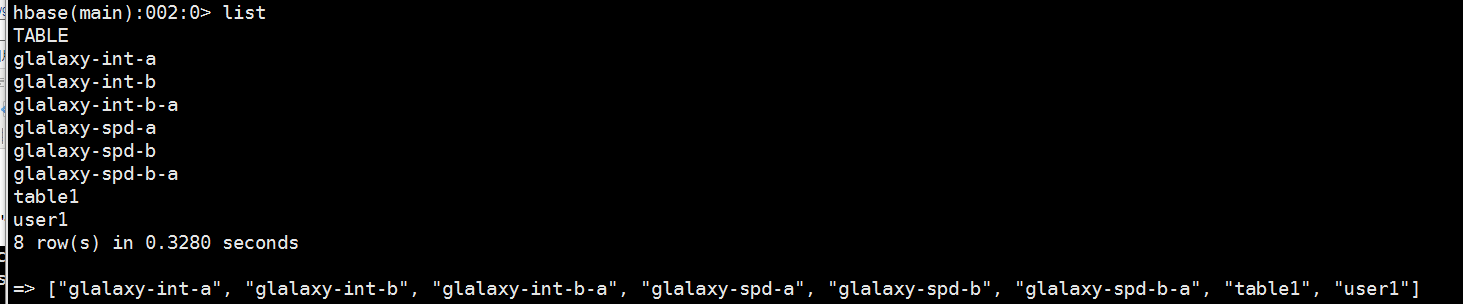
2.查看所有的表
hbase(main):006:0> list
3.查看表结构
hbase(main):007:0> describe 'member'

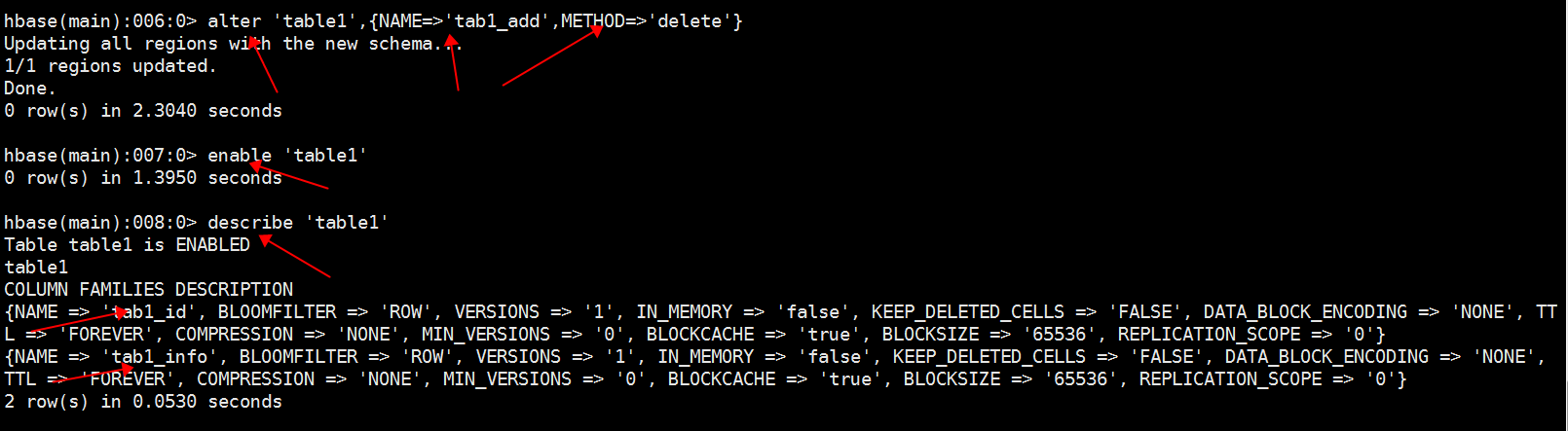
4.删除一个列簇

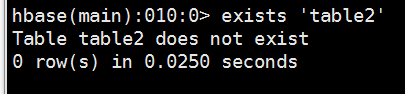
5、查看表是否存在
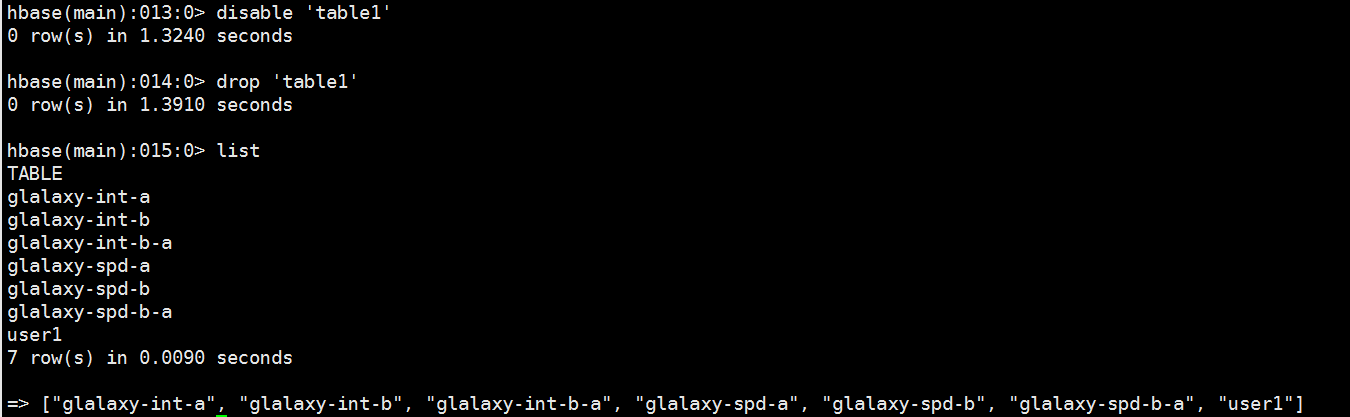
6、判断表是否为"enable"

7、删除一个表
dml操作
1、创建member表
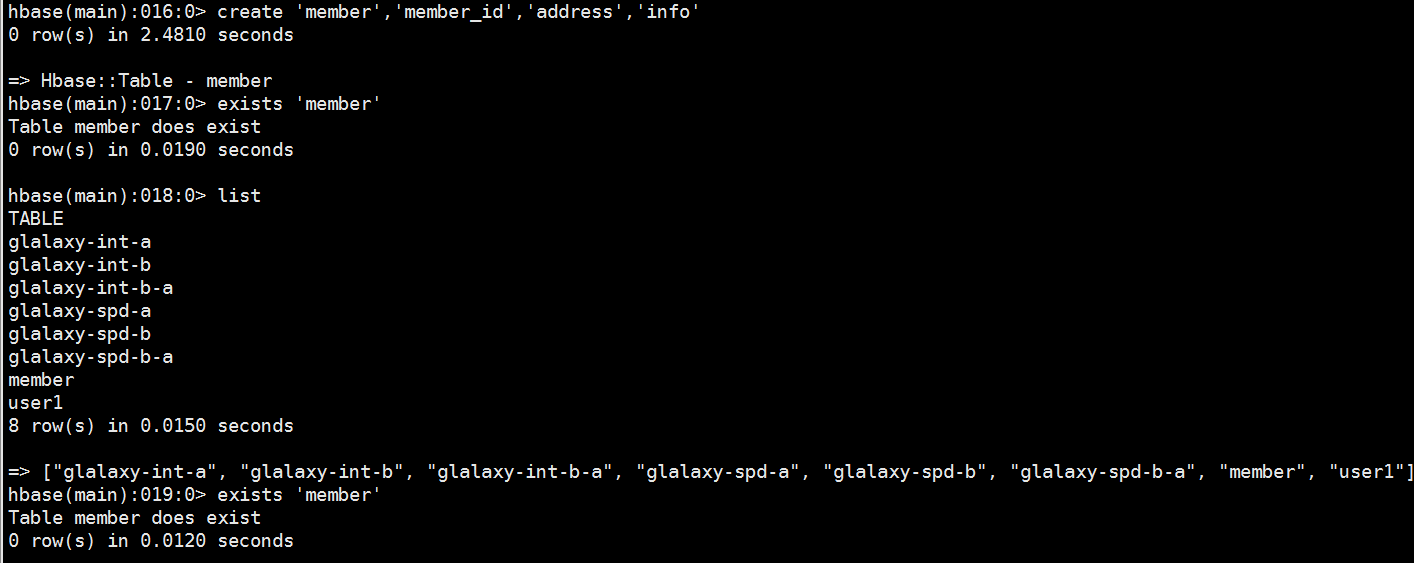
删除一个列簇(一般不超过两个列簇)
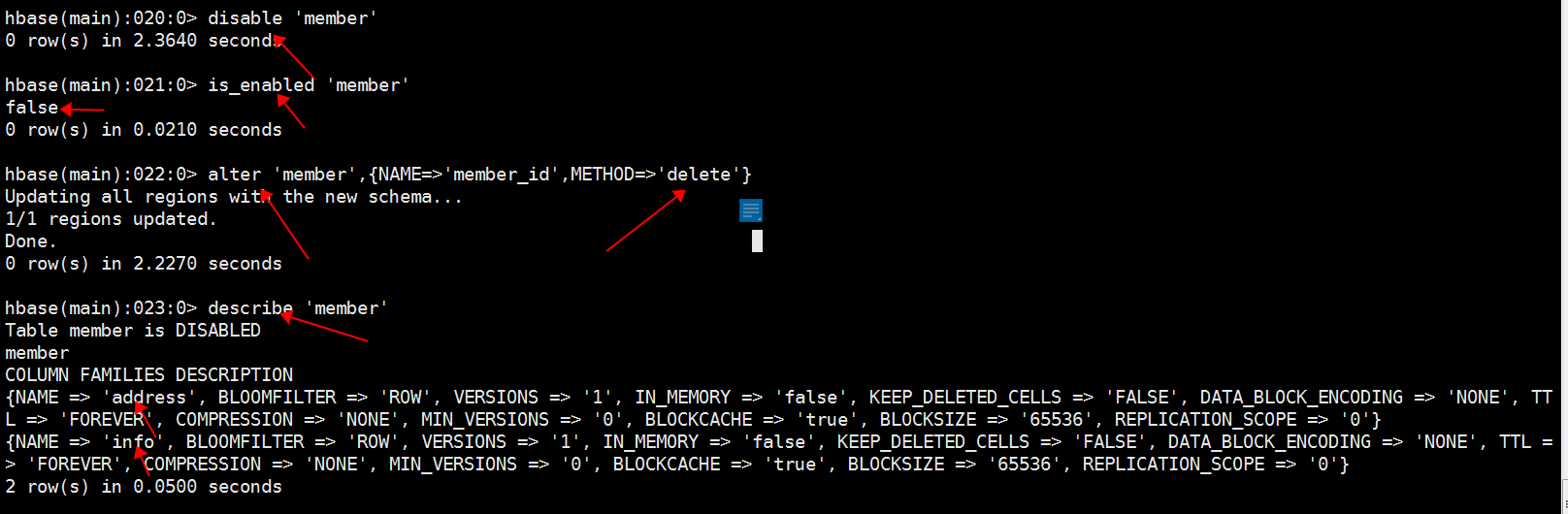

2、往member表插入数据

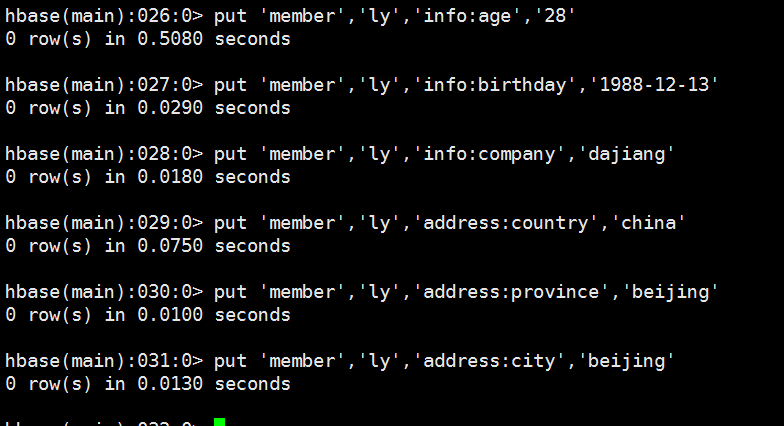
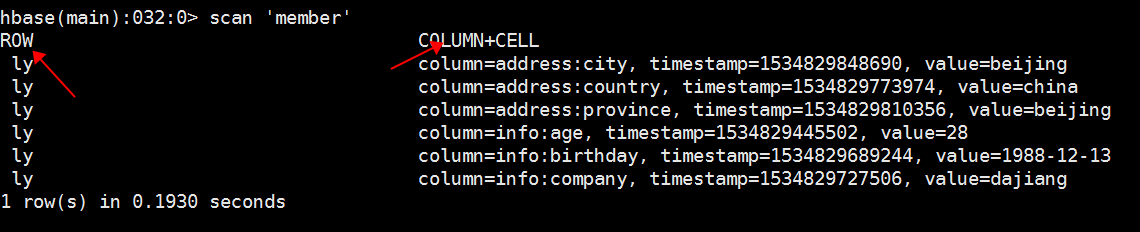
3、扫描查看数据
4、获取数据
获取一个rowkey的所有数据
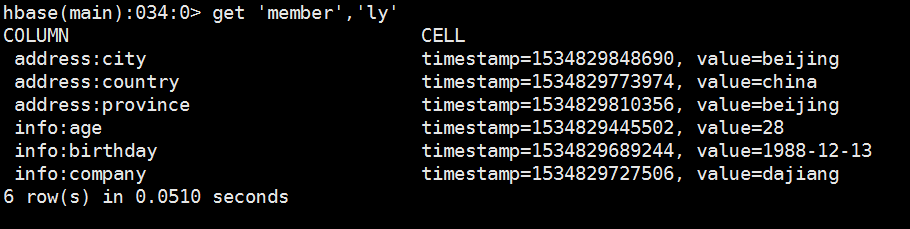
获取一个rowkey,一个列簇的所有数据

获取一个rowkey,一个列簇中一个列的所有数据

5、更新数据
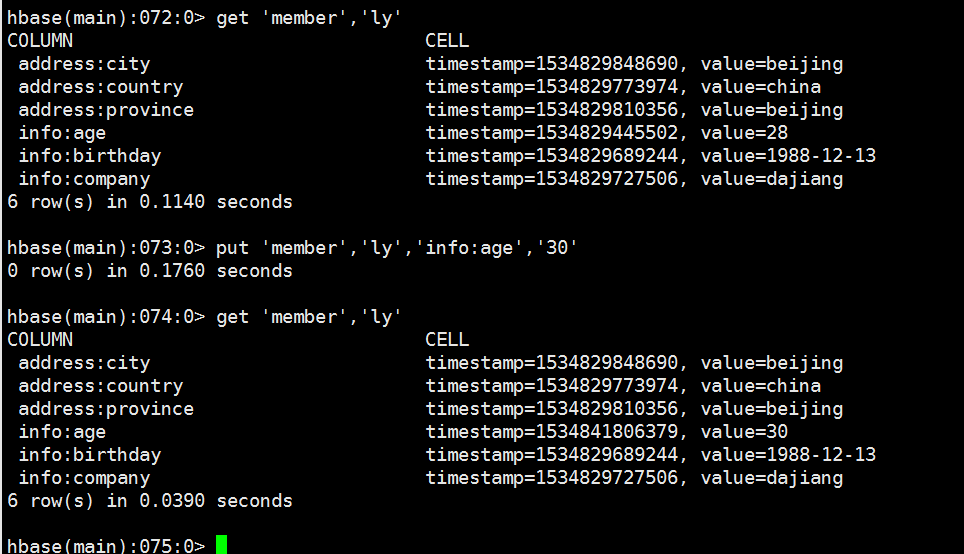
6、删除列簇中其中一列
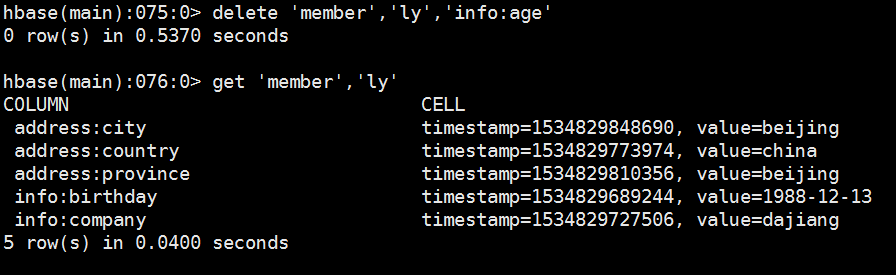
7、统计表中总的行数
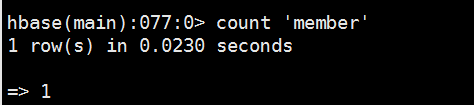
8、清空表中数据
2.java API
最常规且最高效的访问方式
1 import java.io.IOException; 2 3 import org.apache.hadoop.conf.Configuration; 4 import org.apache.hadoop.hbase.HBaseConfiguration; 5 import org.apache.hadoop.hbase.HColumnDescriptor; 6 import org.apache.hadoop.hbase.HTableDescriptor; 7 import org.apache.hadoop.hbase.KeyValue; 8 import org.apache.hadoop.hbase.MasterNotRunningException; 9 import org.apache.hadoop.hbase.ZooKeeperConnectionException; 10 import org.apache.hadoop.hbase.client.Delete; 11 import org.apache.hadoop.hbase.client.Get; 12 import org.apache.hadoop.hbase.client.HBaseAdmin; 13 import org.apache.hadoop.hbase.client.HTable; 14 import org.apache.hadoop.hbase.client.Put; 15 import org.apache.hadoop.hbase.client.Result; 16 import