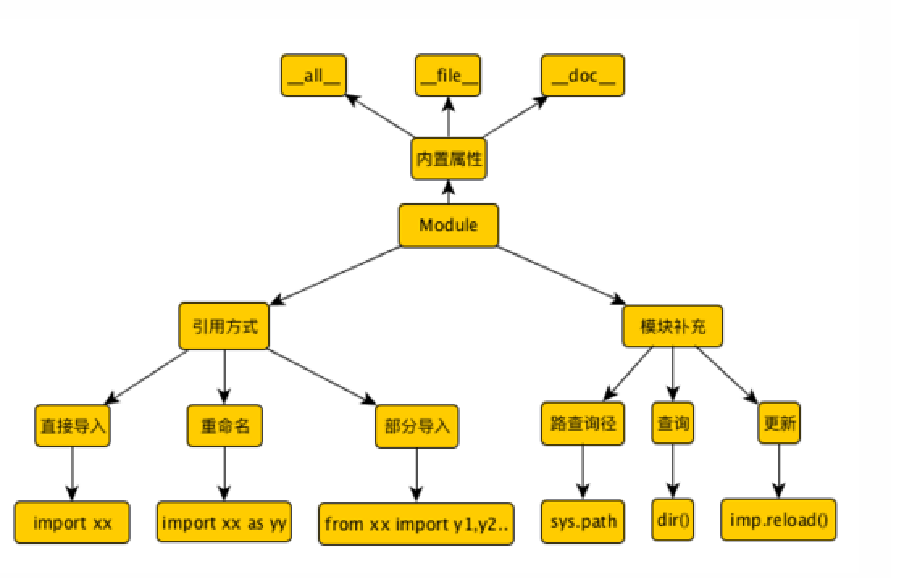
一、模块简介
在实际开发中我们不可能不用到系统的标准模块,或第三方模块。 如果想实现与时间有关的功能,就需要调用系统的time模块。如果想实现与文件和文件夹有关的操作,就需要要用到os模块。
每一个 Python 脚本文件都可以被当成是一个模块。模块以磁盘文件的形式存在。当一个模块变得过大,并且驱动了太多功能的话,就应该考虑拆一些代码出来另外建一个模块。模块里的代码可以是一段直接执行的脚本,也可以是一堆类似库函数的代码,从而可以被别的模块导 入(import)调用。模块可以包含直接运行的代码块、类定义、 函数定义或这几者的组合。
推荐所有的模块在Python模块的开头部分导入。而且最好按照这样的顺序:
Python标准库模块
Python第三方模块
应用程序自定义模块
import关键字
在Python中用关键字import来引入某个模块,比如要导入模块time,就可以在文件最开始的地方用import time来引入
import module1
import module2[
......
import moduleN]
或者:import module1[, module2[,... moduleN]]
在调用模块中的函数时,必须加上模块名调用,因为可能存在多个模块中含有相同名称的函数,此时,如果只是通过函数名来调用,解释器无法知道到底要调用哪个函数。为了避免这样的情况,调用函数时,必须加上模块名.
如:模块名.函数名
from…import
Python的from语句让你从模块中导入一个指定的部分到当前命名空间中。
如:from modname import name1[, name2[, ... nameN]]
要导入模块time的sleep函数,使用如下语句
from time import sleep
使用这种方式导入,不会整个模块导入到当前命名空间,它只会将import的内容导入。
from…import *
导入一个模块的所有内容也可以使用from…import*。
如:from modname import*
扩展import语句(as)
有时候你导入的模块名称已经在你的程序中使用了, 或者你不想使用现有的名称。可以使用一个新的名称替换原始的名称。。
如:import pandas #原始的名称
import pandas as pd #使用as重新命名
'''
import 模块名
导入整个模块
通过模块名.方法名 调用
'''
# import time
# print('start')
# time.sleep(5)
# print('stop')
'''
from 模块名 import 函数名
从指定的模块中导入指定的部分
'''
# from time import sleep
# print('start')
# sleep(5)
# print('stop')
#导入模块中的所有内容
# from math import *
# print(ceil(1.1))#向上取整
# print(floor(1.1))
#给导入的模块取别名
# import math as m
# print(m.ceil(1.2))
# print(m.floor(1.2))
# from math import ceil as c #不建议使用
# print(c(1.2))
二、模块制作
跨目录模块调用
如果调用文件与被调用文件在一个目录下面,则可以非常方便地调用。那么如果被调用的文件与调用文件不在同一目录下的调用
定位模块1
当你导入一个模块,Python解析器对模块位置的搜索顺序是:
1.当前目录
2.如果不在当前目录,Python则搜索在环境变量PYTHONPATH下的每个目录
3.如果都找不到,Python会察看默认路径。UNIX下,默认路径一般为/usr/local/lib/python/
4.模块搜索路径存储在system模块的sys.path变量中。变量里包含当前目录,PYTHONPATH和由安装过程决定的默认目录。
(sys模块用于提供对python解释器的相关操作。)
定位模块2
所以如果当前路径或 PythonPATH中存在与标准module同样的module,则会覆盖标准module。也就是说,如果当前目录下存在xml.py,那么在执行import xml时,导入的是当前目录下的module,而不是系统标准的xml.py。
'''
自定义模块
'''
# import test #引入同级目录中的test模块
# print(test.test_add(2,3))
# from test import test_add
# print(test_add(2,3))
'''
跨模块引入
'''
# import study.test2 #模块名.函数名
# print(study.test2.test2_add(2,3))
# from study import test2
# print(test2.test2_add(2,3))
# from study.test2 import test2_add
# print(test2_add(2,3))
'''
跨模块引入2
'''
# import sys #查看路径变量
# print(sys.path)
#添加目标路径 到当前环境中(重点)
# sys.path.append('..\') #返回上一级目录
# print(sys.path)
# import msg.send
# msg.send.sendMsg()
# from msg import send,recv
# send.sendMsg()
# recv.recvMsg()
# from msg import math #引入自定义的模块
# print(math.ceil(1.2))
# print(math.floor(1.2))
# math.getInfo() #覆盖了标准模块
三、dir()函数与标准模块
