消息中间件的使用已经越来越广泛,基本上具有一定规模的系统都会用到它,在大数据领域也是个必需品,但为什么使用它呢?一个技术的广泛使用必然有它的道理。
背景与问题
以前一些传统的系统,基本上都是“用户——系统——数据库”一条线,拿下单做例子,用户下单,系统接受并处理请求,把数据存到数据库。
这样的好处就是简单,但随着需求越来越多,用户量越来越大,系统需要承载的压力就越大;如果需要扩展系统,修改代码,牵一发动全身,麻烦滴很。
消息队列可以解决这些问题,它是一个存放消息的队列,生产者往队列推数,消费者从队列取数。
优点
解耦
一个系统一般都有很多个模块,但业务发展起来,系统的体量就跟着变大,就需要多做几个模块,然而每拓展一个模块就要多各种调用。
以一个交易系统为例,当完成一次交易,系统需要通知推荐系统、广告系统等。当多出一个模块,系统就要增加一个调用,从而需要修改代码。
要是你觉得改改代码不麻烦,可是改完,后面有一个模块出问题了咋办,一点一点排查,改错地方了还影响到了其他模块。
如果增加消息中间件,各个模块只需要完成各自的工作,然后将消息发到消息队列,由其他模块去取或者消息队列推送,就可以解决耦合的问题了。
异步
传统系统的话,一条路走到底,比如购买商品,完了扣除优惠券,再给你积点分。这每个流程可能就花一点时间,但合起来就很久了。
加上消息队列,我直接完成我的工作,再给队列,队列再通知其他模块,这不仅省事儿,还减少了不必要的时间浪费。
削峰
还是以传统系统为例,当并发量大的时候直接怼到数据库,数据库承受的压力得多大呀这是。欸,那就加个消息队列,把请求扔到消息队列,慢慢处理
缺点
技术嘛,总是有好有坏,刚才说了它的优点,现在简单唠唠它的缺点。
首先,降低了系统的可用性,好好的一个系统,加一个中间件,如果它挂了,后面不得凉凉。
为了防止它挂掉或者挂掉了修复它,是不是得维护?是不是增加了运维成本?
不仅如此,还要考虑数据一致性问题,以及重复消费的问题,还要保证消息的可靠传输。要考虑的东西有多少,系统的复杂性就有多高。
消费模式
消息中间件一般有两种消费模式,一种是点对点模式,一种是发布订阅模式。
点对点是一种一对一的模式,一般消息只由一个消费者消费,导致消息没法复用;
发布订阅模式是一种常见的模式。消费者订阅,当有消息来的时候通知消费者。这种模式也分为两种情况,一种是由消息队列推送,类似公众号订阅一样,只要消费者订阅了,消息一来就推给订阅了的消费者。
但是这种方法也有缺点,因为消费者的处理速度不一样,有快有慢,容易出现问题。比如消息队列推送的速度为100M/s,消费者A处理速度为10M/s,消费者B处理速度为500M/s,这时候A就崩了,对于B来说,又造成资源浪费。
所以由消费者主动拉取的方式诞生了,由消费者主动拉数据,解决了上面的问题,但技术有优点的同时,一般都存在缺点。由于消费者要主动拉取,需要维护一个长轮洵去询问队列,但当遇到长时间没有消息的情况,就造成了资源浪费。
本文的主角 Kafka 是基于拉取的发布订阅模式。
讲了这么多,是时候请上主角,有请 Kafka 登场!
Kafka 的基础架构
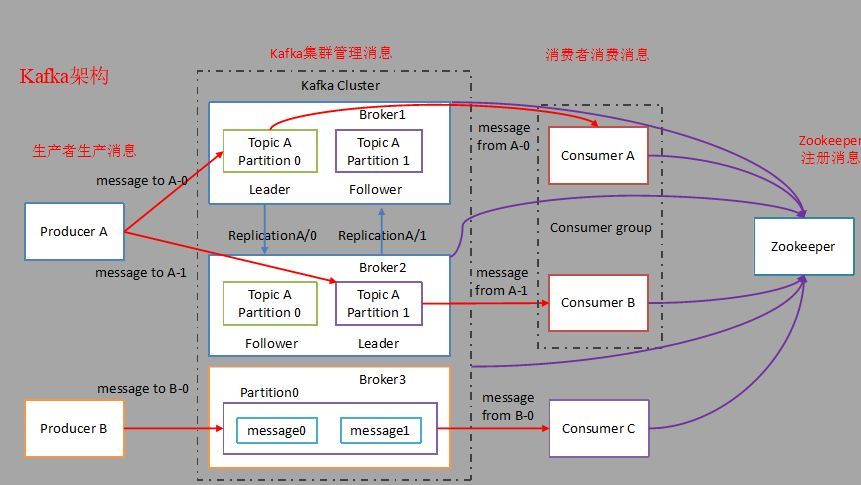
Producer:生产者,发布消息的对象,将消息推到 Kafka 集群
Consumer:消费者,消费消息的对象
Consumer Group:消费者组,Kafka 中可以将多个 Consumer 分为一个组,从整体上可以将它看作是一个Consumer
Broker:一台 Kafka 服务器就是一个 Broker,多个 Broker 组成一个 Cluster
Topic:消息的主题,可以理解为一个消息队列
Partition:分区,一个 Topic 可以分为多个 Partition,这样的好处是负载均衡;同时,一个 Partition 可以有多个副本,提高可靠性。对于 Consumer Group 来说,一个消费者组中的消费者只能订阅同一个 Topic 的不同分区,可以提高效率,又避免重复消费。
Leader & Follower:对于同一个 Partition 而言,消费者只读取 Leader 的消息,而不会读取 Follower 的消息,Follower 是 Leader 的副本,在 Leader 挂掉的时候 Follower 可成为 Leader
Zookeeper: Kafka 是基于 zk 的,用于集群管理
为什么 Kafka 要这样设计
如果消息中间件只有一台机,哪天突然宕机了,整个系统就崩了。因此需要整一个集群,搞多台服务器,所以我们搞几个 Broker。
然后生产者准备发送消息了,如果正巧所有的消息都随机地发到其中某一台机器上,流量全上去了,生产者消费者都来找他,看着其他机器都在摸鱼,它突然不干了。
于是要合理分配工作,整出了 Partition,每个 Topic 对应每个生产者和消费者,同一个 Topic 又分成多个分区,分别在不同的 Broker,分担了单台节点的压力。
不过现在又有一个问题,如果一台 Broker 宕机,该节点上的分区数据也没了。为了防止单节点故障造成数据丢失,每个分区存几个副本保存在其它 Broker。
但消费者只能访问其中一个分区,不然会造成重复消费的现象,所以要区分好 Leader 和 Follower,并使消费者只能访问 Leader,而 Follower 需要在 Leader 发生故障的时候成为新的 Leader。