org.apache.hadoop.hbase.client.ResultScanner; 17 import org.apache.hadoop.hbase.client.Scan; 18 import org.apache.hadoop.hbase.util.Bytes; 19 20 public class HbaseTest { 21 public static Configuration conf; 22 static{ 23 conf = HBaseConfiguration.create();//第一步 24 conf.set("hbase.zookeeper.quorum", "header-2,core-1,core-2"); 25 conf.set("hbase.zookeeper.property.clientPort", "2181"); 26 conf.set("hbase.master", "header-1:60000"); 27 } 28 29 public static void main(String[] args) throws IOException{ 30 //createTable("member"); 31 //insertDataByPut("member"); 32 //QueryByGet("member"); 33 QueryByScan("member"); 34 //DeleteData("member"); 35 } 36 37 38 39 /** 40 * 创建表 通过HBaseAdmin对象操作 41 * 42 * @param tablename 43 * @throws IOException 44 * @throws ZooKeeperConnectionException 45 * @throws MasterNotRunningException 46 * 47 */ 48 public static void createTable(String tableName) throws MasterNotRunningException, ZooKeeperConnectionException, IOException { 49 //创建HBaseAdmin对象 50 HBaseAdmin hBaseAdmin = new HBaseAdmin(conf); 51 //判断表是否存在,若存在就删除 52 if(hBaseAdmin.tableExists(tableName)){ 53 hBaseAdmin.disableTable(tableName); 54 hBaseAdmin.deleteTable(tableName); 55 } 56 HTableDescriptor tableDescriptor = new HTableDescriptor(tableName); 57 //添加Family 58 tableDescriptor.addFamily(new HColumnDescriptor("info")); 59 tableDescriptor.addFamily(new HColumnDescriptor("address")); 60 //创建表 61 hBaseAdmin.createTable(tableDescriptor); 62 //释放资源 63 hBaseAdmin.close(); 64 } 65 66 /** 67 * 68 * @param tableName 69 * @throws IOException 70 */ 71 @SuppressWarnings("deprecation") 72 public static void insertDataByPut(String tableName) throws IOException { 73 //第二步 获取句柄,传入静态配置和表名称 74 HTable table = new HTable(conf, tableName); 75 76 //添加rowkey,添加数据, 通过getBytes方法将string类型都转化为字节流 77 Put put1 = new Put(getBytes("djt")); 78 put1.add(getBytes("address"), getBytes("country"), getBytes("china")); 79 put1.add(getBytes("address"), getBytes("province"), getBytes("beijing")); 80 put1.add(getBytes("address"), getBytes("city"), getBytes("beijing")); 81 82 put1.add(getBytes("info"), getBytes("age"), getBytes("28")); 83 put1.add(getBytes("info"), getBytes("birthdy"), getBytes("1998-12-23")); 84 put1.add(getBytes("info"), getBytes("company"), getBytes("dajiang")); 85 86 //第三步 87 table.put(put1); 88 89 //释放资源 90 table.close(); 91 } 92 93 /** 94 * 查询一条记录 95 * @param tableName 96 * @throws IOException 97 */ 98 public static void QueryByGet(String tableName) throws IOException { 99 //第二步 100 HTable table = new HTable(conf, tableName); 101 //根据rowkey查询 102 Get get = new Get(getBytes("djt")); 103 Result r = table.get(get); 104 System.out.println("获得到rowkey:" + new String(r.getRow())); 105 for(KeyValue keyvalue : r.raw()){ 106 System.out.println("列簇:" + new String(keyvalue.getFamily()) 107 + "====列:" + new String(keyvalue.getQualifier()) 108 + "====值:" + new String(keyvalue.getValue())); 109 } 110 table.close(); 111 } 112 113 114 115 /** 116 * 扫描 117 * @param tableName 118 * @throws IOException 119 */ 120 public static void QueryByScan(String tableName) throws IOException { 121 // 第二步 122 HTable table = new HTable(conf, tableName); 123 Scan scan = new Scan(); 124 //指定需要扫描的列簇,列.