dir()函数一个排好序的字符串列表,内容是一个模块里定义过的名字。 返回的列表容纳了在一个模块里定义的所有模块,变量和函数。
查看:dir(list)
标准模块
Python 本身带着一些标准的模块库,可参考 http://www.cnblogs.com/ribavnu/p/4886472.html
有些模块直接被构建在解析器里,这些虽然不是一些语言内置的功能,但是他却能很高效的使用,甚至是系统级调用也没问题。这些组件会根据不同的操作系统进行不同形式的配置,比如 winreg (Windows注册表访问)这个模块就只会提供给 Windows 系统。应该注意到这有一个特别的模块 sys ,它内置在每一个 Python 解析器中。
四、包
包是一种管理 Python 模块命名空间的形式,采用"点模块名称"。比如一个模块的名称是 A.B, 那么他表示一个包 A中的子模块B
目录中只有包含一个叫做__init__.py的文件才会被认作是一个包
在导入包的时候,Python会从sys.path中的目录来寻找这个包中包含的子目录
模块在包里
导入包
现有两个模块功能有些联系,所以将其放到同一个文件夹下,一个文件中的类继承另一个问文件中的类。
使用import文件.模块的方式导入
import recvmsg
recvmsg.add()
使用from文件夹import模块的方式导入
from recvmsg import *
add()
注意:必须包含__init__.py文件,才被认作是一个包
创建__init__.py
目录中只有包含了叫做__init__.py的文件,才能被程序认作是包,模块才能被导入成功。现在我们就在msg文件夹下创建一个__init__.py文件,并且一定要在文件中写入__all__
__init__.py 控制着包的导入行为。如果__init__.py文件为空的话,仅仅是把这个包导入,不会导入包中的模块。__init__.py中的__all__变量,是用来控制from包名import * 时导入的模块。
可以在__init__.py中编写其他内容,在导入时,这些编写的内容就会被执行。
可以在__init__.py中向sys.path添加当前被调用模块路径。
__all__总结
1.编写Python代码(不建议在__init__中写python模块,可以在包中在创建另外的模块来写,尽量保证__init__.py简单)
2.模块中不使用__all__属性,则导入模块内的所有公有属性,方法和类 。 模块中使用__all__属性,则表示只导入__all__中指定的属性,因此,使用__all__可以隐藏不想被import的默认值。 __all__变量是一个由string元素组成的list变量。 它定义了当我们使用
3.from <module> import * 导入某个模块的时候能导出的符号(这里代表变量,函数,类等)。 from <module> import * 默认的行为是从给定的命名空间导出所有的符号(当然下划线开头的变量,方法和类除外)。 需要注意的是 __all__ 只影响到了 from <module> import * 这种导入方式, 对于 from <module> import <member> 导入方式并没有影响,仍然可以从外部导入。
创建__init__.py总结
包将有联系的模块组织在一个,即放到同一个文件夹下,并且在这个文件夹创建一个名字为__init__.py文件,那么这个文件夹就称之为包
有效避免模块名称冲突问题,让应用组织结构更加清晰
imp.reload()简介
默认情况下,模块在第一次被导入之后,其他的导入都不再有效。如果此时在另一个窗口中改变并保存了模块的源代码文件,也无法更新该模块。这样设计原因在于,导入是一个开销很大的操作(导入必须找到文件,将其编译成字节码,并且运行代码),以至于每个文件、每个程序运行不能够重复多于一次。
当一个模块被导入到一个脚本,模块顶层部分的代码只会被执行一次。 因此,如果你想重新执行模块里顶层部分的代码,可以用reload()函数。该函数会重新导入之前导入过的模块。
语法如下: reload(module_name)
'''
dir函数
查看模块信息
'''
# print(dir())
# print(dir(math))
'''
python中的包
目录里面必须含有 __init__.py
'''
#通过import方法 逐个导入模块
# import msg.send
# msg.send.sendMsg()
# import msg.recv
# msg.recv.recvMsg()
#通过from 一次性导入所有的模块
#做一个包一定要创建一个__init__.py 里面__all__指定允许被导入的包
# from msg import *
# send.sendMsg()
# recv.recvMsg()
'''
重新加载
'''
import test
import imp
imp.reload(test)
__init__.py文件
__all__ = ['send','recv']#允许被导入的模块
recv.py
def recvMsg():
print('成功接收消息')
send.py
def sendMsg():
print('消息发送成功')
test.py
def test_add(x,y):
return x + y
print('哈哈你被我骗了')
test2.py
def test2_add(x,y):
return x + y