概述
本文主要是基于flink不同版本之间的checkpoint机制进行阐述,主要是对比1.11之后和之前的差异,使得可以针对不同的场景使用不同的checkpoint方式。
什么是checkpoint
checkpoint是flink中的一种容错机制,使得任务失败的时候可以进行重启而不丢失之前的一些信息(需要数据源支持重发机制)。
checkpoint方式
网上有很多针对checkpoint的讲解,我这里不再阐述,主要是针对几种checkpoint方式进行简单说明,使得更容易理解。
举栗:我们现在读取kafka的数据,然后做map转换,map中通过状态存储流经的条数。黄色的代表kafka的分区,蓝色代表我们flink的map的subtask,绿色的代表外部状态存储。
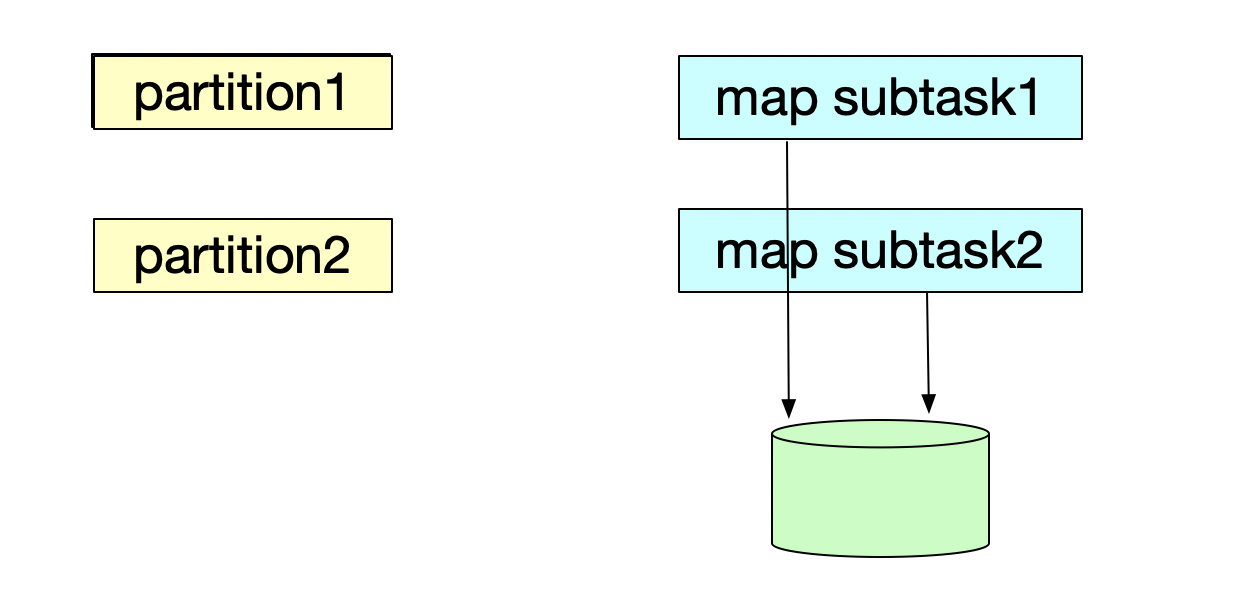
At least-once
我理解是至少计算一次语义,举例说明就是当我们的任务当前消费到kafka的offset,partition1是1200,partition2是1500,这时候flink会把消费的kafka的每个partition的offset信息存储到快照中,然后flink中的CheckpointCoordinator会向每个source算子中定期插入一个叫barrier的东西,然后数据往下游处理,当map的某个subtask收到上游的一个barrier的时候,不会阻塞收到该barrier的channel(比如说是partition2来的),而是继续处理该channel中的数据,也就是继续会像map的状态中计数,直到上游所有的barrier到齐之后触发快照操作,快照存储在本地内存中,这时其实我们的kafka的offset记录的是1500,但处理到offset已经大于1500,可能是1600,然后直到sink阶段做完快照,所有的算子通知CheckpointCoordinator快照成功生成,CheckpointCoordinator会像所有算子发送checkpoint成功的信息,当触发下次checkpoint的时候,任务如果失败了,需要从上次成功的checkpoint恢复,kafka的offset是1200和1500,也就是会从这个offset恢复,但是状态是从1200,1600恢复的,所以这个时候其实partition2的数据有100条计算了两次,这就是At least-once语义。
Exactly-once
与At least-once不同的是,当map算子收到上游的一个barrier的时候,会将收到该barrier后面的数据缓存起来,直到其它的barrier到齐做快照,继续将barrier往下游发送,该算子会首先处理缓存的数据,之后在处理上游来的数据,这个时候topic的offset记录的是1200和1500,map中状态存储的也是数据消费到1200和1500offset时的状态,如果下次checkpoint失败了,从这次checkpoint恢复也不会出现重复消费某些条数据的情况,这就是Exactly-once语义。
1.11 之后的exactly-once
在flink1.11之后提供了一种不需要barrier对齐也可以实现exactly-once语义的方式,和1.11之前不一样的是,1.11之前是在所有的barrier收到之后做快照,1.11之后是收到第一个barrier就做快照,很显然这样的话其实有一部分没有消费到,比如partition是1200,partition2是1500,首先收到partition1的barrier,触发快照,这时候还没有收到partition2的barrier,说明我们还没有消费完到1500offset的数据,如果下次checkpoint失败了,从这次checkpoint恢复,这样的话就会导致丢失数据,所以采取的方式就是在收到第一个barrier之后,将后面来的数据无论是该channel还是其它的channel,全部存储到状态中,这样的目的是为了恢复的时候,可以将这部分数据回放到相应的channel中,因为kafka那边只能从记录的offset重发,所以这样也实现了exactly-once语义,这种方式目前只支持exactly-once,不支持at least-once。