如果不指定就是全表扫描 125 scan.addColumn(getBytes("info"), getBytes("company")); 126 ResultScanner scanner = table.getScanner(scan); 127 for(Result r : scanner){ 128 System.out.println("获得到rowkey:" + new String(r.getRow())); 129 for(KeyValue kv : r.raw()){ 130 System.out.println("列簇:" + new String(kv.getFamily()) 131 + "====列:" + new String(kv.getQualifier()) 132 + "====值 :" + new String(kv.getValue())); 133 } 134 } 135 //释放资源 136 scanner.close(); 137 table.close(); 138 } 139 140 141 142 /** 143 * 删除一条数据 144 * @param tableName 145 * @throws IOException 146 */ 147 public static void DeleteData(String tableName) throws IOException { 148 // 第二步 149 HTable table = new HTable(conf, tableName); 150 151 Delete delete = new Delete(getBytes("djt")); 152 delete.addColumn(getBytes("info"), getBytes("age")); 153 154 table.delete(delete); 155 //释放资源 156 table.close(); 157 } 158 159 /** 160 * 转换byte数组(string类型都转化为字节流) 161 */ 162 public static byte[] getBytes(String str){ 163 if(str == null) 164 str = ""; 165 return Bytes.toBytes(str); 166 } 167 }
3.MapReduce
直接使用MapReduce作业处理HBase数据
import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.HColumnDescriptor; import org.apache.hadoop.hbase.HTableDescriptor; import org.apache.hadoop.hbase.client.HBaseAdmin; import org.apache.hadoop.hbase.client.Put; import org.apache.hadoop.hbase.io.ImmutableBytesWritable; import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil; import