1. 归类:
聚类(clustering):属于非监督学习(unsupervised learning)
无类别标记(class label)
2. 举例:
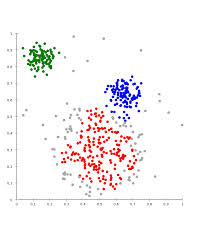
3. Kmeans算法
3.1 clustering中的经典算法,数据挖掘十大经典算法之一
3.2 算法接受参数k;将事先输入的n个数据对象划分为k个类以便使得获得的聚类满足:同一类中对象之间相似度较高,不同类之间对象相似度较小。
3.3 算法思想
以空间中k个点为中心进行聚类,对最靠近他们的对象归类。通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果。
3.4 算法描述
1) 选择适当的c个类的初始中心;
2) 在第k次迭代中,对任意一个样本,求其到c各中心的距离,将该样本划归到距离最近的中心所在的类。
3) 利用均值的方法更新该类的中心值,即通过求当前类所有点的均值来更新c的中心值
4) 对所有的c个聚类中心,如果利用2),3)的迭代更新后,值仍然保持不变,则迭代结束,否则继续迭代。
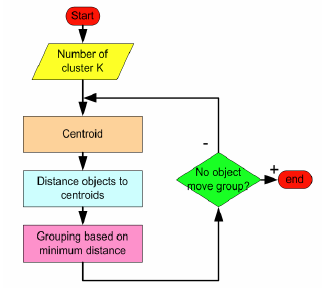
3.5 算法流程
输入:k, data[n]
1) 选择k个初始中心点,例如c[0]=data[0]...c[k-1]=data[k-1]
2) 对于data[0]...data[n],求出分别与c[0]...c[k-1]之间的距离,将其划分到距离最近的中心所属的类,如data[j] 与c[i]距离最近,data[j]就标记为i。
3) 采用均值思想更新类中心,如对于所有标记为i的点,重新计算c[i]={所有标记为i的data[i]之和}/标记为i的个数。
4) 重复2) 3),直到所有的类中心值的变化小于给定阈值。
流程图:
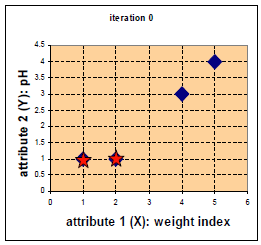
举例:

每个实例对应坐标:
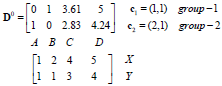 距离
距离
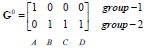 归类
归类
 中心点
中心点
 更新后中心点
更新后中心点
 距离
距离
 归类
归类
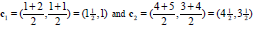 更新中心点
更新中心点
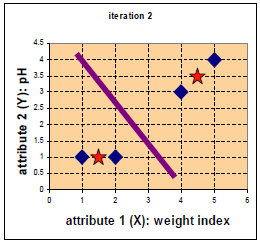 更新后中心点
更新后中心点
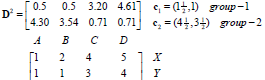 距离
距离
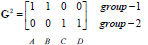 归类
归类
停止!!!

3.5 算法优缺点
优点:速度快、简单
缺点:最终结果和初始点选择有关,容易陷入局部最优,需要知道k值。
# -*- coding:utf-8 -*-
import numpy as np
def kmeans(x, k, maxIt):
numPoints, numDim = x.shape
dataSet = np.zeros((numPoints, numDim + 1))
dataSet[:, : -1] = x #dataSet所有行,从第一列到倒数第二列都等于x
#随机选取中心点 所有数据点 随机选k行
centrods = dataSet[np.random.randint(numPoints, size = k), :]
#中心点的最后一列初始化值(类标签):1到k
centrods[:, -1] = range(1, k+1)
iterations = 0
oldCentrods = None
while not shouldStop(oldCentrods, centrods, iterations, maxIt):
print("iteration:
", iterations)
print("dataSet:
", dataSet)
print("centroids:
", centrods)
#为什么用copy而不是= 因为后面会做修改 oldCentrods和centrods是两部分内容
oldCentrods = np.copy(centrods)
iterations += 1
#更新类标签
updateLabels(dataSet, centrods)
#更新中心点
centrods = getCentroids(dataSet, k)
return dataSet
def shouldStop(oldCentroids, centroids, iterations, maxIt):
if iterations > maxIt:
return True
return np.array_equal(oldCentroids, centroids)
def updateLabels(dataSet, centroids):
numPoints, numDim = dataSet.shape
for i in range(0, numPoints):
dataSet[i, -1] = getLabelFromCosestCentroid(dataSet[i, : -1], centroids)
def getLabelFromCosestCentroid(dataSetRow, centroids):
label = centroids[0, -1]#初始化本条数据类标签为第一个中心点的类标签
minDis = np.linalg.norm(dataSetRow - centroids[0, : -1]) #调用内嵌的方法算距离 一直在更新
for i in range(1, centroids.shape[0]):#求与每个中心点之间的距离
dis = np.linalg.norm(dataSetRow - centroids[i, : -1])
if dis < minDis:
minDis = dis
label = centroids[i, -1]
print("minDist:", minDis)
return label
#更新中心点
def getCentroids(dataSet, k):
result = np.zeros((k, dataSet.shape[1]))
for i in range(1, k + 1):
oneCluster = dataSet[dataSet[:, -1] == i, : -1]#取出标记为i的数据(除最后一列)
result[i - 1, : -1] = np.mean(oneCluster, axis=0)
result[i - 1, -1] = i
return result
x1 = np.array([1, 1])
x2 = np.array([2, 1])
x3 = np.array([4, 3])
x4 = np.array([5, 4])
testX = np.vstack((x1,x2,x3,x4))
result = kmeans(testX, 2 ,10)
print("result:" ,result)