org.apache.hadoop.hbase.mapreduce.TableReducer; import org.apache.hadoop.hbase.util.Bytes; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; /** * 将hdfs里面的数据导入hbase * @author Administrator * */ public class MapReduceWriteHbaseDriver { public static class WordCountMapperHbase extends Mapper<Object, Text, ImmutableBytesWritable, IntWritable>{ private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(Object key, Text value, Context context) throws IOException, InterruptedException{ StringTokenizer itr = new StringTokenizer(value.toString()); while(itr.hasMoreTokens()){ word.set(itr.nextToken()); //输出到hbase的key类型为ImmutableBytesWritable context.write(new ImmutableBytesWritable(Bytes.toBytes(word.toString())), one); } } } public static class WordCountReducerHbase extends TableReducer<ImmutableBytesWritable, IntWritable, ImmutableBytesWritable>{ private IntWritable result = new IntWritable(); public void reduce(ImmutableBytesWritable key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException{ int sum = 0; for(IntWritable val : values){ sum += val.get(); } //put实例化 key代表主键,每个单词存一行 Put put = new Put(key.get()); //三个参数分别为:列簇content 列count 列值为词频 put.add(Bytes.toBytes("content"), Bytes.toBytes("count"), Bytes.toBytes(String.valueOf(sum))); context.write(key, put); } } public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException{ String tableName = "wordcount";//hbase数据库表名 也可以通过命令行传入表名args Configuration conf = HBaseConfiguration.create();//实例化Configuration conf.set("hbase.zookeeper.quorum", "header-2,core-1,core-2"); conf.set("hbase.zookeeper.property.clientPort", "2181"); conf.set("hbase.master", "header-1"); //如果表已经存在就先删除 HBaseAdmin admin = new HBaseAdmin(conf); if(admin.tableExists(tableName)){ admin.disableTable(tableName); admin.deleteTable(tableName); } HTableDescriptor htd = new HTableDescriptor(tableName);//指定表名 HColumnDescriptor hcd = new HColumnDescriptor("content");//指定列簇名 htd.addFamily(hcd);//创建列簇 admin.createTable(htd);//创建表 Job job = new Job(conf, "import from hdfs to hbase"); job.setJarByClass(MapReduceWriteHbaseDriver.class); job.setMapperClass(WordCountMapperHbase.class); //设置插入hbase时的相关操作 TableMapReduceUtil.initTableReducerJob(tableName, WordCountReducerHbase.class, job, null, null, null, null, false); //map输出 job.setMapOutputKeyClass(ImmutableBytesWritable.class); job.setMapOutputValueClass(IntWritable.class); //reduce输出 job.setOutputKeyClass(ImmutableBytesWritable.class); job.setOutputValueClass(Put.class); //读取数据 FileInputFormat.addInputPaths(job, "hdfs://header-1:9000/user/test.txt"); System.out.println(job.waitForCompletion(true) ? 0 : 1); } }
import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.client.Result; import org.apache.hadoop.hbase.client.Scan; import org.apache.hadoop.hbase.io.ImmutableBytesWritable; import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil; import org.apache.hadoop.hbase.mapreduce.TableMapper; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /** * 读取hbse数据存入HDFS * @author Administrator * */ public class MapReduceReaderHbaseDriver { public static class WordCountHBaseMapper extends TableMapper<Text, Text>{ protected void map(ImmutableBytesWritable key, Result values,Context context) throws IOException, InterruptedException{ StringBuffer sb = new StringBuffer(""); //获取列簇content下面的值 for(java.util.Map.Entry<byte[], byte[]> value : values.getFamilyMap("content".getBytes()).entrySet()){ String str = new String(value.getValue()); if(str != null){ sb.append(str); } context.write(new Text(key.get()), new Text(new String(sb))); } } } public static class WordCountHBaseReducer extends Reducer<Text, Text, Text, Text>{ private Text result = new Text(); public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException{ for(Text val : values){ result.set(val); context.write(key, result); } } } public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { String tableName = "wordcount";//表名称 Configuration conf = HBaseConfiguration.create();//实例化Configuration conf.set("hbase.zookeeper.quorum", "header-2,core-1,core-2"); conf.set("hbase.zookeeper.property.clientPort", "2181"); conf.set("hbase.master", "header-1:60000"); Job job = new Job(conf, "import from hbase to hdfs"); job.setJarByClass(MapReduceReaderHbaseDriver.class); job.setReducerClass(WordCountHBaseReducer.class); //配置读取hbase的相关操作 TableMapReduceUtil.initTableMapperJob(tableName, new Scan(), WordCountHBaseMapper.class, Text.class, Text.class, job, false); //输出路径 FileOutputFormat.setOutputPath(job, new Path("hdfs://header-1:9000/user/out")); System.out.println(job.waitForCompletion(true) ? 0 : 1); } }